هوش تجاری (Business Intelligence)
به اشتراک بگذاریم برای یادگیری، یاد بگیریم برای به اشتراک گذاریهوش تجاری (Business Intelligence)
به اشتراک بگذاریم برای یادگیری، یاد بگیریم برای به اشتراک گذاریRunning Total
مساله:
جدولی در یک دیتابیس بانکی وجود دارد که اطلاعات تراکنش های مشتریان بانک در آن ذخیره می شود. به گزارشی نیاز داریم که لیست تراکنش های مشتریان به همراه موجودی حساب مشتری را پس از هر تراکنش نمایش دهد.

تصویر 1
راه حل:
تکنیکی به نام Running Total وجود دارد که از آن برای محاسبه سرجمع مقادیر یک ستون از اولین سطر تا سطر جاری استفاده می شود.
استفاده از این تکنیک یکی از بهترین راه کارهای سیستم های مالی، انبارداری و ... می باشد. روش های متفاوتی برای استفاده از تکنیک Running Total وجود دارد که در این مقاله با روش های Sub Query، Join و Window Function به صورت Set Based بررسی می شود.
کوئری های این تمرین برروی جدولی شامل تراکنش های بانکی انجام میشود.
ستون UserID شناسه کاربری، ستون TransactionID شناسه تراکنش و ستونQuantity مبلغ تراکنش انجام شده را در خود ذخیره می کنند. این جدول دارای اطلاعات تراکنش های دو کاربر با شناسه های 1 و 2 است که هر کدام تعداد 10 تراکنش داشته اند.

تصویر 2
دیتابیسی با نام Test (یا هر اسم دلخواه دیگر) ساخته و کد زیر را اجرا کرده تا جدول مورد نظر ساخته شود.
- USE Test;--DataBase Name
- IF OBJECT_ID('dbo.TransactTable', 'U') IS NOT NULL DROP TABLE dbo.TransactTable;
- CREATE TABLE dbo.TransactTable
- (
- UserID INT NOT NULL
- , TransactionID INT NOT NULL
- , Quantity INT NULL
- , CONSTRAINT PK_TransactTable PRIMARY KEY CLUSTERED
- (
- UserID ASC
- , TransactionID ASC
- )
- );
- INSERT INTO dbo.TransactTable (UserID, TransactionID, Quantity) VALUES
- (1, 1, 50),( 2, -7),(1, 3, 10),(1, 4, 3), (1, 5, -2),(1, 6, 3),(1, 7, -1)
- ,(1, 8, 17),(1, 9, -6),(1, 10, 1),(2, 1, 10),(2, 2, 5),(2, 3, 4),(2, 4, 7),
- (2, 5, -9),(2, 6, 90),(2, 7, -10),(2, 8, -5),(2, 9, -7),(2, 10, -50);
کد ساخت جدول
Sub Query:
در این روش کوئری درونی(کوئریی که خروجی آن بوسیله کوئری دیگر استفاده می شود) UserIDهای برابر با UserIDهای کوئری بیرونی(کوئریی که از خروجی کوئری درونی استفاده می کند) و TransactionIDهای کوچکتر از TransactionIDهای کوئری بیرونی را فیلتر کرده، سپس مجموع فیلدهای ستون Quantity را محاسبه می کند و در ستونی به نام Balance نمایش می دهد. این عملیات به ازای هر یک از رکوردهای کوئری بیرونی، یک بار انجام می شود.
- SELECT UserID
- , TransactionID
- , Quantity
- , (
- SELECT SUM(T2.Quantity)
- FROM dbo.TransactTable AS T2
- WHERE T2.TransactionID = T1.TransactionID
- AND
- T2.TransactionID <= T1.TransactionID
- ) AS Balance
- FROM dbo.TransactTable AS T1;
کوئری اجرای Running Total به وسیله Sub Query
Join:
انجام Running Total به وسیله Join مانند روش Sub Query می باشد. در این روش جدول TransactTable با خودش Join زده می شود و شرط Join آن UserIDهای برابر و TransactionIDهای بزرگتر مساوی جدول اول از TransactionIDهای جدول دوم می باشد. حاصل جوین جدول TransactTable با خودش بر اساس شرط های گفته شده، به ازای هر UserID و TransactionID جدول اول، TransactionIDهای کوچکتر مساوی آن UserID تکرار می شود. سپس سرجمع ستون Quantity محاسبه شده و بر اساس ستون های UserID و TransactionID دسته بندی(GROUP BY) می شود.
- SELECT T1.UserID
- , T1.TransactionID
- , T1.Quantity
- , SUM(T2.Quantity) AS Balance
- FROM dbo.TransactTable AS T1
- INNER JOIN dbo.TransactTable AS T2
- ON T2.UserID = T1.UserID
- AND
- T2.TransactionID <= T1.TransactionID
- GROUP BY T1.UserID
- , T1.TransactionID
- , T1.Quantity;
کوئری اجرای Running Total به وسیله Join
Window Function:
با آمدن Window Function به SQL، پیاده سازی Running Total بسیار آسان تر و کم هزینه تر شد. در این روش ستون Quantity را در تابع SUM قرار داده و در OVER، پارتیشن(PARTITION BY) را UserID قرار داده و ترتیب(ORDER BY) را بر اساس TransactionID اعمال میکنیم. محاسبه سرجمع، از اولین رکورد (UNBOUNDED PRECEDING) هر پارتیشن تا سطر جاری(CURRENT ROW) که سرجمع در حال درج در ستون Balance است، انجام می شود.
- SELECT UserID
- , TransactionID
- , Quantity
- , SUM(Quantity) OVER(PARTITION BY UserID ORDER BY TransactionID
- ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS Balance
- FROM dbo.TransactTable ;
کوئری اجرای Running Total به وسیله Window Function
مقایسه Execution Planها:
در جدولی که کوئری های فوق بر روی آن اجرا شده است، ستون های UserID و TransactionID کلید اصلی می باشند.

لازم به ذکر است که هزینه اجرای کوئری های فوق، می تواند با افزایش تعداد تراکنش ها نسبت به تعداد کاربران و یا بالعکس، متغیر باشد.
منبع: برگرفته از کتاب Microsoft SQL Server 2012 High-Performance T-SQL Using Window Functions نوشته Itzik Ben-Gan
CAP Theorem
سیستمهای توزیع شده و تئوری CAP
اطلاعات و منابع زیادی در خصوص مزایای استفاده از سیستمهای توزیع شده وجود دارد اما کمتر به معایب آن پرداخته شده است.
به طور خلاصه، استفاده از دو یا چند سرور جهت استفاده همزمان از یک برنامه به طوری که کاربر نهایی متوجه تغییرات و نحوه ذخیره سازی اطلاعات نشود، سیستم توزیع شده گفته میشود. برنامه ها در سیستمهای توزیع شده از منابع مختلف غیر اشتراکی استفاده میکنند و هر سیستم (سرور) منابع خود را کنترل میکند.
تئوری CAP :
در علوم کامپیوتر و به طور خاص در سیستمهای توزیع شده، تئوری وجود دارد به نام تئوری CAP (که با نام تئوری Brewer هم شناخته می شود) که بر اساس آن برای یک سیستم توزیع شده برآوردن هر سه مورد زیر به طور همزمان غیر ممکن خواهد بود:
Consistency: تمامی گرهها در یک زمان خاص دادههای مشابه دریافت کنند
Availability: دسترس پذیری درخواستها برای همه گرهها
Partition tolerance: از دسترس خارج شدن سامانه در هنگام شکست شبکه
قضیه CAP بیانگر این موضوع است که در سیستمهای توزیع شده شما فقط امکان فراهم کردن دو گزینه از سه گزینه Consistency و Availability و Partition tolerance را خواهید داشت و گزینه باقیمانده، فدای گزینه های دیگر خواهد شد.
هنگامی که Availability و Partition tolerance را انتخاب میکنیم، به معنی آن است که هر درخواستی، پاسخی دریافت خواهد کرد. این پاسخ تا جای ممکن شامل جدیدترین اطلاعات خواهد بود ولی این امکان وجود دارد که قدیمی باشد. از طرف دیگر درج اطلاعات ممکن است که در لحظه امکان نداشته باشد، ولی سیستم به کار خود ادامه میدهد و در نهایت به ثبات خواهد رسید. این انتخاب برای کارهایی که در دسترس بودن سیستم و سرعت آن، نسبت به ثبات و دوام اطلاعات، اولویت بالاتری دارد مناسب میباشد.
موقعی که Consistency و Partition tolerance را انتخاب می کنیم، به معنی آن است که هر درخواستی حتما باید آخرین نسخه از اطلاعات را به عنوان پاسخ دریافت نماید. همچنین اگر دو درخواست یکسان از دو مکان مختلف به سیستم ارسال شود، سیستم باید به هر دو درخواست کننده جواب یکسانی بدهد. در این حالت، با افزایش Consistency زمان تاخیر افزایش، و سرعت پاسخ دهی کاهش می یابد.
پایگاه دادههای رابطهای به دلیل ماهیت و پشتیبانی کردن از ACID (مجموعه خصوصیات دیتابیسهای تراکنشی)، گزینش CA را انجام میدهند.


حذف سطرهای تکراری یک جدول، بوسیله SSIS Sort Transformation
در SQL Server برای حذف رکوردهای تکراری یک جدول، راه های متعددی وجود دارد که در این پست با استفاده از سرویس SSIS این کار را به راحتی انجام خواهیم داد.
در SSIS وقتی نیاز به مرتب سازی جدول پیدا می کنیم، میتوانیم از کامپوننتی به اسم Sort استفاده کنیم که مانند دستور Order By عمل میکند و میتواند به صورت صعودی و نزولی سطرها را مرتب کند.
ابتدا یک پروژه SSIS ساخته ، سپس در قسمت Solution Explorer روی Connection Managers کلیک راست کرده و گزینه New Connection Manager را انتخاب می کنیم.
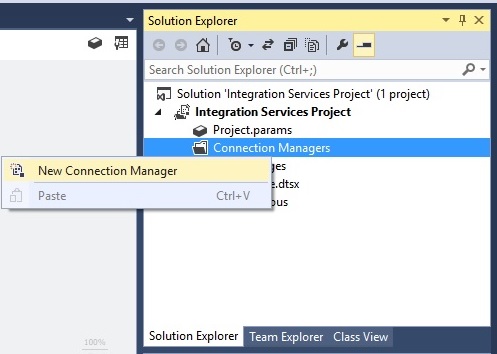
پنجره ای باز میشود به اسم Add SSIS Connection Manager، که در این مثال نوع OLEDB را انتخاب و سپس دکمه Add را میزنیم.
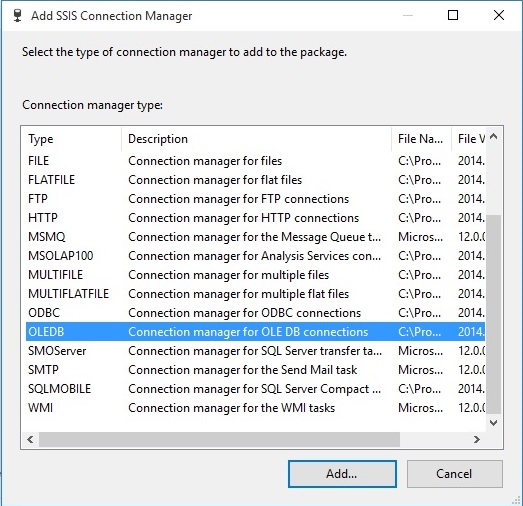
پنجره ای به نام Configure OLEDB Connection Manager ظاهر خواهد شد که با کلیک دکمه New پنجره ای به نام Connection Manager ظاهر خواهد شد. گزینه Server Name و دیتابیس مورد نظر را انتخاب می کنیم.
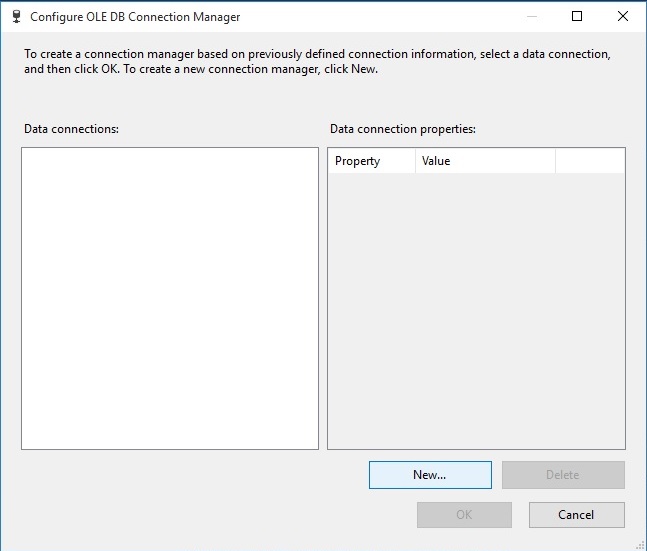
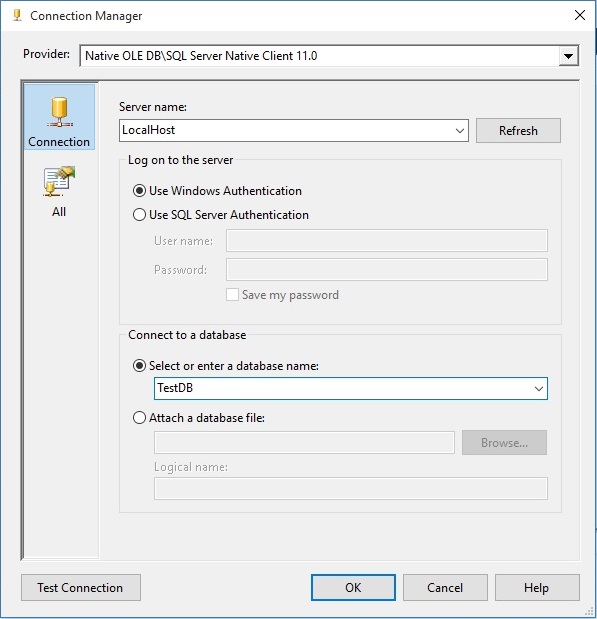
بعد از اطمینان از درستی برقراری کانکشن با کلیک دکمه Test Connection، دکمه OK را کلیک کرده تا به مرحله بعد برویم.
Data Flow Task را از جعبه ابزار به صفحه طراحی منتقل می کنیم.
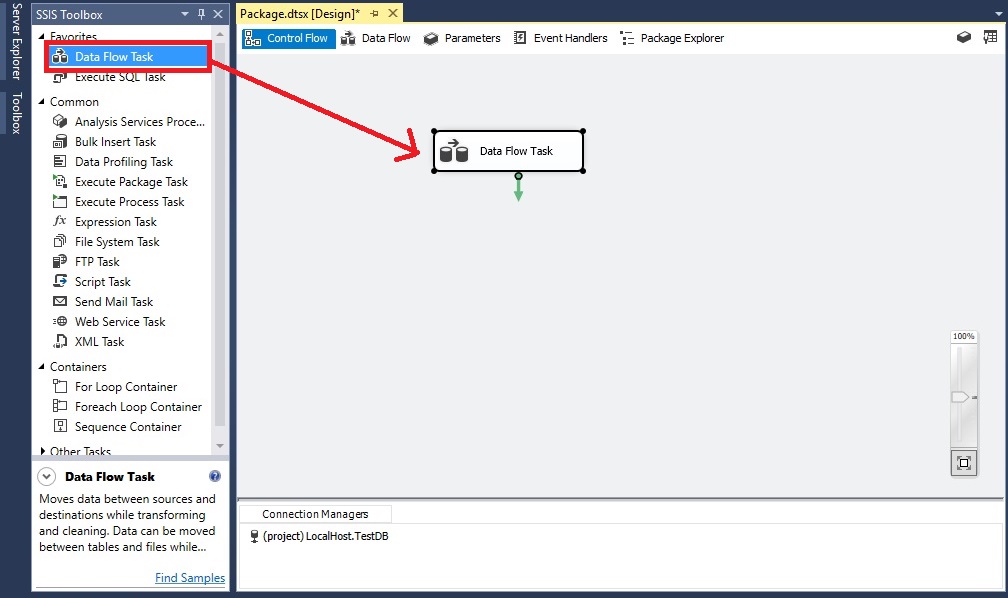
روی Data Flow Task کلیک راست کرده و گزینه Edit را انتخاب می کنیم تا وارد Data Flow Task شویم. سپس OLEDB Source را از جعبه ابزاربه محیط طراحی منتقل می کنیم.
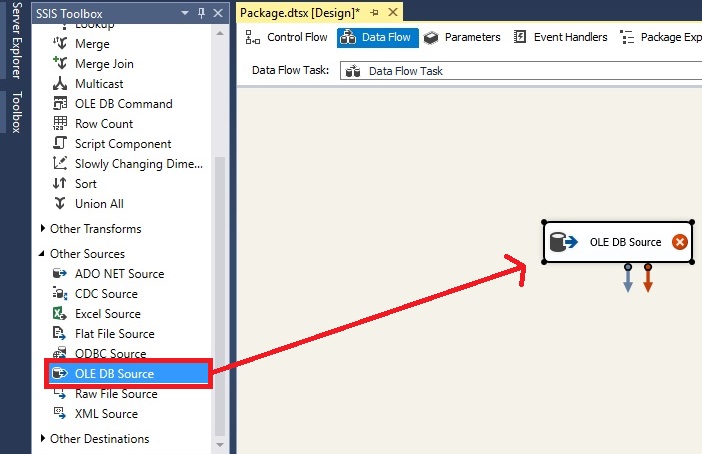
روی OLEDB Source راست کلیک کرده و گزینه Edit را انتخاب می کنیم. پنجره ای با نام OLEDB Source Editor ظاهر خواهد شد. دیتابیس و سپس جدول مورد نظر خود را انتخاب میکنیم.
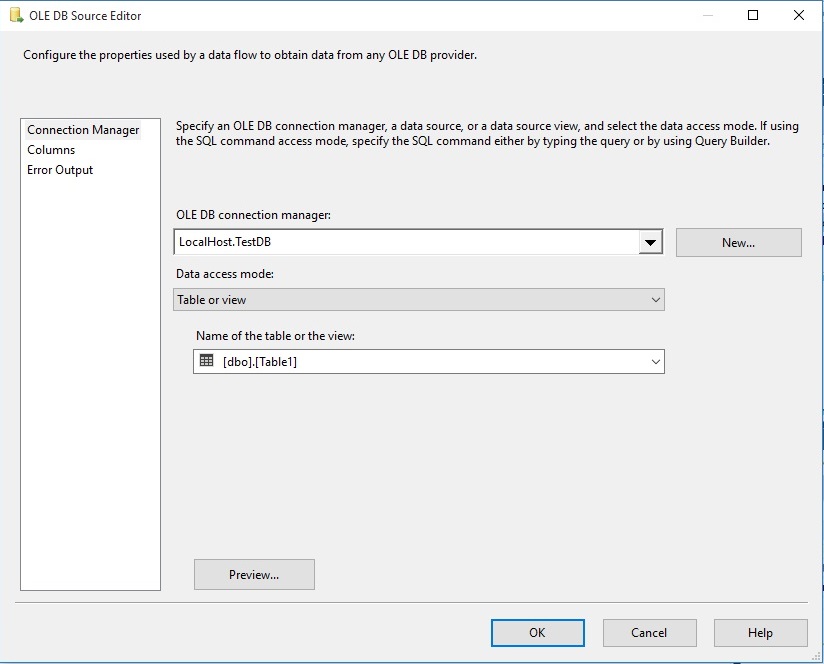
روی دکمه Preview کلیک کرده تا یک پیش نمایش از جدول ببینیم.
در تصویر جدول زیر، رکوردهای تکراری را علامت گذاری کرده ایم.

روی دکمه Close و سپس OK کلیک کرده تا به محیط طراحی برویم.
Sort را از جعبه ابزار به محیط طراحی منتقل کرده و سپس OLEDB Source را به Sort متصل می کنیم.
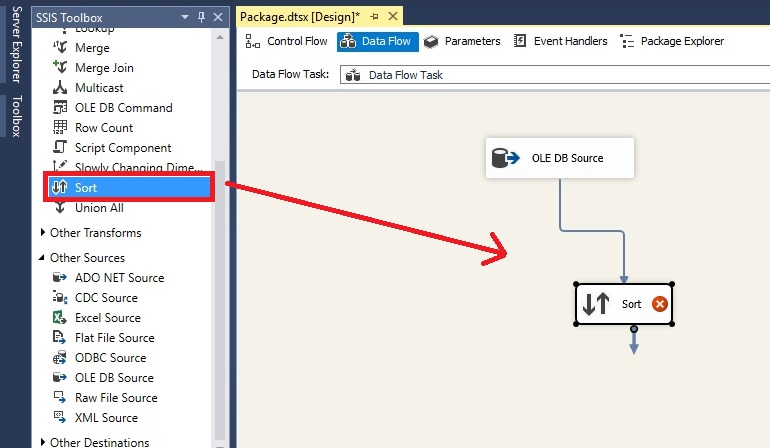
روی کامپوننت Sort کلیک راست کرده و گزینه Edit را انتخاب می کنیم.صفحه یی به نام Sort Transformation Editor باز خواهد شد که با انتخاب هر فیلد، عمل مرتب سازی، بر اساس فیلد انتخاب شده انجام می شود.
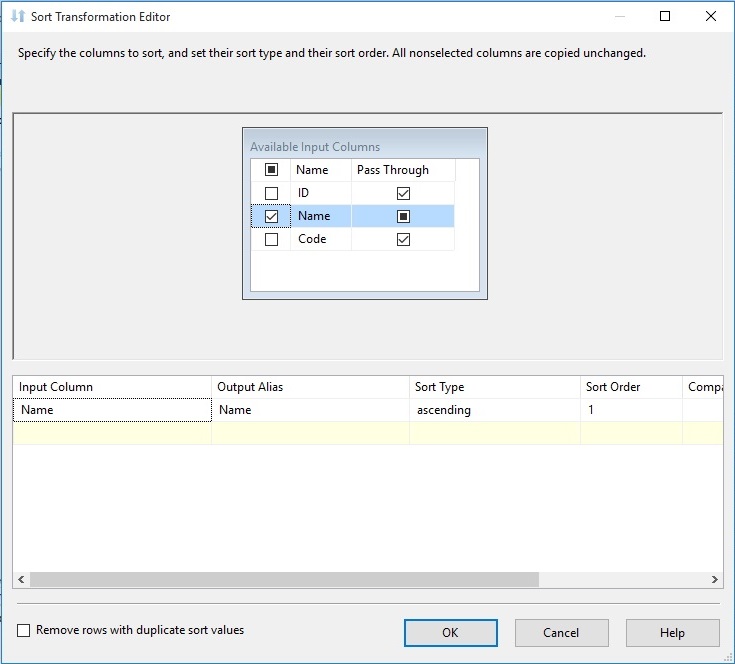
روی دکمه OK کلیک کرده و Derived Column را از جعبه ابزار به محیط طراحی منتقل می کنیم. سپس کامپپوننت Sort را به Derived Column متصل می کنیم.
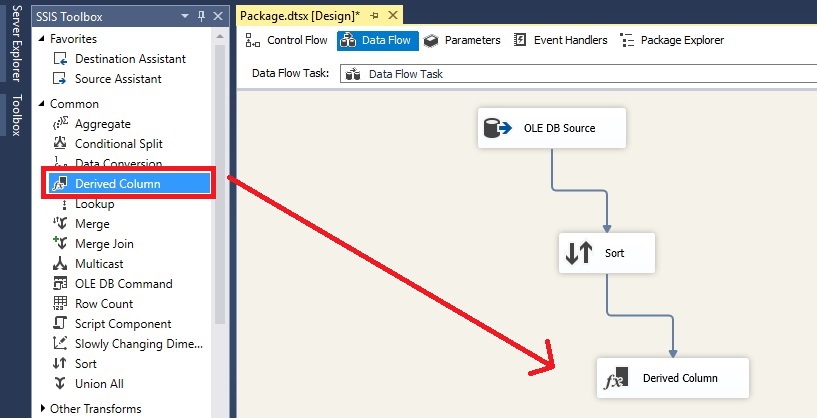
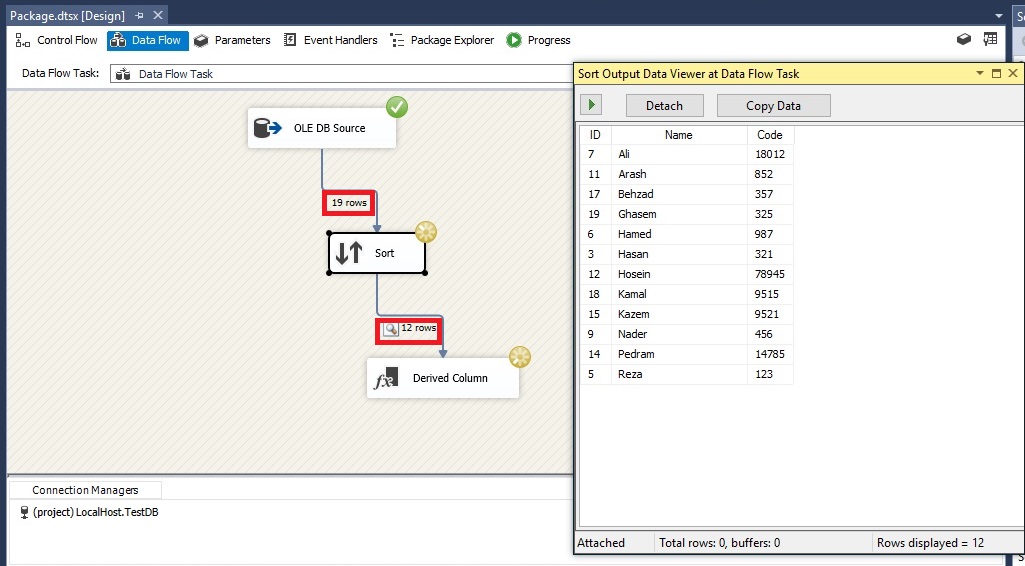
روی متصل کننده ی کامپوننت Sort به کامپوننت Derived Column کلیک راست کرده و گزینه Enable Data Viewer را انتخاب می کنیم تا تعداد رکوردهای منتقل شده راببینیم.
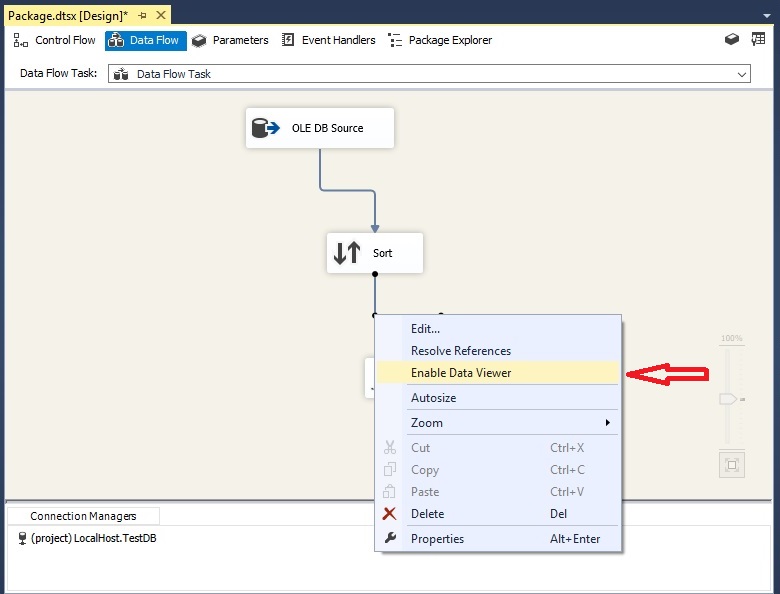
روی دکمه Start که در نوار ابزار است، کلیک کرده تا رکوردهای مرتب شده را ببینیم.

همانطور که می بینید، رکوردهای زیر بر اساس ستون Name مرتب شده اند.
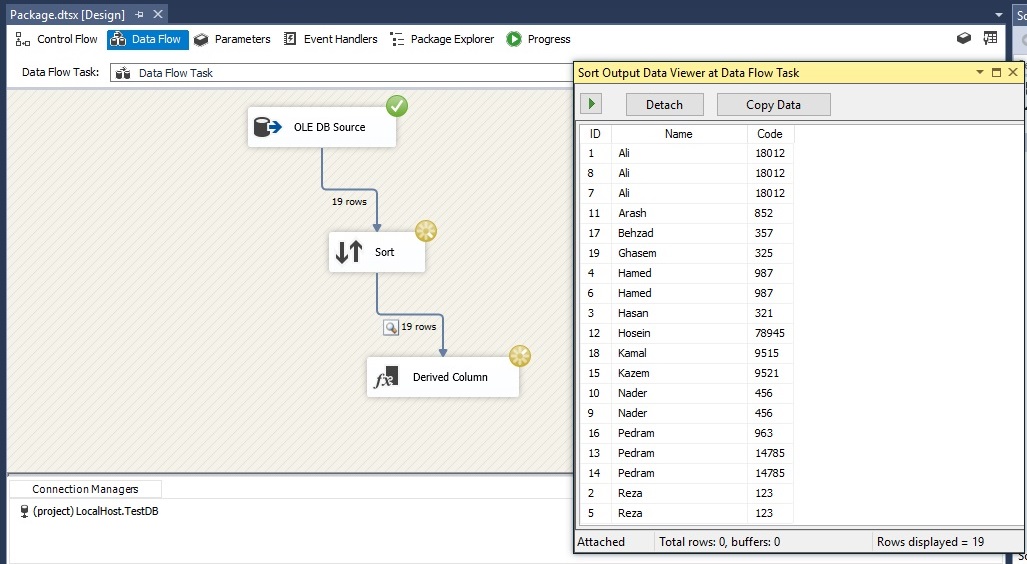
روی دکمه Stop که در نوار ابزار است کلیک کرده و روی کامپوننت Sort کلیک راست کنید و گزینه Edit را زده تا پنجره Sort Transformation Editor مجدد ظاهر شود. سپس Remove Rows With Duplicate Sort Values را انتخاب کرده و روی دکمه OK کلیک می کنیم.
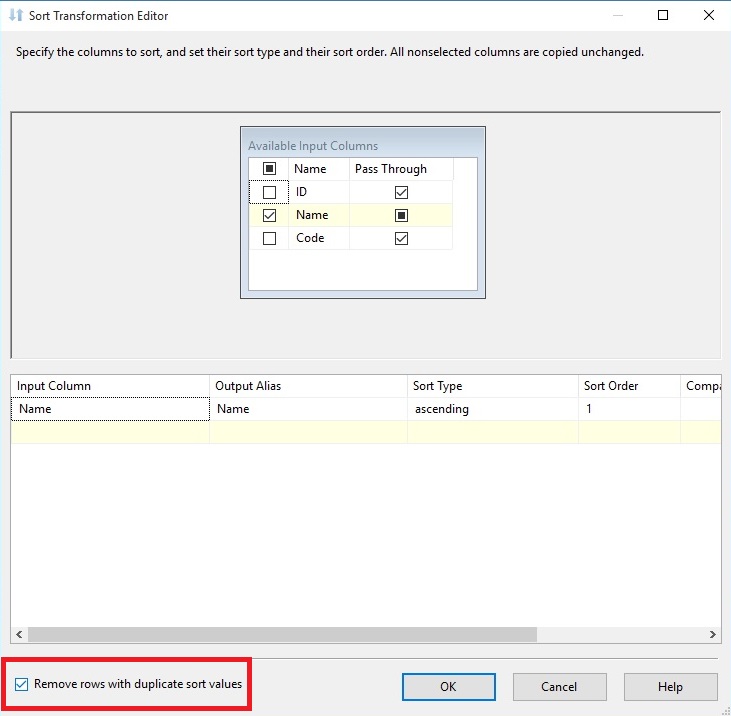
روی دکمه Start کلیک کرده تا نتیجه را ببینیم. همانطور که در تصویر زیر مشخص است، 19 سطر به کامپوننت Sort منتقل، در آنجا مرتب سازی و سپس سطرهای تکراری حذف شده و 12 سطر به مرحله بعد منتقل می شود.