هوش تجاری (Business Intelligence)
به اشتراک بگذاریم برای یادگیری، یاد بگیریم برای به اشتراک گذاریهوش تجاری (Business Intelligence)
به اشتراک بگذاریم برای یادگیری، یاد بگیریم برای به اشتراک گذاریکاربرد Unary Operator در OLAP
میتوان گفتUnary Operatorاز برای تحلیل بهتر گزارشات مالی استفاده میشود. برای درک بهتر این موضوع به مثال زیر توجه کنید.
فرض کنید در یک Cube مالی نیاز به محاسبه ترازنامه (صورتی که وضع مالی یک موسسه را در یک تاریخ معین نشان می دهد) دارید، اگر در SSAS به صورت معمول بعد حساب (Account Dimension) را تعریف و ارتباط آن را با Cube مورد نظر برقرار کنید نتیجهی بدست آمده در خروجی مطلوب نمیباشد، چراکه در ترازنامه باید بدهیها وداراییها با هم برابر باشند و در نهایت تفاضل آنها صفر شود. در حالیکه در OLAP به صورت پیش فرض از مقادیر Sum گرفته میشود و در نتیجه مقدار بدهی و دارایی با هم جمع میشوند. تصویر زیر خروجی یک Cube مالی را نشان میدهد که در آن بُعد حسابها به صورت عادی و بدون تغییر تعریف شده است.
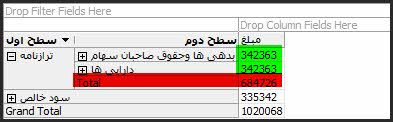
این مشکل با ایجاد تغییرات اندکی در ساختار جدول ایجاد شده در انباره داده و کمک Unary Operator قابل حل است. برای حل این مسئله مراحل زیر را انجام دهید.
۱- ابتدا به انبار داده مورد نظر رفته و به جدول حسابها یک ستون با نام Operator اضافه کنید.
۲- بر اساس نیاز ستون Operator را با علائم ((+ و – و...)) پر کنید.
لازم به ذکر است که این کار باید به طور دقیق و با کمک کارشناس حسابداری انجام گیرد.
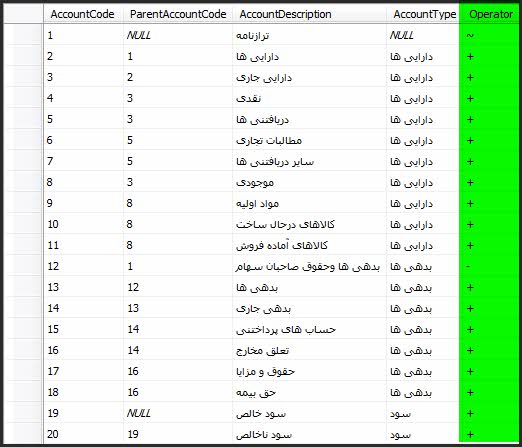
۳- دایمنشن حسابها را مطابق معمول به Cube اضافه کنید.
حال باید تنظیمات مربوط به Unary Operator را انجام دهید.
۴- بر روی دایمنشن ساخته شده راست کلیک کرده و از منوی باز شده گزینهی Add Business Intelligence را انتخاب نمایید. برروی Next کلیک کنید.
۵- در صفحهی Choose Enhancement گزینهی Specify a unary operator را انتخاب و Next کنید.
۶- مطابق شکل زیر در صفحهی Specify a unary operator ستون Operator را که پیشتر به جدول اضافه کردیم را انتخاب کرده و برروی Next کلیک کنید.
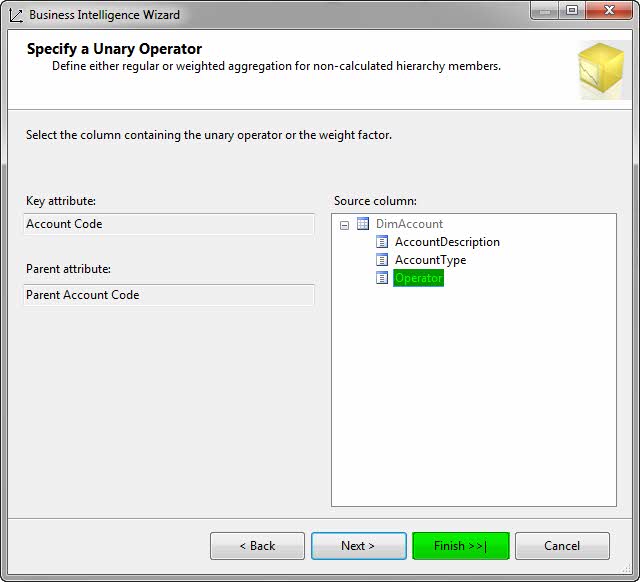
۷- برروی Finish کلیک کنید.
۸- پروژه را مجدد پردازش کنید.
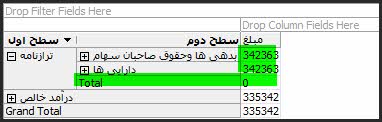
در صورتی که عملگرهای موجود در بعد حساب به درستی تعریف شده باشند و مقادیر موجود در جدول حقایق درست باشند، مقدار کل(Total) برابر صفر خواهد بود.
استفاده از فرمت ساعت به عنوان Measure در Cube
فرض کنید بنا به نیاز سازمان باید اطلاعات مربوط به دورههای آموزشی و تعداد ساعات سپری شده هر یک از پرسنل در کلاسهای آمورشی را در داشبورد نمایش دهید. میدانیم که برای اینکار ابتدا باید جداول Fact و Dimension مربوطه را در انبار داده طراحی و سپس مدل OLAP و Cube مورد نظر را ایجاد کنیم. به نظر میرسد برای اینکار مشکل خاصی وجود نداشته باشد و به سادگی این کار انجام گیرد اما با کمی دقت متوجه میشوید که برای ایجاد معیار (Measure) با فرمت زمان (DateTime) با مشکل مواجه هستید چراکه MSBI به شما اجازه نمیدهد تا از نوع DateTime به عنوان Measure استفاده کنید.
برای حل این مشکل مراحل زیر را انجام دهید.
1- ابتدا به جدول Fact خود فیلدی با نوع Float اضاقه نمایید.
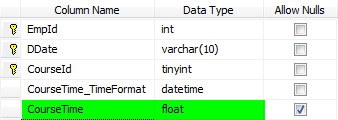
2- از کوئری زیر برای تبدیل اطلاعات فیلد CourseTime_TimeFormat به فرمت Float استفاده کنید.
update [TimeMeasure].[dbo].[FactPersonnelCourse]
set [CourseTime]=convert(float,CourseTime_TimeFormat)
3- به SQL Server Business Intelligence Development Studio رفته و یک پروژهی SSAS جدید با عنوان PersonnelCourse ایجاد کنید.
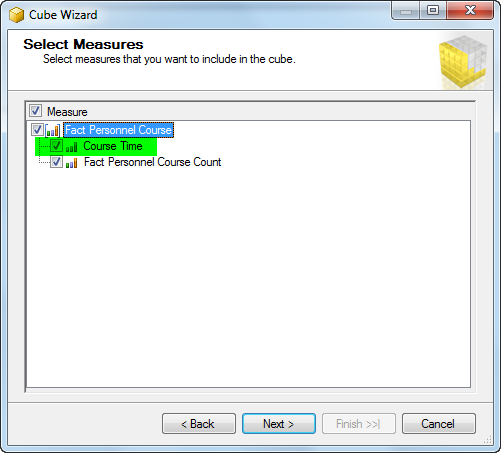
4- همانطور که در شکل زیر مشاهده میکنید، در هنگام انتخاب Measure فیلد CourseTime_TimeFormat نمایش داده نمیشود زیرا نوع آن بعنوان معیار قابل قبول نمیباشد و فقط فیلد CourseTime که نوع اعشاری دارد نمایش داده میشود.
5- پس از اتمام مراحل ساخت Cube پروژه را پردازش کنید و به صفحهی Browser بروید.
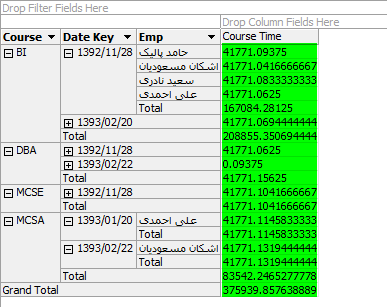
6- معیارها و ابعاد مورد نظر خود را به محل نمایش انتقال دهید. همانطور که در شکل زیر مشاهده میکنید اطلاعات به صورت اعشاری و همانطور که در Fact ذخیره شده است نمایش داده میشود.
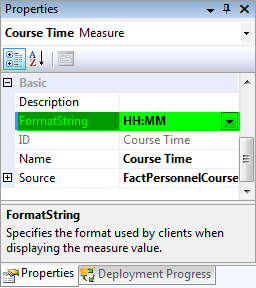
7- برای اینکه اطلاعات نمایش داده شده را به فرمت ساعت مشاهده کنید کافی است خصوصیت Format String معیار Course Time را به HH:MM تغییر دهید.
8- پروژه را مجدد پردازش کنید. همانطور که مشاهده میکنید اطلاعات به فرمت ساعت نمایش داده میشود.
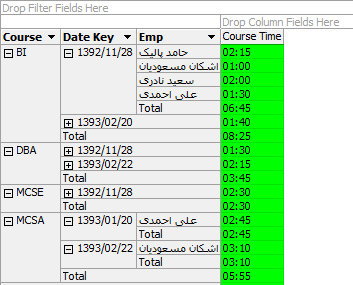
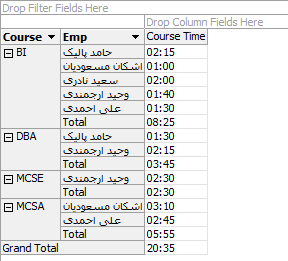
با تغییر ابعاد گزارش دلخواه خود را مشاهده کنید.
تعاریف پایه در SSAS- بخش اول
جدول حقایق (Fact)
این نوع جداول در انبار داده Fact یا جدول حقایق نامیده میشوند که مقادیر معیارها را شامل میشوند. معمولا در جدول حقایق، مقادیر عددی از اطلاعات سازمانها نظیر مقدار فروش و مبلغ فروش و همچنین کلیدهای خارجی (foreign key) برای برقرای ارتباط با ابعاد وجود دارد.
مکعب (Cube)
مکعبهای دادهای هستند که اطلاعات را به صورت چند بُعدی در خود ذخیره میکنند.
معیار (Measure)
به هر یک از مقادیر عددی نظیر مبلغ فروش و مقدار فروش که در Fact وجود دارد Measure گفته میشود.
گروه معیار(Measures Group)
یک یا چند معیار، گروه معیار را تشکیل میدهند. در واقع هر جدول حقایقی که در SSAS مورد استفاده قرار میگیرد یک Measures Group است.
ابعاد (Dimension)
اطلاعات تکمیلی و جزئیات جداول حقایق توسط ابعاد مشخص میشود. جداول ابعاد مجموعهای از ویژگیهای داده است. بعنوان مثال کد استان و نام استان درکنار هم میتواند بعد استان را تشکیل دهند.
ویژگیها (Attribute)
هر جدول بُعد دارای یک یا چند ویژگی است. ویژگیها جزئیات بشتر و بهتری از بُعد را فراهم میکنند. برای مثال کد استان و نام استان ویژگیهای دایمنشن استان را مشخص میکند.
عضوها (Members)
عدد "100" عضوی از ویژگیِ کد استان و "تهران" عضوی از ویژگی نام استان است.
سلسله مراتبها (Hierarchies)
در صورتی که ویژگیهای یک دایمنشن را به طوری مرتب کنید که بتوان به صورت معنادار در سطوح مختلف حرکت نمود، سلسله مراتب ایجاد کردهاید. بعنوان مثال سال، فصل، ماه، هفته و روز، یک سلسله مراتب از ویژگیهای بعد زمان است.
عضو محاسباتی(Calculated Member)
شامل عضوهای جداول ابعاد و یا گروه معیارها است که با استفاده از عبارات محاسباتی بصورت داینامیک اجرا و محاسبه میشود. هر عضو محاسباتی ایجاد شده فقط در Cube ذخیره میشود. بعنوان مثال میتوان یک عضو محاسباتی ایجاد کرد که محتوای دو معیار را با یکدیگر جمع نماید.
شاخصهای ارزیابی عملکرد (KPI)
در واقع معیارهای قابل سنجشی هستند که به صورت نمودارهای عقربهای (Gage) نمایش داده میشوند. اطلاعات مورد نیاز برای نمایش در گیج، طبق فرمولی از پیش مشخص میشود.
Actionها
در واقع Action عملی است که قصد داریم در زمان نیاز انجام شود. به عبارت دیگر Action رویدادی از پیش نوشته شده است که مشخص است در زمان وقوع چه عملی را باید انجام دهد. این عمل باعث هوشمندتر شدن Cubeها میشود. بعنوان مثال فرض کنید کاربر میخواهد با کلیک بر روی نام هر شهر نقشهی آن نمایش داده شود؛ برای حل این مسئله میتوان یک Action ایجاد کرد که پس از انتخاب هر شهر نقشهی آن توسط google mapsنمایش داده شود.
ساخت پارتیشن برای Cube
همانطور که پیشتر گفته شد، سه روش MOLAP، ROLAP و HOLAP برای ذخیرهسازی اطلاعات در Cube وجود دارد.
در روش ذخیره سازی MOLAP، دادههای جدیدی که وارد انبار داده میشوند در صورتی به Cube منتقل میشوند که مجدد پردازش شوند. گاهی ممکن است حجم اطلاعات بسیار زیاد باشد که این مسئله باعث طولانی شدن مدت زمان پردازش میشود. طولانی شدن مدت زمان پردازش علاوه بر حجم زیاد اطلاعات دلیل دیگری نیز دارد و آن پردازش تمامی اطلاعات موجود در انبار داده است. برای رفع این مشکل باید از قابلیت پارتیشن بندی Cube استقاده کنیم. اما باید پارتیشن را طوری طراحی کرد که به صورت داینامیک و بدون دخالت کاربر عمل ایجاد پارتیشن جدید انجام گیرد. به همین منظور در این مقاله به آموزش قدم به قدم و چگونگی ایجاد پارتیشن پویا (Dynamic) میپردازم.
در این آموزش فرض بر وجود دو گروه معیار (Measure Group) با نام های Sales و Order است.
- پس از ایجاد Cube در SSAS به سربرگ Partition رفته و پارتیشنهای ایجاد شده را حذف کنید.
- برروی NewPartition.. مربوط به Sales کلیک کرده و پارتیشن جدیدی با نام Sales_1 ایجاد نمایید.
- کوئری موجود در پارتیشن را مطابق کد زیر قرار دهید.
SELECT * FROM [dbo].[sales] WHERE DDate>='1383/01/01' and DDate<'1383/01/10'
- همین کار را برای Order انجام دهید و در پایان نام آن را Order_1 قرار دهید.
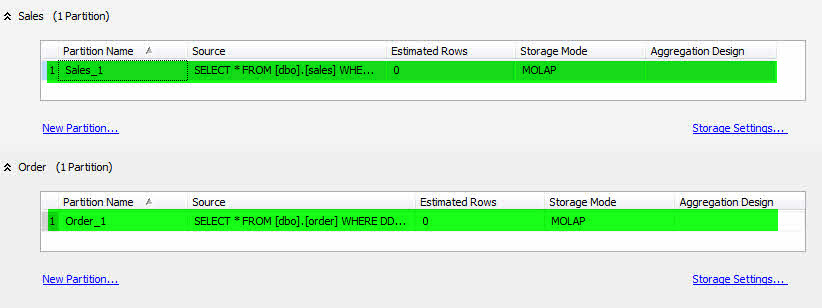
حال Cube را پردازش کرده و از SSAS خارج شوید.
-مطابق تصویر زیر در بر رویMicrosoft Analysis Services Sales_1 راست کلیک کنید و یک ((اسکریپتِ ایجاد)) ساخته و با نام CreatePartition-Sales_1 ذخیره نمایید.
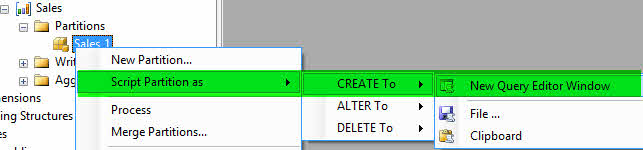
-مجدد بر روی Sales_1 کلیک راست کرده و Process را انتخاب کنید.
-در صفحهی باز شده بر روی Script کلیک کنید تا کد XML مربوط به پردازش نمایش داده شود. کد را با نام ProcessPartition-Sales_1 ذخیره نمایید.
-مراحل بالا را برای Order_1 انجام دهید. از نامهای CreatePartition-Order _1 و ProcessPartition-Order _1 برای ذخیره فایلهای XML استفاده کنید.
مطابق شکل زیر یک جدول با عنوان PartitionsLog ایجاد کنید.
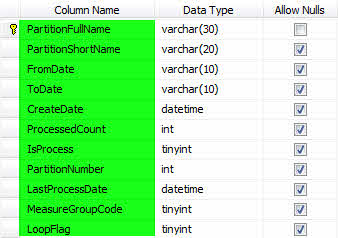
سه رویه زیر را دریافت و ایجاد کنید.
دومین SP برای دریافت
اطلاعات پارتیشنهای قبلی جهت ساخت پارتیشن جدید ایجاد شده است.
سومین SP وظیفه ثبت اطلاعات پارتیشن جدید در PartitionsLog را دارد.
تا به اینجای کار مراحل اولیه آماده سازی شد، از این پس در SSIS به ایجاد یک Package برای ایجاد پارتیشن میپردازیم.
یک پروژهی SSIS با نام Partition ایجاد کرده و مطابق شکل زیر در قسمت Variable متغیرها را تعریف نمایید.
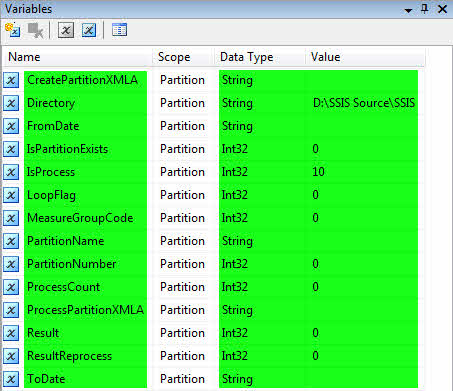
در جدول زیر شرح مختصری از وظیفه متغیرها آمده
|
برای ساخت XMLA جدید از آن استفاده میشود. |
CreatePartitionXMLA |
|
آدرس فایلهای XMLA که پیشتر ساخته شده را در خود دارد. |
Directory |
|
مشخص کننده تاریخ شروع اطلاعات موجود در پارتیشن است. |
FromDate |
|
نشان دهنده وجود داشتن/ نداشتن پارتیشن است. |
IsPartitionExists |
|
نشان دهنده پارتیشن پردازش شده / پارتیشن پردازش نشده است. |
IsProcess |
|
اطلاعات مربوط به تکرار را در خود ذخیره میکند. |
LoopFlag |
|
کد گروه معیار را در خود جای میدهد. |
MeasureGroupCode |
|
نام پارتیشن در این متغیر قرار میگیرد. |
PartitionName |
|
شماره پارتیشن در این متغیر قرار میگیرد. |
PartitionNumber |
|
تعداد دفعات پردازش یک پارتیشن در این متغیر قرار میگیرد. |
ProcessCount |
|
جهت پردازش پارتیشن از این متغیر استفاده میشود. |
ProcessPartitionXMLA |
|
خروجی SP دوم که برای پردازش مجدد استفاده میشود در این متغیر قرار میگیرد. |
Result |
|
نتیجه پردازش مجدد |
ResultReprocess |
|
اطلاعات موجود در Fact تا این تاریخ در پارتیشن ثبت میشود. |
ToDate |
-مطابق شکل زیر 11 عدد Execute SQL Task، یک Analysis Services Processing Task، 2عدد For Loop Container، 4 عدد Analysis Services Execute DDL Task و 4 عدد Script Task به پروژه اضافه کرده و به هم متصل کنید.
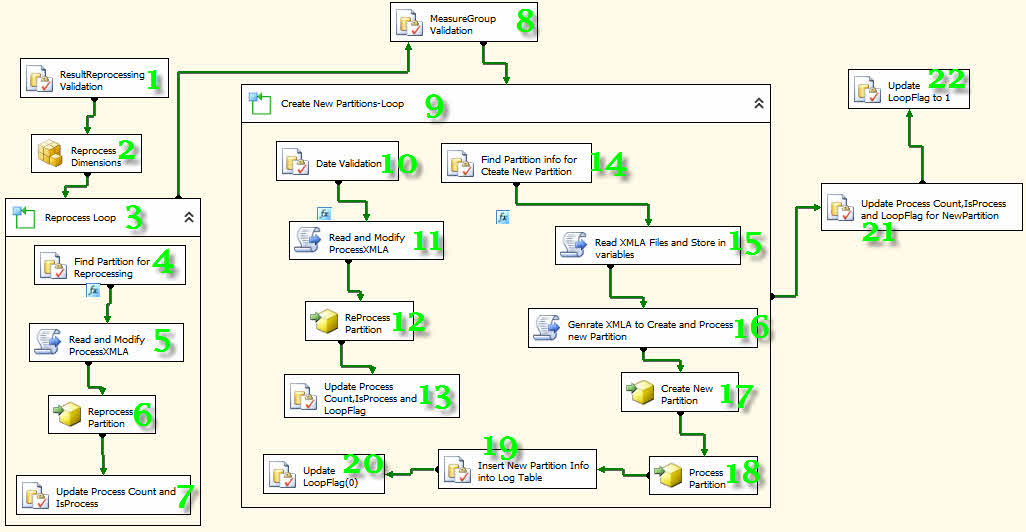
با توجه به شمارههای قرار گرفته بر روی هر کامپننت توضیحاتی میدهم که باید قدم به قدم اجرا شود.
1- رویه Findisprocess را فراخوانی کرده تا اطلاعات پارتیشنهایی که فیلد IsProcess آنها صفر است در متغیرها قرار گیرد.
2- تمامی دایمنشنها را پردازش میکند.
3- برای پردازش مجدد تمامی پارتیشنها، یک حلقه ایجاد میکند و تا زمانی که نتیجه پردازش 1 است به کار خود ادامه میدهد.
4- رویه Findisprocess را فراخوانی کرده تا تمامی اطلاعات مربوط به پارتیشن را دریافت کند.
5- توسط این کامپننت میتوانیم از زبانهای برنامه نویسی C# و VB در پکیج استفاده کنیم. توسط مجموعه کدهای نوشته شده در این قسمت تغییرات مورد نیاز جهت پردازش مجدد اعمال میشوند.
کدهای مربوط به کامپننتهای Script Task شماره 5 را از اینجا دریافت کنید.
6- پارتیشن مورد نظر را پردازش میکند.
7- فیلدهای موجود در PartitionsLog بروزرسانی میشوند.
8- گروه معیارها شناسایی میشوند.
9- از آنجایی که دو گروه معیار داریم، برای ایجاد پارتیشن به یک حلقه نیاز داریم. در این حلقه ابتدا در صورت نیاز آخرین پارتیشنها پردازش میشوند و سپس پارتیشنهای جدید ایجاد میشوند.
10- تمامی اطلاعات مورد نیاز برای پردازش مجدد پارتیشن دریافت میشود.
11- تغییرات مورد نیاز جهت پردازش مجدد اعمال میشوند.
کدهای مربوط به کامپننت Script Task شماره 11 را از اینجا دریافت کنید.
12- پارتیشن مورد نظر را پردازش میکند.
13- فیلدهای موجود در PartitionsLog بروزرسانی میشوند.
14- تمامی اطلاعات مورد نیاز برای ایجاد و پردازش پارتیشن دریافت میشود.
15- فایلهای XMLA ایجاد شده در ابتدای پروژه را بازخوانی و متغیرهای مربوطه را بارگذاری میکند.
کدهای مربوط به کامپننت Script Task شماره 15 را از اینجا دریافت کنید.
16- اطلاعات مورد نیاز برای ایجاد و پردازش پارتیشن را آماده میکند.
کدهای مربوط به کامپننت Script Task شماره 16 را از اینجا دریافت کنید.
17- پارتیشن جدید را ایجاد میکند.
18- پارتیشن ایجاد شده را پردازش میکند.
19- اطلاعات مربوط به پارتیشن جدید توسط رویه InsertNewPartitionInfo ثبت میشود.
20- مقدار فیلد LoopFlag را به صفر تغییر میدهد. دلیل اینکار جلوگیری از تکرار بیدلیل در پردازش پارتیشن است.
21- اطلاعات تکمیلی پارتیشن جدید را بروزرسانی میکند.
22- مقدار فیلد LoopFlag را به یک تغییر میدهد. دلیل اینکار فراهم نمودن شرایط تکرار در پردازش پارتیشن در صورت لزوم است.
کار تمام است! حال میتوانید از Package خود استفاده کنید.
لازم به ذکر است که با کمی کار بیشتر و ایجاد تغییرات جزئی میتوان این پکیج را بهینه کرد.