هوش تجاری (Business Intelligence)
به اشتراک بگذاریم برای یادگیری، یاد بگیریم برای به اشتراک گذاریهوش تجاری (Business Intelligence)
به اشتراک بگذاریم برای یادگیری، یاد بگیریم برای به اشتراک گذاریمراحل کلی در انجام عملیات داده کاوی
میتوان گفت دادهکاوی هدف اصلی و نهایی سازمانها در بکارگیری از BI است. انجام عمل دادهکاوی علاوه بر تخصص و توانایی فنی بالا و تسلط به کسب و کار مربوطه نیازمند مقدمات دیگری نیز هست و تا فراهم نشدن تمامی این مقدمات امکان پذیر نمیباشد. در ادامه هر یک از این پیش نیازها را بررسی میکنیم.
طراحی و پیاده سازی انبار داده:
بدون وجود انبار دادهای جامع و دقیق نمیتوان به سوی داده کاوی قدم برداشت. پیش از انجام هر نوع عمل کاوش در دادهها ابتدا باید از یکپارچگی، صحت و تجمیع اطلاعات اطمینان حاصل شود. اطلاعات باید واقعی و دارای توالی به روز رسانی مشخص باشند. مراحل پیاده سازی انبار داده در اینجا شرح داده شده است.
بررسی و انتخاب دادهها بر اساس نوع الگوریتم مورد استفاده:
فارغ از اینکه از چه ابزاری برای عملیات داده کاوی استفاده میکنیم، تعداد الگوریتمها، تنوع و مقاصد آنها متفاوت است. از این رو باید بر اساس نوع الگوریتمی که قصد استفاده از آن را داریم اطلاعات را انتخاب نماییم. الگوریتمهای داده کاوی در اینجا شرح داده شده است.
تبدیل دادهها به فرمت و ساختار مورد نیاز الگوریتم:
هر الگوریتم داده کاوی بر اساس نوع خروجی و هدفی که دنبال میکند به فرمت خاص خود نیاز دارد. در این مرحله باید دادههای مورد نیاز الگوریتم را به شکل و قالب قابل قبول برای الگوریتم تبدیل کنیم. انواع دادهای مورد استفاده در Microsoft Data Mining را اینجا مطالعه کنید.
کاوش در داده با استفاده از الگوریتمهای داده کاوی:
در این مرحله کار را به الگوریتم انتخاب شده میسپاریم. الگوریتم بر اساس پارامترها و ورودیهای مشخص شده شروع به کاوش در دادهها میکند و روابط و اطلاعات مورد نیاز جهت رسیدن به دانش را در اختیار ما قرار میدهد.
در این رابطه میتوانید الگوریتم کلاسترینگ و سری زمانی را مطالعه نمایید.
تحلیل و تفسیر نتیجه :
بدیهی است که کسب دانش از دادهها نیازمند تجزیه و تحلیل و تفسیر خروجی مرحله قبل است. رسیدن به نتیجه مطلوب در کنار تلاش تیمی متشکل از افراد فنی و غیر فنی که تسلط کامل برروی اطلاعات و کسب وکار دارند میسر است.
همگام سازی (Synchronize) دو جدول در SSIS
پیشتر مطالبی در مورد روشهای مقایسه رکوردهای دو جدول نوشته بودم. یکی از این روشها استفاده از tablediff است که مطالب مربوط به آن را میتوانید اینجا مشاهده کنید، اما برای انجام آن دو مسئله وجود دارد. اول اینکه پس از ایجاد فایل تغییرات، باید آن فایل را باز کرده و اجرا کنیم و دوم گرفتن خطا توسط SQL در زمان ایجاد مجدد است، چراکه این فایل قبلا ایجاد شده است. البته از چند طریق میتوان این مشکلات را حل کرد.
در این پست قصد دارم به حل این مسئله از طریق ایجاد یک پکیج در SSIS بپردازم.
1- در SSIS یک Package مطابق شکل زیر ایجاد کنید.
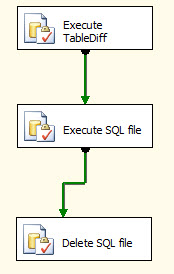
2- قطعه کد زیر را در Execute TableDiff قرار دهید.
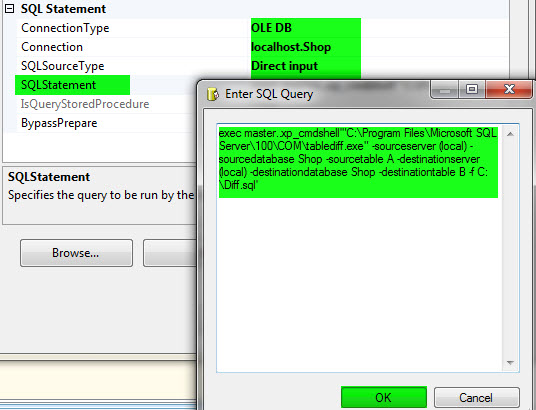
exec master..xp_cmdshell'"C:\Program Files\Microsoft SQL Server\100\COM\tablediff.exe" -sourceserver (local) -sourcedatabase Shop -sourcetable A -destinationserver (local) -destinationdatabase Shop -destinationtable B -f C:\Result.sql'
برای اطلاع از سایر پارامترها و ویژگی های Tablediff به اینجا مراجعه کنید.
همانطور که در مطالب مربوط به tablediff گفتم، با اجرای این کوئری رکوردهای دو جدول با هم مقایسه و نتیجهی آن در فایل Result.sql ذخیره میشود.
3- توسط Execute SQL file فایل SQL ایجاد شده در مرحله قبل را اجرا کنید.
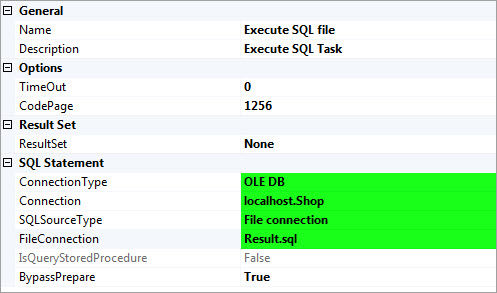
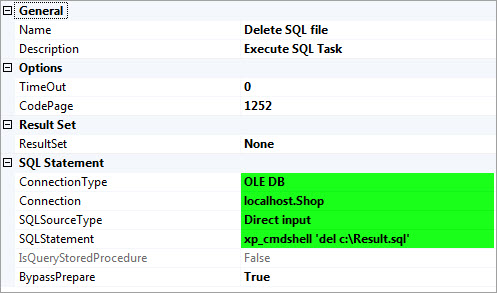
4- برای اینکه در زمان اجرای مجدد پکیج و ایجاد فایل به مشکل بر نخوریم، با استفاده از یک دستور ساده فایل ایجاد شده در مرحله قبل را حذف میکنیم.
xp_cmdshell 'del c:\Result.sql'
کار تمام است! حال هر زمان که اطلاعات موجود در جدول اول تغییر کرد میتوانید پکیج را اجرا کنید و جدول دوم را همانند جدول اول داشته باشید.
SSIS و کاربرد آن در پروژه
شرکت ماکروسافت سرویس SSIS را برای ایجاد راهحلهای مختلف جهت مدیریت و انتقال دادهها فراهم کرده است.
با یک مثال به معرفی بهتر SSIS میپردازم؛ فرض کنید توسط SSAS یک پروژهی بزرگ سازمانی که شامل چندین Cube، Dimension، KPI و ... است، ایجاد کردهاید و از آنجایی که در این پروژه از روش ذخیرهسازی MOLAP استفاده شده، در هر بار به روز رسانی دادهها در انبار داده باید مکعبهای داده و ابعاد نیز پردازش شوند. از طرفی نه درست است و نه منطقی که کاربر نهایی هر روز وارد SSAS شود و Solution را پردازش کند.
بهترین روشی که برای حل این مشکل معرفی میشود، استفاده از SSIS است. در SSIS با ایجاد یک Package و استفاده از کامپننتهای مربوطه این کار به راحتی انجام میشود. کاربرد SSIS تنها برای پردازش Solutionها نیست. در واقع SSIS یک پلتفرم (Platform) سطح بالا برای فراهم کردن راهکارهای مختلف جهت مدیریت و انتقال اطلاعات است. از این سرویس برای کپی کردن یا دانلود فایل، ارسال و دریافت ایمیل، بهروز رسانی انبار داده، پاکسازی و کاوش در دادهها، مدیریت شیءها (Objects) و دادههای SQL استفاده میشود. علاوه بر این SSIS توانایی استخراج (Extract) و تبدیل کردن (Transform) دادهها از فایلهای دادهای XML و منابع داده رابطهای و بارگذاری (Load) در یک یا چند مقصد را دارد.
گرافیکی بودن ابزارها از دیگر مزایای SSIS است. به سادگی میتوان از این ابزارها برای ساخت Package استفاده نمود بدون نیاز به حتی یک خط کد نویسی! البته در صورت نیاز به کد نویسی ابزار و شرایط آن فراهم است.
هر پکیج دارای یک یا چند کامپننت است که میتوانند به تنهایی و یا با ترکیبی از هم اجرا شوند. هر پکیج نیز میتواند به تنهایی یا با هماهنگی با سایر پکیجها اجرا شود.
آشنایی با INTERSECT و EXCEPT
معمولا برای مقایسه رکوردهای دو جدول از کوئریهای پیچیده استفاده میشود. دو دستور INTERSECT و EXCEPT نتایج مقایسه رکوردهای دو کوئری را بدون نمایش رکوردهای تکراری نمایش میدهد.
EXCEPT رکوردهایی که در کوئری اول (سمت چپ) وجود دارد و در کوئری دوم (سمت راست) وجود ندارد را نمایش میدهد.به زبان سادهتر، رکوردهایی که در اولی هست و در دومی نیست.
INTERSECT رکوردهایی که در هر دو کوئری مشترک هستند را نمایش میدهد.
به دو کوئری زیر توجه کنید
USE AdventureWorks; GO SELECT ProductID FROM Production.Product INTERSECT SELECT ProductID FROM Production.WorkOrder ; --Result: 238 Rows (products that have work orders) |
در دو جدول Product و WorkOrder تعداد 238 رکورد وجود دارد که ProductID آنها مشترک است.
USE AdventureWorks; GO SELECT ProductID FROM Production.Product EXCEPT SELECT ProductID FROM Production.WorkOrder ; --Result: 266 Rows (products without work orders) |
تعداد 266 رکورد وجود دارد که ProductID آنها در جدول Product (اولی) وجود دارد و در جدول WorkOrder (دومی) وجود ندارد.
جهت دریافت و نصب بانک اطلاعاتی AdventureWorks به اینجا مراجعه کنید.
منبع:
http://msdn.microsoft.com/en-us/library/ms188055(v=sql.100).aspx
ساخت پارتیشن برای Cube
همانطور که پیشتر گفته شد، سه روش MOLAP، ROLAP و HOLAP برای ذخیرهسازی اطلاعات در Cube وجود دارد.
در روش ذخیره سازی MOLAP، دادههای جدیدی که وارد انبار داده میشوند در صورتی به Cube منتقل میشوند که مجدد پردازش شوند. گاهی ممکن است حجم اطلاعات بسیار زیاد باشد که این مسئله باعث طولانی شدن مدت زمان پردازش میشود. طولانی شدن مدت زمان پردازش علاوه بر حجم زیاد اطلاعات دلیل دیگری نیز دارد و آن پردازش تمامی اطلاعات موجود در انبار داده است. برای رفع این مشکل باید از قابلیت پارتیشن بندی Cube استقاده کنیم. اما باید پارتیشن را طوری طراحی کرد که به صورت داینامیک و بدون دخالت کاربر عمل ایجاد پارتیشن جدید انجام گیرد. به همین منظور در این مقاله به آموزش قدم به قدم و چگونگی ایجاد پارتیشن پویا (Dynamic) میپردازم.
در این آموزش فرض بر وجود دو گروه معیار (Measure Group) با نام های Sales و Order است.
- پس از ایجاد Cube در SSAS به سربرگ Partition رفته و پارتیشنهای ایجاد شده را حذف کنید.
- برروی NewPartition.. مربوط به Sales کلیک کرده و پارتیشن جدیدی با نام Sales_1 ایجاد نمایید.
- کوئری موجود در پارتیشن را مطابق کد زیر قرار دهید.
SELECT * FROM [dbo].[sales] WHERE DDate>='1383/01/01' and DDate<'1383/01/10'
- همین کار را برای Order انجام دهید و در پایان نام آن را Order_1 قرار دهید.
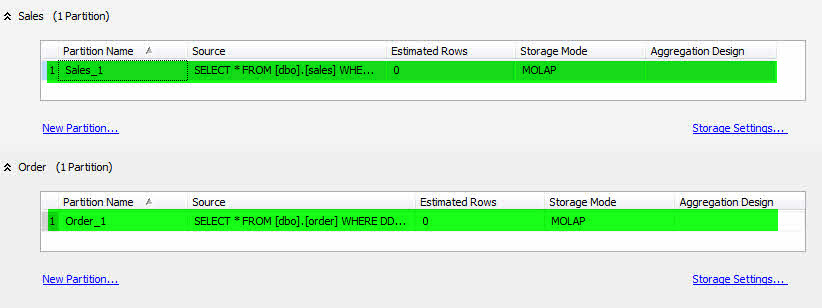
حال Cube را پردازش کرده و از SSAS خارج شوید.
-مطابق تصویر زیر در بر رویMicrosoft Analysis Services Sales_1 راست کلیک کنید و یک ((اسکریپتِ ایجاد)) ساخته و با نام CreatePartition-Sales_1 ذخیره نمایید.
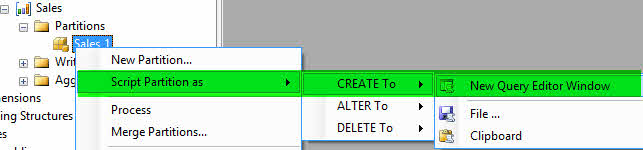
-مجدد بر روی Sales_1 کلیک راست کرده و Process را انتخاب کنید.
-در صفحهی باز شده بر روی Script کلیک کنید تا کد XML مربوط به پردازش نمایش داده شود. کد را با نام ProcessPartition-Sales_1 ذخیره نمایید.
-مراحل بالا را برای Order_1 انجام دهید. از نامهای CreatePartition-Order _1 و ProcessPartition-Order _1 برای ذخیره فایلهای XML استفاده کنید.
مطابق شکل زیر یک جدول با عنوان PartitionsLog ایجاد کنید.
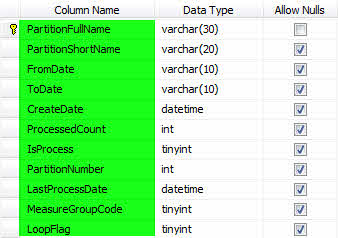
سه رویه زیر را دریافت و ایجاد کنید.
دومین SP برای دریافت
اطلاعات پارتیشنهای قبلی جهت ساخت پارتیشن جدید ایجاد شده است.
سومین SP وظیفه ثبت اطلاعات پارتیشن جدید در PartitionsLog را دارد.
تا به اینجای کار مراحل اولیه آماده سازی شد، از این پس در SSIS به ایجاد یک Package برای ایجاد پارتیشن میپردازیم.
یک پروژهی SSIS با نام Partition ایجاد کرده و مطابق شکل زیر در قسمت Variable متغیرها را تعریف نمایید.
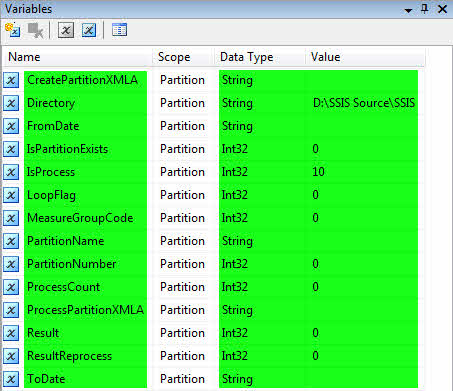
در جدول زیر شرح مختصری از وظیفه متغیرها آمده
|
برای ساخت XMLA جدید از آن استفاده میشود. |
CreatePartitionXMLA |
|
آدرس فایلهای XMLA که پیشتر ساخته شده را در خود دارد. |
Directory |
|
مشخص کننده تاریخ شروع اطلاعات موجود در پارتیشن است. |
FromDate |
|
نشان دهنده وجود داشتن/ نداشتن پارتیشن است. |
IsPartitionExists |
|
نشان دهنده پارتیشن پردازش شده / پارتیشن پردازش نشده است. |
IsProcess |
|
اطلاعات مربوط به تکرار را در خود ذخیره میکند. |
LoopFlag |
|
کد گروه معیار را در خود جای میدهد. |
MeasureGroupCode |
|
نام پارتیشن در این متغیر قرار میگیرد. |
PartitionName |
|
شماره پارتیشن در این متغیر قرار میگیرد. |
PartitionNumber |
|
تعداد دفعات پردازش یک پارتیشن در این متغیر قرار میگیرد. |
ProcessCount |
|
جهت پردازش پارتیشن از این متغیر استفاده میشود. |
ProcessPartitionXMLA |
|
خروجی SP دوم که برای پردازش مجدد استفاده میشود در این متغیر قرار میگیرد. |
Result |
|
نتیجه پردازش مجدد |
ResultReprocess |
|
اطلاعات موجود در Fact تا این تاریخ در پارتیشن ثبت میشود. |
ToDate |
-مطابق شکل زیر 11 عدد Execute SQL Task، یک Analysis Services Processing Task، 2عدد For Loop Container، 4 عدد Analysis Services Execute DDL Task و 4 عدد Script Task به پروژه اضافه کرده و به هم متصل کنید.
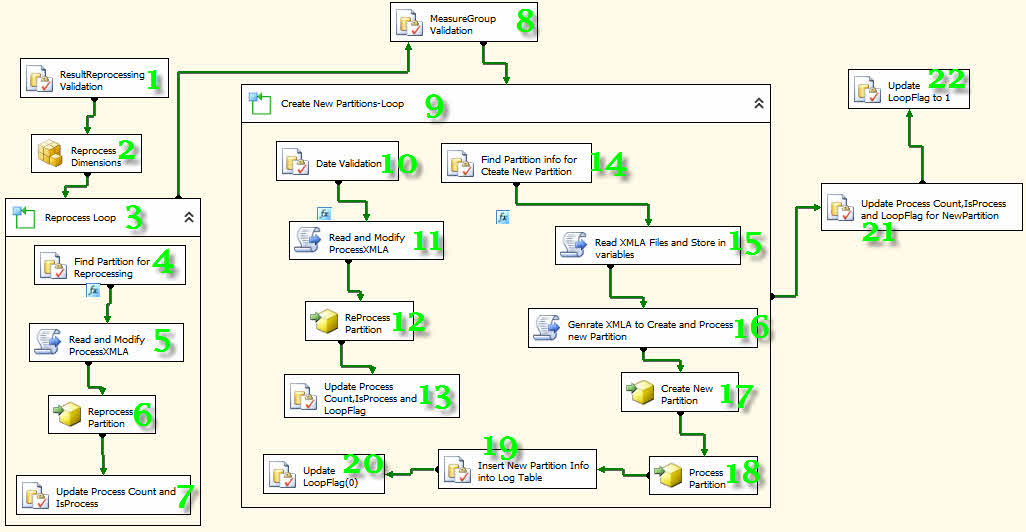
با توجه به شمارههای قرار گرفته بر روی هر کامپننت توضیحاتی میدهم که باید قدم به قدم اجرا شود.
1- رویه Findisprocess را فراخوانی کرده تا اطلاعات پارتیشنهایی که فیلد IsProcess آنها صفر است در متغیرها قرار گیرد.
2- تمامی دایمنشنها را پردازش میکند.
3- برای پردازش مجدد تمامی پارتیشنها، یک حلقه ایجاد میکند و تا زمانی که نتیجه پردازش 1 است به کار خود ادامه میدهد.
4- رویه Findisprocess را فراخوانی کرده تا تمامی اطلاعات مربوط به پارتیشن را دریافت کند.
5- توسط این کامپننت میتوانیم از زبانهای برنامه نویسی C# و VB در پکیج استفاده کنیم. توسط مجموعه کدهای نوشته شده در این قسمت تغییرات مورد نیاز جهت پردازش مجدد اعمال میشوند.
کدهای مربوط به کامپننتهای Script Task شماره 5 را از اینجا دریافت کنید.
6- پارتیشن مورد نظر را پردازش میکند.
7- فیلدهای موجود در PartitionsLog بروزرسانی میشوند.
8- گروه معیارها شناسایی میشوند.
9- از آنجایی که دو گروه معیار داریم، برای ایجاد پارتیشن به یک حلقه نیاز داریم. در این حلقه ابتدا در صورت نیاز آخرین پارتیشنها پردازش میشوند و سپس پارتیشنهای جدید ایجاد میشوند.
10- تمامی اطلاعات مورد نیاز برای پردازش مجدد پارتیشن دریافت میشود.
11- تغییرات مورد نیاز جهت پردازش مجدد اعمال میشوند.
کدهای مربوط به کامپننت Script Task شماره 11 را از اینجا دریافت کنید.
12- پارتیشن مورد نظر را پردازش میکند.
13- فیلدهای موجود در PartitionsLog بروزرسانی میشوند.
14- تمامی اطلاعات مورد نیاز برای ایجاد و پردازش پارتیشن دریافت میشود.
15- فایلهای XMLA ایجاد شده در ابتدای پروژه را بازخوانی و متغیرهای مربوطه را بارگذاری میکند.
کدهای مربوط به کامپننت Script Task شماره 15 را از اینجا دریافت کنید.
16- اطلاعات مورد نیاز برای ایجاد و پردازش پارتیشن را آماده میکند.
کدهای مربوط به کامپننت Script Task شماره 16 را از اینجا دریافت کنید.
17- پارتیشن جدید را ایجاد میکند.
18- پارتیشن ایجاد شده را پردازش میکند.
19- اطلاعات مربوط به پارتیشن جدید توسط رویه InsertNewPartitionInfo ثبت میشود.
20- مقدار فیلد LoopFlag را به صفر تغییر میدهد. دلیل اینکار جلوگیری از تکرار بیدلیل در پردازش پارتیشن است.
21- اطلاعات تکمیلی پارتیشن جدید را بروزرسانی میکند.
22- مقدار فیلد LoopFlag را به یک تغییر میدهد. دلیل اینکار فراهم نمودن شرایط تکرار در پردازش پارتیشن در صورت لزوم است.
کار تمام است! حال میتوانید از Package خود استفاده کنید.
لازم به ذکر است که با کمی کار بیشتر و ایجاد تغییرات جزئی میتوان این پکیج را بهینه کرد.