هوش تجاری (Business Intelligence)
به اشتراک بگذاریم برای یادگیری، یاد بگیریم برای به اشتراک گذاریهوش تجاری (Business Intelligence)
به اشتراک بگذاریم برای یادگیری، یاد بگیریم برای به اشتراک گذاریتعاریف پایه در SSAS- بخش دوم
پارتیشن (Partitions)
معمولا زمانی از پارتیشن استفاده میکنیم که با حجم زیادی از دادهها روبرو باشیم. برای پردازش دادههای حجیم زمان زیادی را باید صرف کرد، از طرفی نیازی نیست دادههای از پیش پردازش شده را مجدد پردازش نمود و فقط باید دادههای جدیدی که به انبار دادهها اضافه میشوند را مورد پردازش قرار داد.جهت اینکار دادهها را پارتیشن بندی میکنیم.
پیشمحاسبه(Aggregation)
کلمه Aggregation در لغت به معنای تجمیع و تراکم است اما مفهوم آن در SSAS پیشمحاسبه (Precalculated) است. به این معنا که در هنگام پردازش دادهها یک پیشمحاسبه نیز انجام میشود. این عمل همانند آماده و همراه داشتن خلاصهای از پاسخهای احتمالی، پیش از طرح سوال است. برای مثال زمانی که با یک جدول از هزاران رکورد روبرو هستیم، در هر زمان برای پاسخ به هر یک از سوالها (کوئری) زمان زیادی طول میکشد تا پاسخ مناسب دریافت شود. در صورتی که اگر پاسخ سوالات از پیش آماده شده باشند سرعت پاسخ گویی به مراتب بیشتر میشود.
Perspective
در OLAP برای دستهبندی و جداسازی معیارها، ابعاد، KPIها و... از Perspective استفاده میشود.
Browser
در SSAS خروجی Cubeهای ایجاد شده در این قسمت نمایش داده میشوند.
MDX
زبان برنامهنویسی در OLAP است که مخفف Multidimensional Expressions میباشد.
مجموعه داده(Named Set)
یکی از ابزارهای موجود در سربرگ Calculations، مجموعه داده است که توسط آن میتوان عضوهای یک بٌعد خاص را دسته بندی کرد. برای مثال میتوانیم 10 عضو برتر بعد مشتری را که بیشترین خرید را داشتهاند نمایش داد. این عملیات توسط عبارات MDX انجام میگیرد.
Script Command
در این قسمت از MDX برای ایجاد عبارات خاص استفاده میشود.
Named Query
در واقع همان View است. توسط این قسمت میتوان Viewهایی در DSV ایجاد کرد. دیدهای ایجاد شده فقط در SSAS نمایش داده میشوند.
Named Calculation
در صورت نیاز به تعریف Attribute در ابعاد استفاده میشود. برای تعریف این نوع Attribute از عبارات MDX و Query استفاده میشود.
Mining Structure
پروژههای دادهکاوی در این قسمت تعریف میشوند.
Mining Models
برای ایجاد مدلهای مختلف دادهکاوی و اعمال تغییرات در خصوصیات آنها از این قسمت استفاده میشود.
Mining Model Viewer
در SSAS خروجی مدلهای دادهکاوی در این قسمت نمایش داده میشوند.
Mining Accuracy
جهت بررسی بهتر صحت خروجیهای نمایش داده شده و همچنین مقایسه مدلهای دادهکاوی ساخته شده در Mining Models از این قسمت استفاده میشود.
Mining Model Prediction
در برخی از الگوریتمها قابلیت پیشبینی وجود دارد. از این قسمت برای ایجاد پیش بینی استفاده میشود.
DMX
زبان برنامهنویسی در دادهکاوی است که مخفف Data Mining Expressions میباشد.
تعاریف پایه در SSAS- بخش اول
جدول حقایق (Fact)
این نوع جداول در انبار داده Fact یا جدول حقایق نامیده میشوند که مقادیر معیارها را شامل میشوند. معمولا در جدول حقایق، مقادیر عددی از اطلاعات سازمانها نظیر مقدار فروش و مبلغ فروش و همچنین کلیدهای خارجی (foreign key) برای برقرای ارتباط با ابعاد وجود دارد.
مکعب (Cube)
مکعبهای دادهای هستند که اطلاعات را به صورت چند بُعدی در خود ذخیره میکنند.
معیار (Measure)
به هر یک از مقادیر عددی نظیر مبلغ فروش و مقدار فروش که در Fact وجود دارد Measure گفته میشود.
گروه معیار(Measures Group)
یک یا چند معیار، گروه معیار را تشکیل میدهند. در واقع هر جدول حقایقی که در SSAS مورد استفاده قرار میگیرد یک Measures Group است.
ابعاد (Dimension)
اطلاعات تکمیلی و جزئیات جداول حقایق توسط ابعاد مشخص میشود. جداول ابعاد مجموعهای از ویژگیهای داده است. بعنوان مثال کد استان و نام استان درکنار هم میتواند بعد استان را تشکیل دهند.
ویژگیها (Attribute)
هر جدول بُعد دارای یک یا چند ویژگی است. ویژگیها جزئیات بشتر و بهتری از بُعد را فراهم میکنند. برای مثال کد استان و نام استان ویژگیهای دایمنشن استان را مشخص میکند.
عضوها (Members)
عدد "100" عضوی از ویژگیِ کد استان و "تهران" عضوی از ویژگی نام استان است.
سلسله مراتبها (Hierarchies)
در صورتی که ویژگیهای یک دایمنشن را به طوری مرتب کنید که بتوان به صورت معنادار در سطوح مختلف حرکت نمود، سلسله مراتب ایجاد کردهاید. بعنوان مثال سال، فصل، ماه، هفته و روز، یک سلسله مراتب از ویژگیهای بعد زمان است.
عضو محاسباتی(Calculated Member)
شامل عضوهای جداول ابعاد و یا گروه معیارها است که با استفاده از عبارات محاسباتی بصورت داینامیک اجرا و محاسبه میشود. هر عضو محاسباتی ایجاد شده فقط در Cube ذخیره میشود. بعنوان مثال میتوان یک عضو محاسباتی ایجاد کرد که محتوای دو معیار را با یکدیگر جمع نماید.
شاخصهای ارزیابی عملکرد (KPI)
در واقع معیارهای قابل سنجشی هستند که به صورت نمودارهای عقربهای (Gage) نمایش داده میشوند. اطلاعات مورد نیاز برای نمایش در گیج، طبق فرمولی از پیش مشخص میشود.
Actionها
در واقع Action عملی است که قصد داریم در زمان نیاز انجام شود. به عبارت دیگر Action رویدادی از پیش نوشته شده است که مشخص است در زمان وقوع چه عملی را باید انجام دهد. این عمل باعث هوشمندتر شدن Cubeها میشود. بعنوان مثال فرض کنید کاربر میخواهد با کلیک بر روی نام هر شهر نقشهی آن نمایش داده شود؛ برای حل این مسئله میتوان یک Action ایجاد کرد که پس از انتخاب هر شهر نقشهی آن توسط google mapsنمایش داده شود.
MOLAP، ROLAP و HOLAP
در یک پروژهی OLAP از یک یا چند مکعب داده (Cube) استفاده میشود. از اینرو Cube به عنوان یکی از مزایای پروژه هوش تجاری شناخته میشود. قرار گرفتن دادهها در یک فرمت بهینه جهت ذخیرهسازی به انجام سریعتر کوئریها میانجامد. معمولا نحوه ذخیرهسازی اطلاعات حجیم در Cube باعث تاخیر در ذخیره و بازیابی انبوه اطلاعات میشود. به طور معمول در SSAS پردازش دادهها از یک بانک اطلاعاتی رابطهای به Cube منتقل میشود. پس از اتمام این ارتباط نه چندان طولانی میان پایگاه دادههای رابطهای و Cube اطلاعات وارد Cube میشوند و با تغییر دادهها در پایگاه داده هیچ تغییری در اطلاعات موجود در Cube ایجاد نمیشود مگر آنکه Cube را مجدد پردازش کنید.
در SSAS2008 سه نوع ذخیرهسازی وجود دارد؛ MOLAP، ROLAP و HOLAP
در این پست هر یک از انواع ذخیرهسازی را به صورت خلاصه شرح داده و در پایان با یکدیگر مقایسه میکنم.
MOLAP(Multidimensional Online Analytical Processing)
این نوع ذخیرهسازی بیشترین کاربرد در ذخیره اطلاعات را دارد همچنین به صورت پیش فرض جهت ذخیرهسازی اطلاعات انتخاب شده است. در این نوع تنها زمانی دادههای منتقل شده به Cube به روز میشوند که Cube پردازش شود که این امر باعث تاخیر بالا در پردازش و انتقال دادهها میشود.
ROLAP (Relational Online Analytical Processing)
در ذخیرهسازی ROLAP زمان انتقال بالا نیست که از مزایای این نوع ذخیرهسازی نسبت به MOLAP است. در ROLAP اطلاعات و پیشمحاسبهها (Aggregations) در یک حالت رابطهای ذخیره میشوند و این به معنای زمان انتقال نزدیک به صفر میان منبع داده (بانک اطلاعاتی رابطهای) و Cube میباشد. از معایب این روش میتوان به کارایی پایین آن اشاره کرد زیرا زمان پاسخ برای پرسوجوهای اجرا شده توسط کاربران طولانی است. دلیل این کارایی پایین بکار نبردن تکنیکهای ذخیرهسازی چند بعدی است.
HOLAP (Hybrid Online Analytical Processing)
این نوع ذخیرهسازی چیزی مابین دو حالت قبلی است. ذخیره اطلاعات با روش ROLAP انجام میشود، بنابراین زمان انتقال تقزیبا صفر است. از طرفی برای بالابردن کارایی، پیشمحاسبهها به صورت MOLAP انجام میگیرد در این حالت SSAS آماده است تا تغییری در اطلاعات مبداء رخ دهد و زمانی که تغییرات را ثبت کرد نوبت به پردازش مجدد پیشمحاسبهها میشود. با این نوع ذخیرهسازی زمان انتقال دادهها به Cube را نزدیک به صفر و زمان پاسخ برای اجرای کوئریهای کاربر را زمانی بین نوع ROLAP و MOLAP میرسانیم.
مقایسه انواع ذخیره سازی در جدول زیر نمایش داده شده است.
مدت زمان انتقال داده | سرعت اجرای کوئری | محل ذخیرهسازی پیشمحاسبات | محل ذخیرهسازی دادهها | |
بالا | بالا | Cube | Cube | MOLAP |
پایین | متوسط | Cube | بانک اطلاعاتی رابطهای | HOLAP |
پایین | پایین | بانک اطلاعاتی رابطهای | بانک اطلاعاتی رابطهای | ROLAP |
معرفی بخشهای مختلف Solution Explorer در SSAS
در SSAS قسمتهای مختلفی وجود دارد که هر کدام وظایف جداگانهای را بر عهده دارند. پیش از ایجاد یک پروژهی SSAS درSQL Server Business Intelligence Development Studio باید آگاهی کافی از اجزاء مختلف آنالیز سرویس داشته باشید. برای درک بهتر و آشنایی بیشتر با هر یک از این اجزاء ، در این پست سعی میکنم بخشهای مختلف SSAS را بطور خلاصه و به زبان ساده شرح دهم.
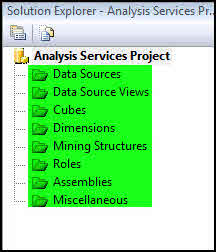
Data Sources
اولین قدم برای شروع یک پروژه، ایجاد منبع داده جهت دسترسی به اطلاعات است. برای این کار ازDate Source استفاده میکنیم. DTS توسط Providerهای مختلف این امکان را فراهم میکند تا با منبع دادههای مختلفی همچون SQL، Oracle و ... ارتباط برقرار کنیم.
Data Source Views
پس از آنکه ارتباط با منبع دادهها برقرار شد، جهت خواندن اطلاعات موجود در جداول و Viewها از DSV استفاده میشود. هر گونه تغییر در فیلدهای جداول هیچ گونه تاثیری در ساختار جداول نخواهد داشت و تغییرات اعمال شده تنها در SSAS قابل مشاهده و استفاده است.
Cubes
هر پروژهی OLAP در SSAS یک یا چند مکعب داده (Cube) را شامل میشود. این مکعبها در این قسمت تعریف میشوند. هر Cube خود شامل بخشهای مختلفی است که در پستهای بعدی به آن میپردازم.
Dimensions
به معنای بُعد میباشد که که ابعاد مختلف Cube را تشکیل میدهند. تمامی ابعاد یک پروژه در این قسمت تعریف میشوند.
Mining Structures
برای ساخت پروژههای داده کاوی و استفاده از مدلهای مختلف دادهکاوی باید از این قسمت استفاده کرد.
Roles
مسائل امنیتی مانند نقشها و دسترسیها برای OLAP و Data Mining در این قسمت مدیریت میشوند. این دسترسیها میتوانند بر روی Cubeها، Dimensionها و Mining Structureها اعمال شوند.
Assemblies
در SSAS از زبانهای برنامه نویسی MDX و DMX جهت نوشتن عبارات استفاده میشود. گاهی نیاز است که از سایر زبانهای برنامه نویسی نیز در این عبارات استفاده شود. جهت استفاده از این توابع در عبارات MDX و DMX از این قسمت استفاده میشود.
Miscellaneous
در صورتی که در SSAS فایل خاصی را اضافه کرده باشیم، در این قسمت دسته بندی میشود. این فایلها از هر نوعی میتوانند باشند.