هوش تجاری (Business Intelligence)
به اشتراک بگذاریم برای یادگیری، یاد بگیریم برای به اشتراک گذاریهوش تجاری (Business Intelligence)
به اشتراک بگذاریم برای یادگیری، یاد بگیریم برای به اشتراک گذاریحذف سطرهای تکراری یک جدول، بوسیله SSIS Sort Transformation
در SQL Server برای حذف رکوردهای تکراری یک جدول، راه های متعددی وجود دارد که در این پست با استفاده از سرویس SSIS این کار را به راحتی انجام خواهیم داد.
در SSIS وقتی نیاز به مرتب سازی جدول پیدا می کنیم، میتوانیم از کامپوننتی به اسم Sort استفاده کنیم که مانند دستور Order By عمل میکند و میتواند به صورت صعودی و نزولی سطرها را مرتب کند.
ابتدا یک پروژه SSIS ساخته ، سپس در قسمت Solution Explorer روی Connection Managers کلیک راست کرده و گزینه New Connection Manager را انتخاب می کنیم.
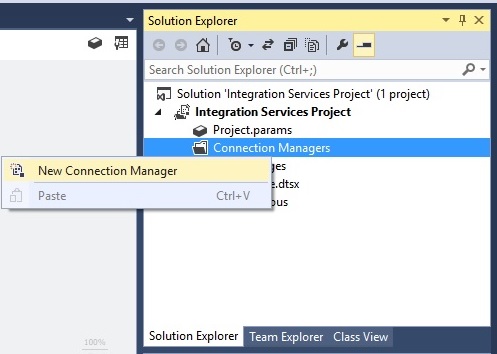
پنجره ای باز میشود به اسم Add SSIS Connection Manager، که در این مثال نوع OLEDB را انتخاب و سپس دکمه Add را میزنیم.
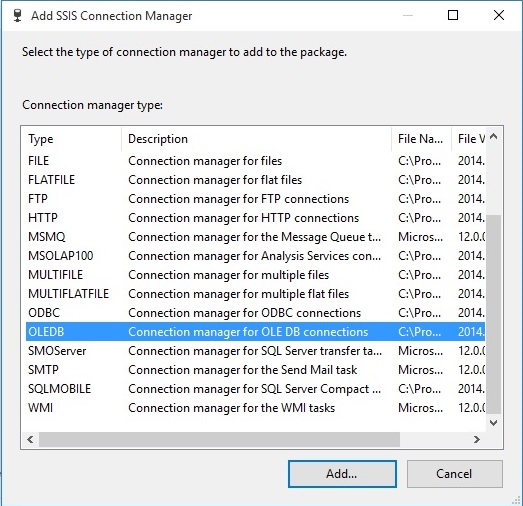
پنجره ای به نام Configure OLEDB Connection Manager ظاهر خواهد شد که با کلیک دکمه New پنجره ای به نام Connection Manager ظاهر خواهد شد. گزینه Server Name و دیتابیس مورد نظر را انتخاب می کنیم.
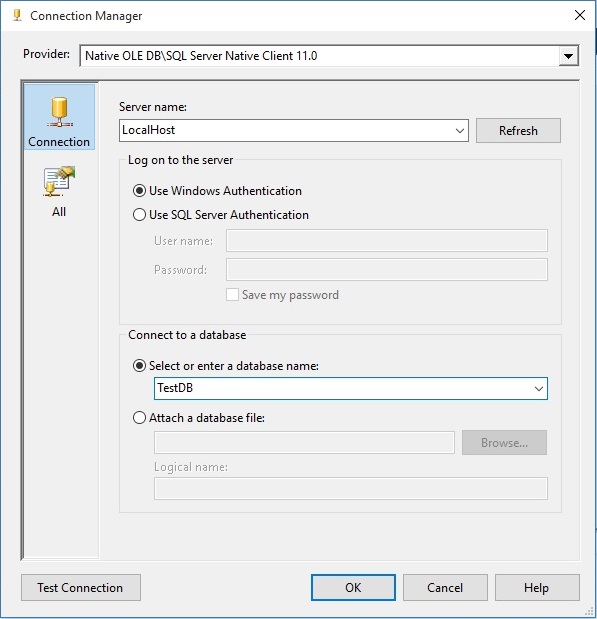
بعد از اطمینان از درستی برقراری کانکشن با کلیک دکمه Test Connection، دکمه OK را کلیک کرده تا به مرحله بعد برویم.
Data Flow Task را از جعبه ابزار به صفحه طراحی منتقل می کنیم.
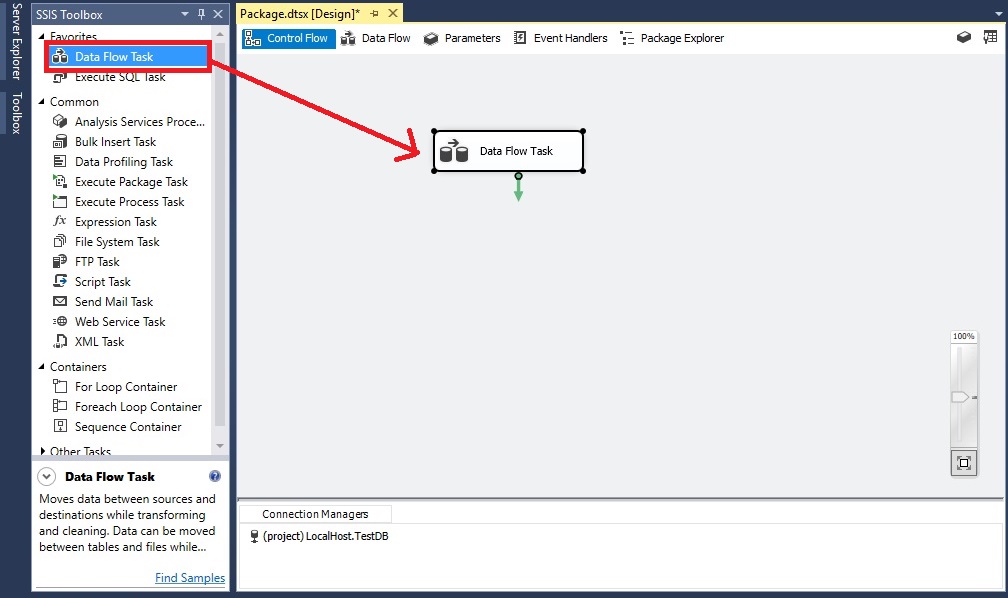
روی Data Flow Task کلیک راست کرده و گزینه Edit را انتخاب می کنیم تا وارد Data Flow Task شویم. سپس OLEDB Source را از جعبه ابزاربه محیط طراحی منتقل می کنیم.
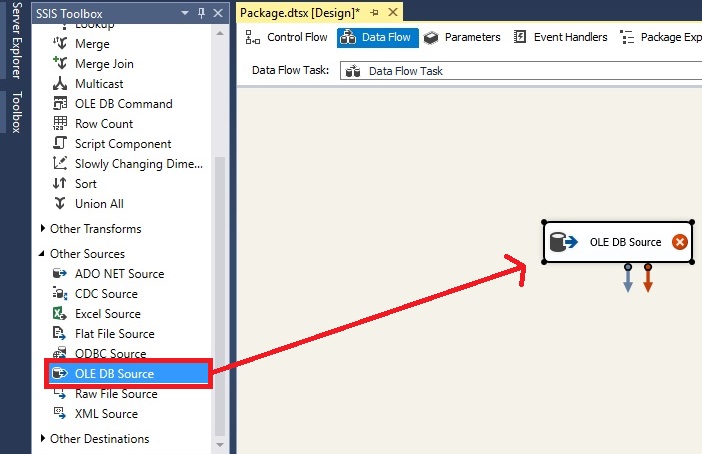
روی OLEDB Source راست کلیک کرده و گزینه Edit را انتخاب می کنیم. پنجره ای با نام OLEDB Source Editor ظاهر خواهد شد. دیتابیس و سپس جدول مورد نظر خود را انتخاب میکنیم.
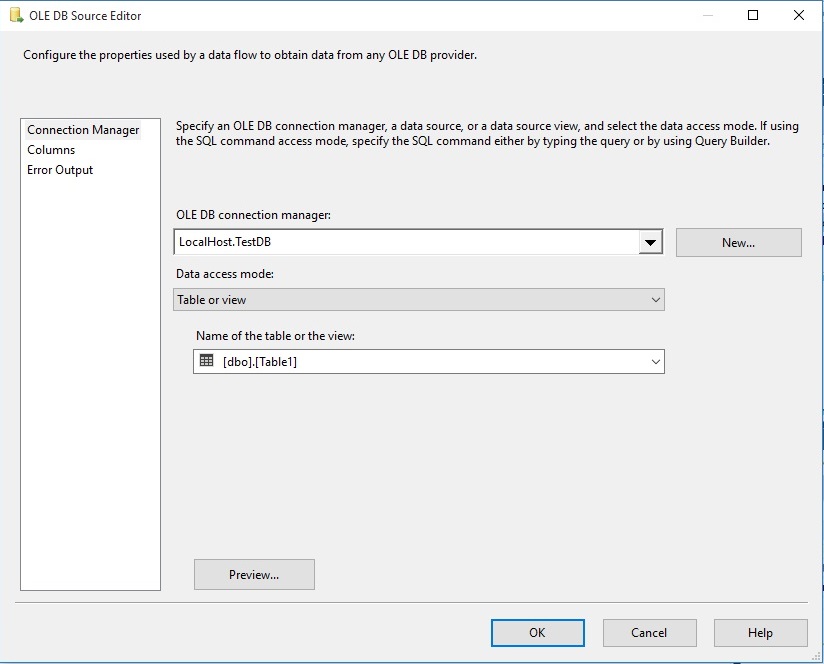
روی دکمه Preview کلیک کرده تا یک پیش نمایش از جدول ببینیم.
در تصویر جدول زیر، رکوردهای تکراری را علامت گذاری کرده ایم.

روی دکمه Close و سپس OK کلیک کرده تا به محیط طراحی برویم.
Sort را از جعبه ابزار به محیط طراحی منتقل کرده و سپس OLEDB Source را به Sort متصل می کنیم.
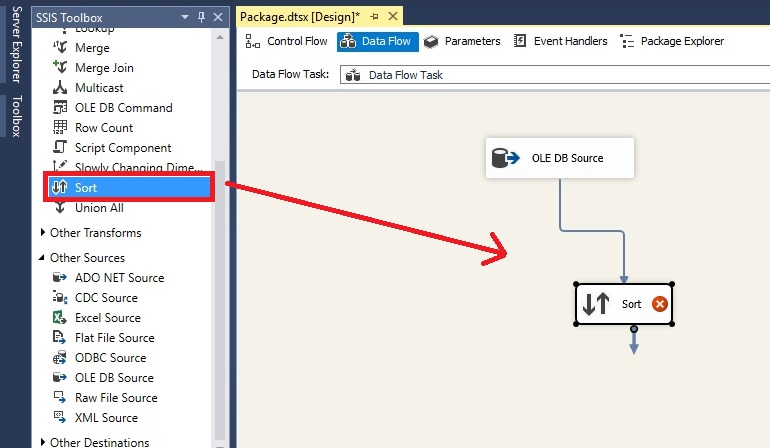
روی کامپوننت Sort کلیک راست کرده و گزینه Edit را انتخاب می کنیم.صفحه یی به نام Sort Transformation Editor باز خواهد شد که با انتخاب هر فیلد، عمل مرتب سازی، بر اساس فیلد انتخاب شده انجام می شود.
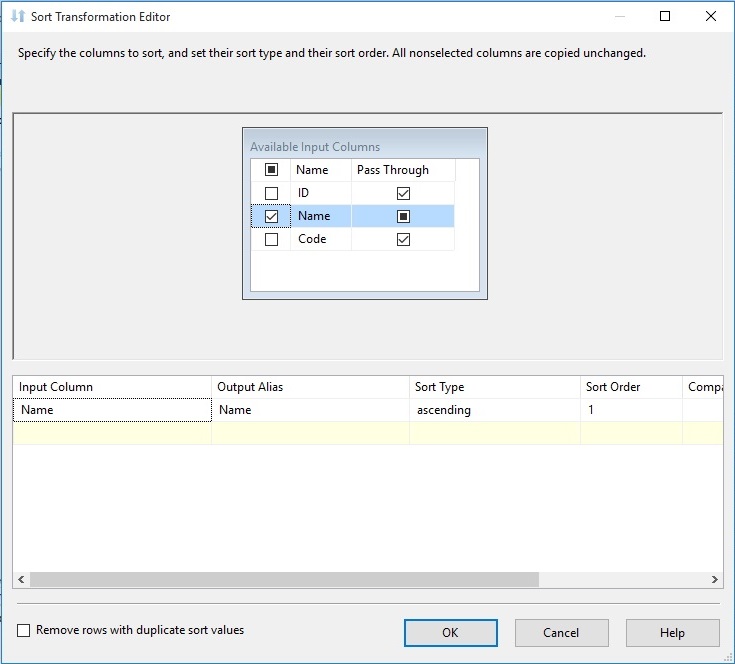
روی دکمه OK کلیک کرده و Derived Column را از جعبه ابزار به محیط طراحی منتقل می کنیم. سپس کامپپوننت Sort را به Derived Column متصل می کنیم.
روی متصل کننده ی کامپوننت Sort به کامپوننت Derived Column کلیک راست کرده و گزینه Enable Data Viewer را انتخاب می کنیم تا تعداد رکوردهای منتقل شده راببینیم.
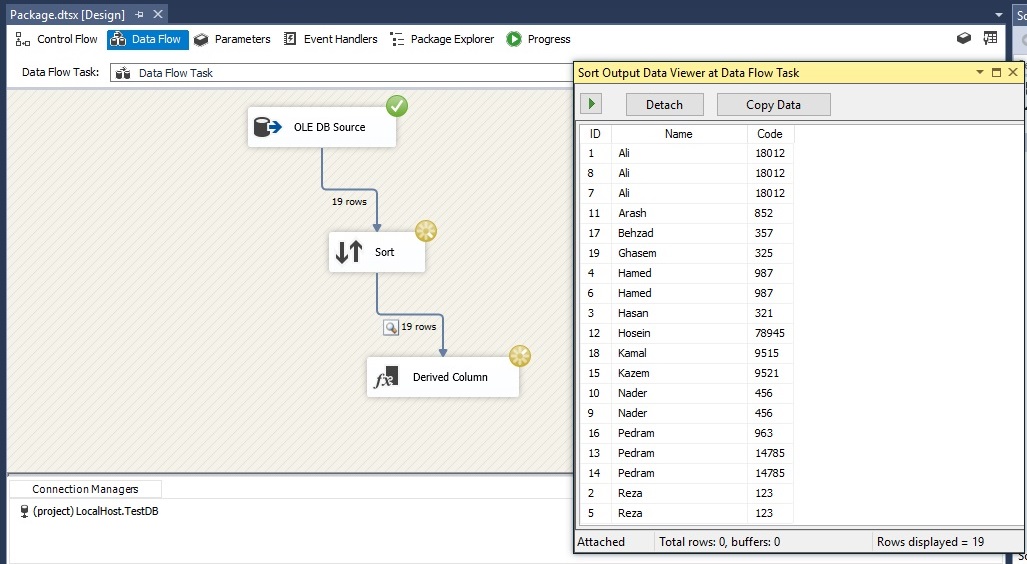
روی دکمه Start که در نوار ابزار است، کلیک کرده تا رکوردهای مرتب شده را ببینیم.

همانطور که می بینید، رکوردهای زیر بر اساس ستون Name مرتب شده اند.
روی دکمه Stop که در نوار ابزار است کلیک کرده و روی کامپوننت Sort کلیک راست کنید و گزینه Edit را زده تا پنجره Sort Transformation Editor مجدد ظاهر شود. سپس Remove Rows With Duplicate Sort Values را انتخاب کرده و روی دکمه OK کلیک می کنیم.
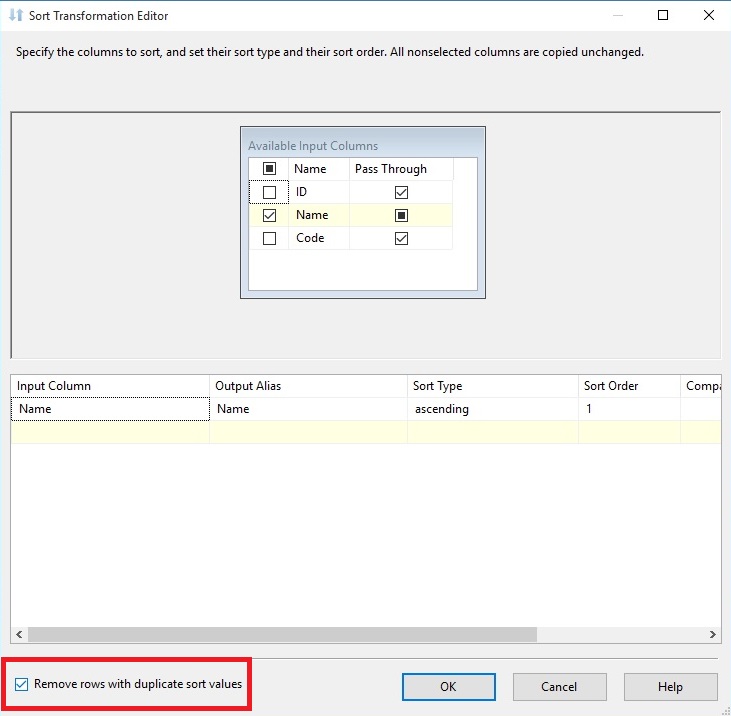
روی دکمه Start کلیک کرده تا نتیجه را ببینیم. همانطور که در تصویر زیر مشخص است، 19 سطر به کامپوننت Sort منتقل، در آنجا مرتب سازی و سپس سطرهای تکراری حذف شده و 12 سطر به مرحله بعد منتقل می شود.
همگام سازی (Synchronize) دو جدول در SSIS
پیشتر مطالبی در مورد روشهای مقایسه رکوردهای دو جدول نوشته بودم. یکی از این روشها استفاده از tablediff است که مطالب مربوط به آن را میتوانید اینجا مشاهده کنید، اما برای انجام آن دو مسئله وجود دارد. اول اینکه پس از ایجاد فایل تغییرات، باید آن فایل را باز کرده و اجرا کنیم و دوم گرفتن خطا توسط SQL در زمان ایجاد مجدد است، چراکه این فایل قبلا ایجاد شده است. البته از چند طریق میتوان این مشکلات را حل کرد.
در این پست قصد دارم به حل این مسئله از طریق ایجاد یک پکیج در SSIS بپردازم.
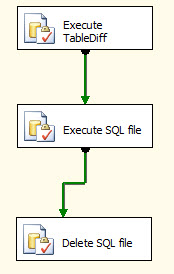
1- در SSIS یک Package مطابق شکل زیر ایجاد کنید.
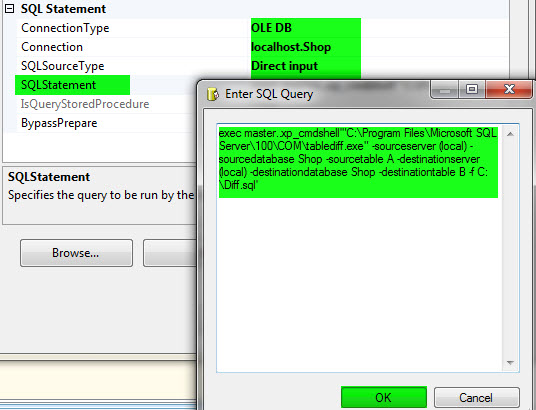
2- قطعه کد زیر را در Execute TableDiff قرار دهید.
exec master..xp_cmdshell'"C:\Program Files\Microsoft SQL Server\100\COM\tablediff.exe" -sourceserver (local) -sourcedatabase Shop -sourcetable A -destinationserver (local) -destinationdatabase Shop -destinationtable B -f C:\Result.sql'
برای اطلاع از سایر پارامترها و ویژگی های Tablediff به اینجا مراجعه کنید.
همانطور که در مطالب مربوط به tablediff گفتم، با اجرای این کوئری رکوردهای دو جدول با هم مقایسه و نتیجهی آن در فایل Result.sql ذخیره میشود.
3- توسط Execute SQL file فایل SQL ایجاد شده در مرحله قبل را اجرا کنید.
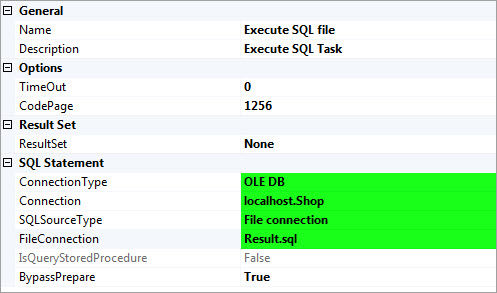
4- برای اینکه در زمان اجرای مجدد پکیج و ایجاد فایل به مشکل بر نخوریم، با استفاده از یک دستور ساده فایل ایجاد شده در مرحله قبل را حذف میکنیم.
xp_cmdshell 'del c:\Result.sql'
کار تمام است! حال هر زمان که اطلاعات موجود در جدول اول تغییر کرد میتوانید پکیج را اجرا کنید و جدول دوم را همانند جدول اول داشته باشید.
واکشی دادهها از شیرپوینت و بارگذاری در SQL توسط SSIS
امروزه استفاده از شیرپوینت به عنوان ابزار ایجاد کننده وب سایت به دلیل سرعت بالا در ایجاد و راهاندازی بسیار گسترش پیدا کرده است و بسیاری از سازمانها از آن استفاده میکنند. بنابراین میتوان شیرپوینت را به عنوان منبع دادهها در نظر گرفت.
برای خواندن و بارگذاری دادههای شیرپوینت در SQL Server از طریق SSIS چندین روش وجود دارد که در این مقاله به یکی از بهترین و سادهترین آنها که استفاده از SharePoint Web services است، میپردازم.
ابتدا باید Features مربوط به SharePoint List Source and Destination را از اینجا دریافت کنید.
پس از دانلود، مطابق تصاویر زیر مراحل نصب را انجام دهید.
بعد از اتمام مراحل نصب باید کامپننتهای SharePoint List Source and Destination را به جعبه ابزار SSIS اضافه کنید. برای اینکار مراحل زیر را انجام دهید.
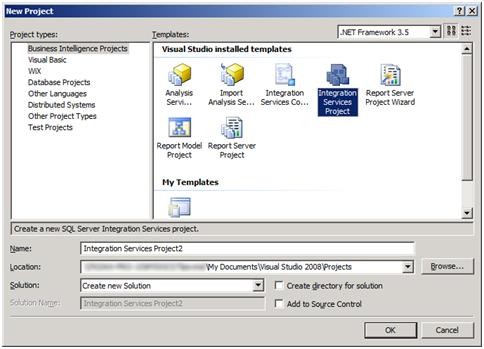
1- برنامه Business Intelligence Development Studio را باز کردهو مطابق تصویر زیر یک پروژهی جدید SSIS ایجاد کنید.
2- از منوی Tools گزینه Choose Toolbox Items را انتخاب کنید.
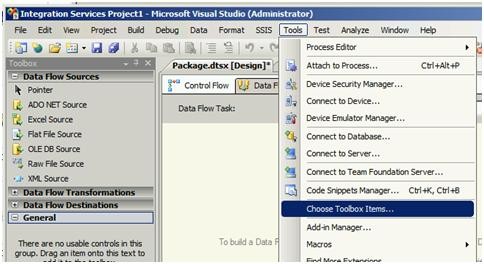
پنجره Choose Toolbox Items باز میشود.
3- از پنجره بازشده به سربرگ SSIS Data Flow Items رفته و چکباکس مربوط به SharePoint List Source و SharePoint List Destination را انتخاب نمایید. برروی Ok کلیک کنید.
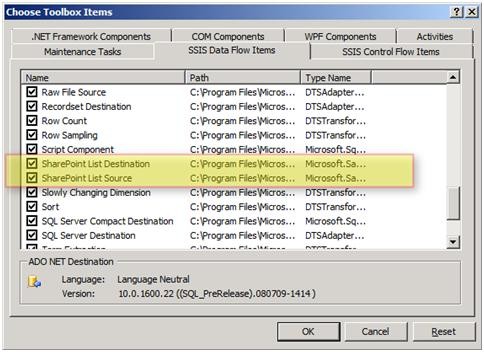
این دو کامپننت به قسمت General در جعبه ابزار SSIS اضافه میشوند. شما میتوانید هر یک از آنها را به محل مناسب خود منتقل کنید.
آماده سازی یک لیست شیرپوینت جهت انجام یک مثال
1- ایجاد لیستی با عنوان TestSharePointList که شامل اطلاعات زیر باشد.
نام: کارمندان
ستونها:
· شماره پرسنلی (نوع: عدد)
· نام کارمند(نوع: کاراکتر)
· جنسیت (انتخابی؛ انتخاب اول، زن انتخاب دوم، مرد)

ایجاد یک جدول در SQL مطابق با لیست ایجاد شده در شیرپوینت
1- وارد SSMS شده و یک بانک اطلاعاتی با نام TestDB ایجاد کنید.
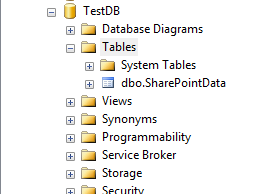
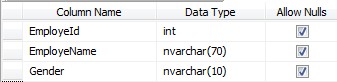
2- مطابق شکل زیر یک جدول با نام SharePointData ایجاد کنید.
استخراج داده از لیست شیرپوینتی ساخته شده توسط SharePoint List Source
1- در این قسمت ابتدا باید یک اتصال دهنده شیرپوینتی ایجاد نمود. برای انجام اینکار مطابق تصاویر زیر عمل کنید.
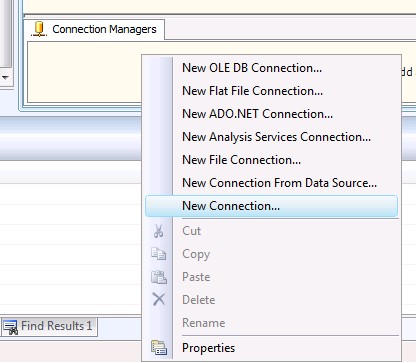
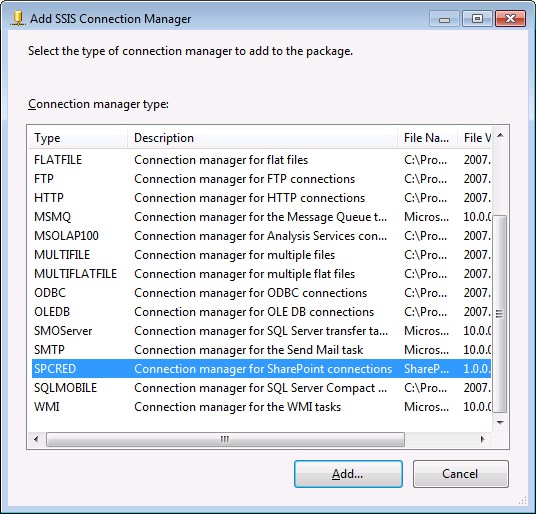
این اتصال دهنده پس از نصب Features مربوط به شیرپوینت که مراحل نصب آن در ابتدای مقاله توضیح داده شد، به لیست Add SSIS Conection Manager اضافه میشود.
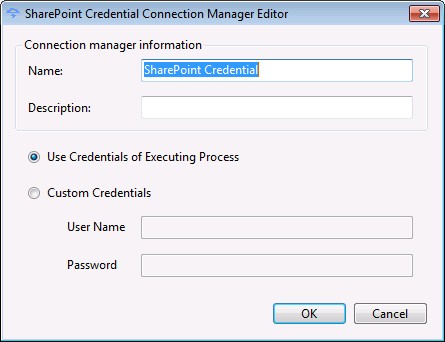
در صورتی که برای دسترسی به لیستهای شیرپوینتی نیاز به دسترسی خاصی دارید باید در قسمت Custom Credentials نام کاربری و رمز عبور آن User مربوطه را وارد کنید.
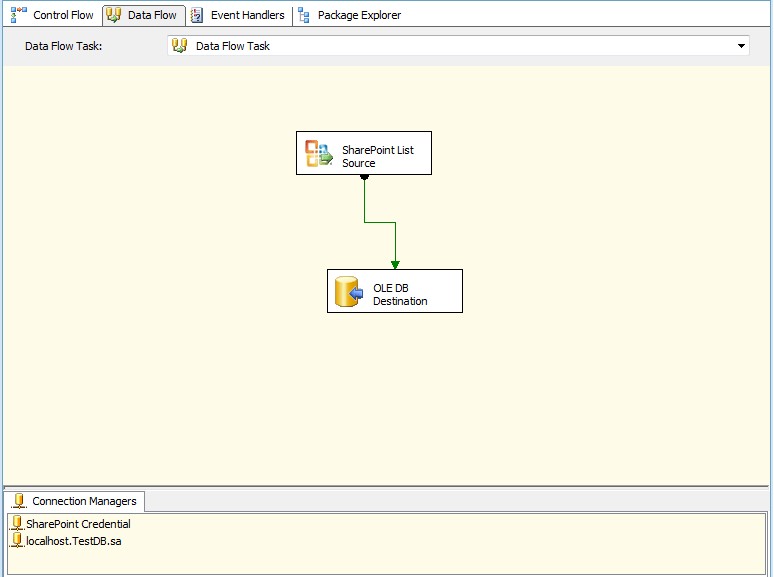
2- از جعبه ابزار یک کامپننت Data Flow Tasks به پکیج خود اضافه کنید. مجدد از جعبه ابزار SharePoint List Source را درون Data Flow Tasks قرار دهید.

3- انجام تنظیمات مربوط به SharePoint List Source، برای اینکار برروی کامپننت SharePoint List Source دوبار کلیک کرده و مطابق تصاویر زیر عمل نمایید.
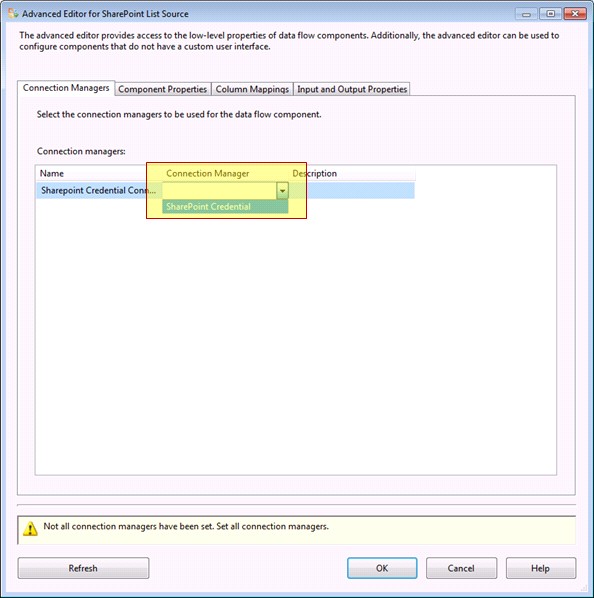
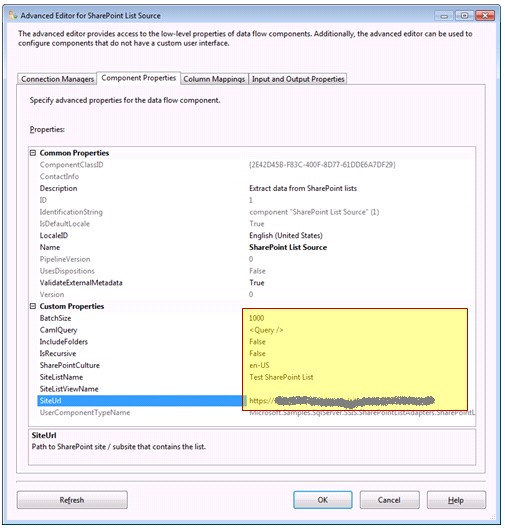
پس از وارد کردن آدرس مربوط به سایت لیست ساخته شده و نام آن در قسمت SiteUrl و SiteListName بر روی Refresh کلیک کنید تا ارتباط با لیست ساخته شده برقرار شود.
در این قسمت تنظیمات دیگری نیز وجود دارد که در مقالهای جداگانه به آنها خواهم پرداخت.
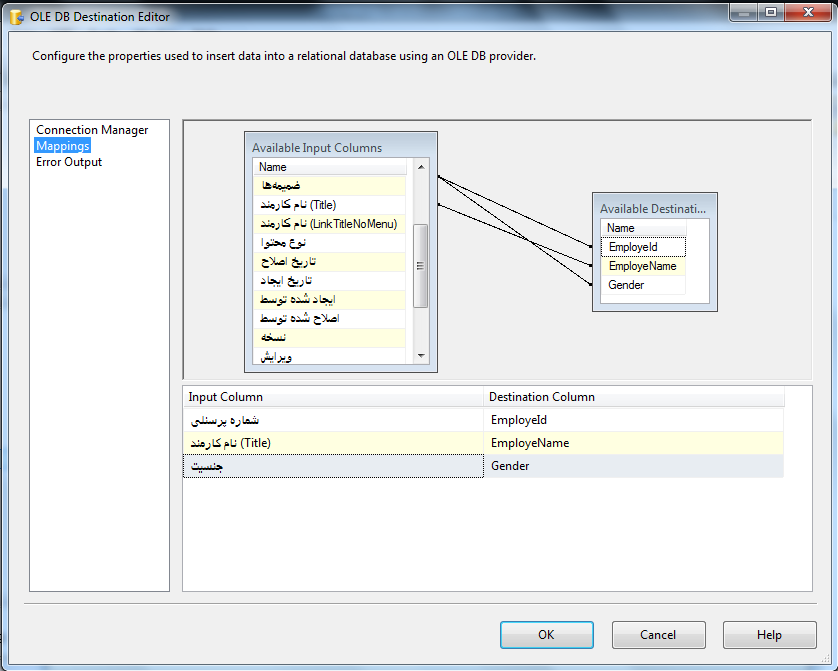
4- در مرحله بعد باید ستونهای مورد نظر خود را انتخاب کنید. برای اینکار به سربرگ Column Mappings بروید تا فیلدهای لیست شیرپوینتی نمایش داده شود. برخی از این فیلدها توسط خود شیرپوینت ساخته میشود. فیلدهایی که قصد دارید آنها را در خروجی داشته باشید را انتخاب کرده و بر روی Ok کلیک کنید.
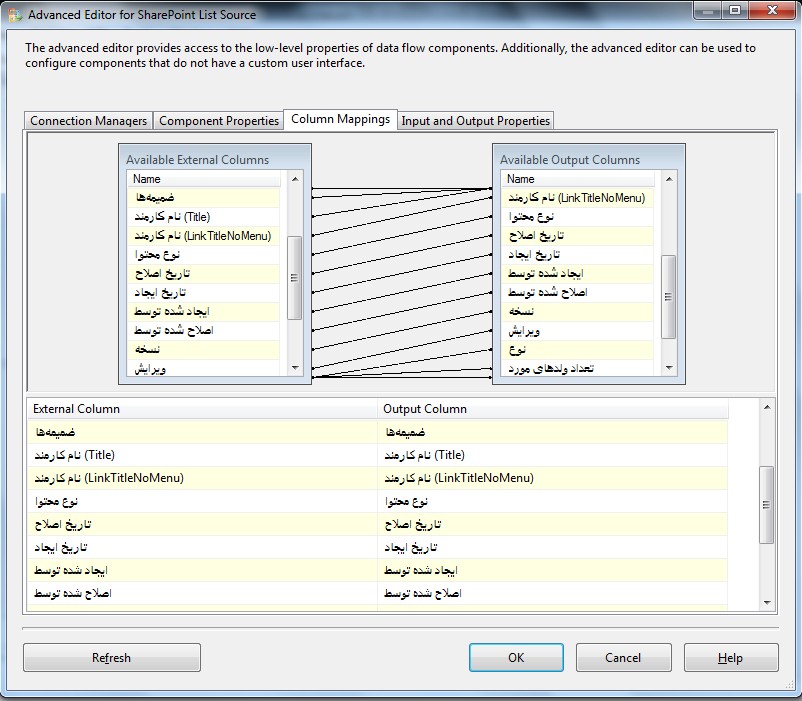
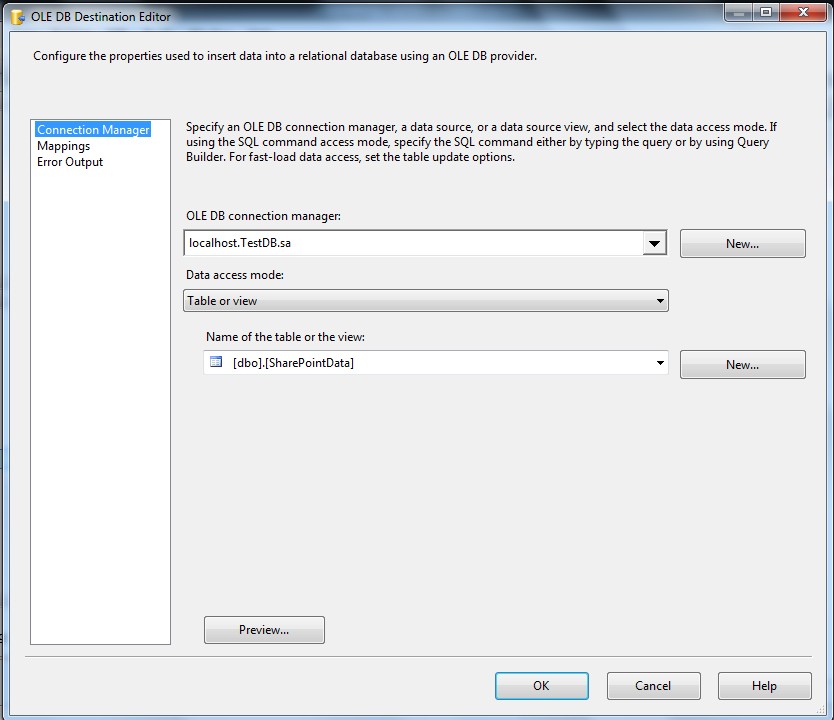
5- از جعبه ابزار یک OLE DB Destination به پکیج اضافه کنید و تنظیمات آن را مطابق تصاویر زیر انجام دهید.
برروی کامپننت OLE DB Destination دوبار کلیک کنید تا صفحه مربوط به تنظیمات آن باز شود. سپس جدولی که پیشتر در SQL ساخته بودید را انتخاب نمایید.
در قسمت Mapping فیلدهای جداول مبدا و مقصد را انتخاب کنید.
با کلیک برروی Ok کار تمام است و میتوانید پکیج را اجرا کنید.

SSIS و کاربرد آن در پروژه
شرکت ماکروسافت سرویس SSIS را برای ایجاد راهحلهای مختلف جهت مدیریت و انتقال دادهها فراهم کرده است.
با یک مثال به معرفی بهتر SSIS میپردازم؛ فرض کنید توسط SSAS یک پروژهی بزرگ سازمانی که شامل چندین Cube، Dimension، KPI و ... است، ایجاد کردهاید و از آنجایی که در این پروژه از روش ذخیرهسازی MOLAP استفاده شده، در هر بار به روز رسانی دادهها در انبار داده باید مکعبهای داده و ابعاد نیز پردازش شوند. از طرفی نه درست است و نه منطقی که کاربر نهایی هر روز وارد SSAS شود و Solution را پردازش کند.
بهترین روشی که برای حل این مشکل معرفی میشود، استفاده از SSIS است. در SSIS با ایجاد یک Package و استفاده از کامپننتهای مربوطه این کار به راحتی انجام میشود. کاربرد SSIS تنها برای پردازش Solutionها نیست. در واقع SSIS یک پلتفرم (Platform) سطح بالا برای فراهم کردن راهکارهای مختلف جهت مدیریت و انتقال اطلاعات است. از این سرویس برای کپی کردن یا دانلود فایل، ارسال و دریافت ایمیل، بهروز رسانی انبار داده، پاکسازی و کاوش در دادهها، مدیریت شیءها (Objects) و دادههای SQL استفاده میشود. علاوه بر این SSIS توانایی استخراج (Extract) و تبدیل کردن (Transform) دادهها از فایلهای دادهای XML و منابع داده رابطهای و بارگذاری (Load) در یک یا چند مقصد را دارد.
گرافیکی بودن ابزارها از دیگر مزایای SSIS است. به سادگی میتوان از این ابزارها برای ساخت Package استفاده نمود بدون نیاز به حتی یک خط کد نویسی! البته در صورت نیاز به کد نویسی ابزار و شرایط آن فراهم است.
هر پکیج دارای یک یا چند کامپننت است که میتوانند به تنهایی و یا با ترکیبی از هم اجرا شوند. هر پکیج نیز میتواند به تنهایی یا با هماهنگی با سایر پکیجها اجرا شود.
آشنایی با INTERSECT و EXCEPT
معمولا برای مقایسه رکوردهای دو جدول از کوئریهای پیچیده استفاده میشود. دو دستور INTERSECT و EXCEPT نتایج مقایسه رکوردهای دو کوئری را بدون نمایش رکوردهای تکراری نمایش میدهد.
EXCEPT رکوردهایی که در کوئری اول (سمت چپ) وجود دارد و در کوئری دوم (سمت راست) وجود ندارد را نمایش میدهد.به زبان سادهتر، رکوردهایی که در اولی هست و در دومی نیست.
INTERSECT رکوردهایی که در هر دو کوئری مشترک هستند را نمایش میدهد.
به دو کوئری زیر توجه کنید
USE AdventureWorks; GO SELECT ProductID FROM Production.Product INTERSECT SELECT ProductID FROM Production.WorkOrder ; --Result: 238 Rows (products that have work orders) |
در دو جدول Product و WorkOrder تعداد 238 رکورد وجود دارد که ProductID آنها مشترک است.
USE AdventureWorks; GO SELECT ProductID FROM Production.Product EXCEPT SELECT ProductID FROM Production.WorkOrder ; --Result: 266 Rows (products without work orders) |
تعداد 266 رکورد وجود دارد که ProductID آنها در جدول Product (اولی) وجود دارد و در جدول WorkOrder (دومی) وجود ندارد.
جهت دریافت و نصب بانک اطلاعاتی AdventureWorks به اینجا مراجعه کنید.
منبع:
http://msdn.microsoft.com/en-us/library/ms188055(v=sql.100).aspx