هوش تجاری (Business Intelligence)
به اشتراک بگذاریم برای یادگیری، یاد بگیریم برای به اشتراک گذاریهوش تجاری (Business Intelligence)
به اشتراک بگذاریم برای یادگیری، یاد بگیریم برای به اشتراک گذاریمراحل کلی در انجام عملیات داده کاوی
میتوان گفت دادهکاوی هدف اصلی و نهایی سازمانها در بکارگیری از BI است. انجام عمل دادهکاوی علاوه بر تخصص و توانایی فنی بالا و تسلط به کسب و کار مربوطه نیازمند مقدمات دیگری نیز هست و تا فراهم نشدن تمامی این مقدمات امکان پذیر نمیباشد. در ادامه هر یک از این پیش نیازها را بررسی میکنیم.
طراحی و پیاده سازی انبار داده:
بدون وجود انبار دادهای جامع و دقیق نمیتوان به سوی داده کاوی قدم برداشت. پیش از انجام هر نوع عمل کاوش در دادهها ابتدا باید از یکپارچگی، صحت و تجمیع اطلاعات اطمینان حاصل شود. اطلاعات باید واقعی و دارای توالی به روز رسانی مشخص باشند. مراحل پیاده سازی انبار داده در اینجا شرح داده شده است.
بررسی و انتخاب دادهها بر اساس نوع الگوریتم مورد استفاده:
فارغ از اینکه از چه ابزاری برای عملیات داده کاوی استفاده میکنیم، تعداد الگوریتمها، تنوع و مقاصد آنها متفاوت است. از این رو باید بر اساس نوع الگوریتمی که قصد استفاده از آن را داریم اطلاعات را انتخاب نماییم. الگوریتمهای داده کاوی در اینجا شرح داده شده است.
تبدیل دادهها به فرمت و ساختار مورد نیاز الگوریتم:
هر الگوریتم داده کاوی بر اساس نوع خروجی و هدفی که دنبال میکند به فرمت خاص خود نیاز دارد. در این مرحله باید دادههای مورد نیاز الگوریتم را به شکل و قالب قابل قبول برای الگوریتم تبدیل کنیم. انواع دادهای مورد استفاده در Microsoft Data Mining را اینجا مطالعه کنید.
کاوش در داده با استفاده از الگوریتمهای داده کاوی:
در این مرحله کار را به الگوریتم انتخاب شده میسپاریم. الگوریتم بر اساس پارامترها و ورودیهای مشخص شده شروع به کاوش در دادهها میکند و روابط و اطلاعات مورد نیاز جهت رسیدن به دانش را در اختیار ما قرار میدهد.
در این رابطه میتوانید الگوریتم کلاسترینگ و سری زمانی را مطالعه نمایید.
تحلیل و تفسیر نتیجه :
بدیهی است که کسب دانش از دادهها نیازمند تجزیه و تحلیل و تفسیر خروجی مرحله قبل است. رسیدن به نتیجه مطلوب در کنار تلاش تیمی متشکل از افراد فنی و غیر فنی که تسلط کامل برروی اطلاعات و کسب وکار دارند میسر است.
برقراری ارتباط کلیک ویو با Cube
اگر قصد داشته باشید تا از اطلاعات ذخیره شده در Cube توسط QlikView گزارش و یا داشبورد ایجاد کنید، باید پس از برقراری ارتباط میان این دو توسط کانکتور OLEDB، از عبارات MDX برای فراخوانی جداول حقایق و ابعاد استفاده کنید.
استفاده از تمامی Factها و Dimensionها در کلیک ویو نیازمند عبارات MDX پیشرفته و پیچیده است، به همین دلیل پیشنهاد میشود در صورت امکان، ارتباط کلیک ویو با انبار داده را به صورت مستقیم برقرار نمایید.
در این آموزش فرض بر آماده بودن یک مدل OLAP برروی سیستم شما است.
توجه: از آنجایی که در این آموزش از پایگاه داده AdventureWorksDW2008 استفاده شده است، باید آن را به بانک اطلاعاتی خود اضافه نمایید. پیشتر نحوه استفاده از AdventureWorksDW2008 در اینجا شرح داده شده است.
به منظور انجام این کار مراحل زیر را دنبال کنید.
1- ابتدا باید یک پروژهی OLAP ایجاد و سپس آن را Deploy و پردازش کرد تا بانک اطلاعاتی آن در Analysis Services قرار گیرد.
برای این کار میتوانید از Adventure Works Sample نیز استفاده نمایید.
2- به صفحهی Edit Script در qlikview رفته و از قطعه کد زیر جهت برقراری ارتباط با Analysis Services استفاده نمایید.
OLEDB CONNECT TO [Provider=MSOLAP.5;Integrated Security=SSPI;Persist Security Info=False;Initial Catalog=نام بانک اطلاعاتی;Data Source=نام سرور];
قطعه کد بالا ارتباط Cube با qlikview را برقرار میکند.
3- برای خواندن جداول ابعاد و حقایق باید از عبارات MDX استفاده شود. برای مثال عبارت MDX زیر معیار Internet Sales Amount و اطلاعات جداول Ship Date و Product را به QlikView اضافه میکند.
SELECT NON EMPTY {[Measures].[Internet Sales Amount] } ON COLUMNS, NON EMPTY
{ ([Ship Date].[Date].[Date].members* [Product].[Category].[Category].members)}
DIMENSION PROPERTIES MEMBER_CAPTION, MEMBER_UNIQUE_NAME ON ROWS FROM [Adventure Works]
CELL PROPERTIES VALUE, BACK_COLOR, FORE_COLOR, FORMATTED_VALUE, FORMAT_STRING, FONT_NAME, FONT_SIZE, FONT_FLAGS
تصویر زیر نحوه قراگرفتن قطعه کدهای بالا در محیط اسکریپت نویسی کلیک ویو را نشان میدهد.
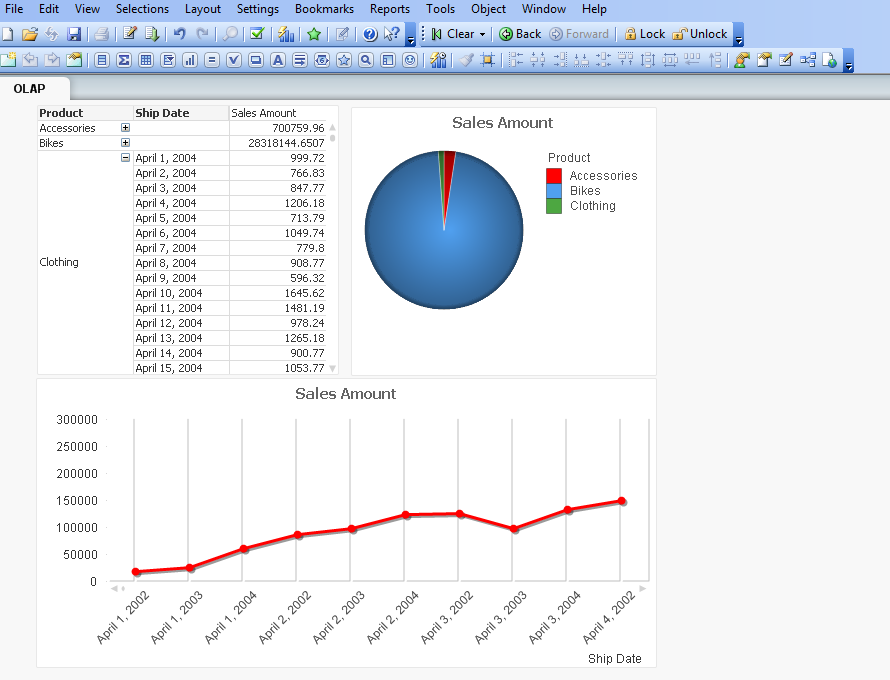
همانطور که در تصویر زیر ملاحظه میکنید، دو نمودار و یک جدول از اطلاعات موجود در Cube ایجاد شده است. نمودار دایرهای بیانگر مبلغ فروش به تفکیک محصول، نمودار خطی، روند فروش محصولات در بازه زمانی و جدول نیز مبلغ فروش محصولات به تفکیک محصول و تاریخ فروش نمایش میدهد.
OLAP به زبان ساده
OLAP مجموعهای از مکعبها (Cubes) است. داخل این مکعبها دادههایی قرار دارند که از پیش انتخاب شدهاند. ارتباطات بین ابعاد از قبل تعریف شده و همه ابعاد (نتایج) از قبل محاسبه و پیشبینی شده است. هنگامی که یک مکعب ایجاد میشود، یک واسط کاربر نهایی که میتواند یک داشبورد باشد برای یک فرد واقعی پیادهسازی میشود که کاربر نهایی(مدیران و تصمیم گیرندگان سازمان) بتواند با جوابهای داخل مکعب تعامل داشته باشد.
اما فرض کنید در یک مکعب برای تحلیل فروش در یک سازمان مقدار و مبلغ فروش را بر اساس ابعادِ مناطق فروش، فروشنده (بازاریاب)، مشتری و ماه یا سال داشته باشیم. زمانی که این مکعب فرضی ساخته میشود، نرمافزار مبتنی بر OLAP کلیه ترکیبات عناصر دادهها را محاسبه و ذخیره میکند، کاربر نهایی به این دادهها از طریق داشبوردها و یا یک سری فرمها مثلا Pivot Table ها یا انواع دیگر فرمها دسترسی خواهد داشت.
در این مثال فرضی کاربر نهایی محدود به تحلیل در محدوده ابعاد از قبل تعریف شده مثل مناطق، نمایندگیها، مشتریها و ماه است. اگر کاربر بخواهد درباره فروش هفتگی، روزهای هفته یا محصولات فروخته شده (و یا صدها ترکیب دیگر از دادهها) اطلاعاتی کسب کند دیگر شانسی برای بدست آوردن آن ندارد، باید صبر کند که مکعب دیگری از اطلاعات مورد نیاز او ایجاد شود که این یعنی محدودسازی و کاهش بهرهوری و اثربخشی برای تصمیمگیران آن سازمان. به عبارت دیگر کاربر نهایی باید نیازهای خود را از پیش شناخته و برای این نیازها Cubeها، جداول حقایق (Fact) و ابعاد (Dimension) مورد نیاز را پیاده سازی کند تا با کنار هم قرار دادن گزارشات مختلف تا حدودی به دانش استخراج شده و مورد نیاز خود دست پیدا کند.OLAP برخی از قابلیتهای تحلیل را فراهم میکند، اما تقریبا میتوان گفت در کشورهای پیشرفته یک رویکرد قدیمی است و متاسفانه در کشور ما همچنان ناشناخته! یا کمتر شناخته شده است. در حال حاضر انواع مختلف OLAPوجود دارد، مثل MultiDimensiona OLAP (MOLAP) که به آن MMD نیز گفته میشود و Relational OLAP (ROLAP) یاRDBMS و سیستم های OLAP از نوع
HOLAP.
در پست جداگانه به تشریح انواع OLAP و مقایسه آنها میپردازم.
دسته بندی الگوریتم های داده کاوی
از دادهکاوی برای کاوش در اطلاعات و بدست آوردن دانش استفاده میشود. برای اینکار الگوریتمهای زیادی وجود دارد که هر یک برای هدف خاصی کاربرد دارند. در SQL Server Business Intelligence Development Studioتعداد 9 الگوریتم مختلف برای انجام عمل دادهکاوی وجود دارد که در پنج دسته کلی به شرح زیر تقسیم میشوند.
الگوریتمهای طبقهبندی(Classification algorithms)
در این نوع از الگوریتمها پیش بینی بر اساس یک یا چند متغیر گسسته بر روی سایر ویژگیهای موجود در مجموعه دادهها انجام میشود.
الگوریتمهای رگرسیون(Regression algorithms)
در این نوع از الگوریتمها پیش بینی بر اساس یک یا چند متغیر پیوسته بر روی سایر ویژگیهای موجود در مجموعه دادهها میشوند.
الگوریتمهای دستهبندی(Segmentation algorithms)
این الگوریتمها اطلاعات را به چند گروه یا خوشه تقسیم میکنند. هر گروه ویژگیهای مشابه دارد.
الگوریتمهای وابستگی(Association algorithms)
ارتباط میان ویژگیهای مختلف موجود در مجموعه دادهها از طریق این الگوریتم کشف میشود. از این الگوریتم بیشتر در تجزیه و تحلیل سبد خرید کالا استفاده میشود.
الگوریتمهای تحلیل زنجیرهای(Sequence analysis algorithms)
این نوع الگوریتمها نتیجهی رویدادهای خاص را دنبال میکنند. مانند دنبال کردن رخدادهای آدرس یک سایت اینترنتی.
لازم به ذکر است که تعاریف و دستهبندیهای بالا دلیلی برای محدود کردن استفاده از یک الگوریتم نیست. معمولا در یک تحلیل خوب از یک الگوریتم برای تعیین ورودیهای موثر و از الگوریتمهای دیگر برای بدست آوردن پیش بینیهای مناسب در خروجی استفاده میشود. برای مثال، در یک مدل دادهکاوی میتوانید از الگوریتمهای خوشهبندی، درخت تصمیم و بیز جهت بررسی دادهها از جهات مختلف و کشف دانش استفاده کرد.
MOLAP، ROLAP و HOLAP
در یک پروژهی OLAP از یک یا چند مکعب داده (Cube) استفاده میشود. از اینرو Cube به عنوان یکی از مزایای پروژه هوش تجاری شناخته میشود. قرار گرفتن دادهها در یک فرمت بهینه جهت ذخیرهسازی به انجام سریعتر کوئریها میانجامد. معمولا نحوه ذخیرهسازی اطلاعات حجیم در Cube باعث تاخیر در ذخیره و بازیابی انبوه اطلاعات میشود. به طور معمول در SSAS پردازش دادهها از یک بانک اطلاعاتی رابطهای به Cube منتقل میشود. پس از اتمام این ارتباط نه چندان طولانی میان پایگاه دادههای رابطهای و Cube اطلاعات وارد Cube میشوند و با تغییر دادهها در پایگاه داده هیچ تغییری در اطلاعات موجود در Cube ایجاد نمیشود مگر آنکه Cube را مجدد پردازش کنید.
در SSAS2008 سه نوع ذخیرهسازی وجود دارد؛ MOLAP، ROLAP و HOLAP
در این پست هر یک از انواع ذخیرهسازی را به صورت خلاصه شرح داده و در پایان با یکدیگر مقایسه میکنم.
MOLAP(Multidimensional Online Analytical Processing)
این نوع ذخیرهسازی بیشترین کاربرد در ذخیره اطلاعات را دارد همچنین به صورت پیش فرض جهت ذخیرهسازی اطلاعات انتخاب شده است. در این نوع تنها زمانی دادههای منتقل شده به Cube به روز میشوند که Cube پردازش شود که این امر باعث تاخیر بالا در پردازش و انتقال دادهها میشود.
ROLAP (Relational Online Analytical Processing)
در ذخیرهسازی ROLAP زمان انتقال بالا نیست که از مزایای این نوع ذخیرهسازی نسبت به MOLAP است. در ROLAP اطلاعات و پیشمحاسبهها (Aggregations) در یک حالت رابطهای ذخیره میشوند و این به معنای زمان انتقال نزدیک به صفر میان منبع داده (بانک اطلاعاتی رابطهای) و Cube میباشد. از معایب این روش میتوان به کارایی پایین آن اشاره کرد زیرا زمان پاسخ برای پرسوجوهای اجرا شده توسط کاربران طولانی است. دلیل این کارایی پایین بکار نبردن تکنیکهای ذخیرهسازی چند بعدی است.
HOLAP (Hybrid Online Analytical Processing)
این نوع ذخیرهسازی چیزی مابین دو حالت قبلی است. ذخیره اطلاعات با روش ROLAP انجام میشود، بنابراین زمان انتقال تقزیبا صفر است. از طرفی برای بالابردن کارایی، پیشمحاسبهها به صورت MOLAP انجام میگیرد در این حالت SSAS آماده است تا تغییری در اطلاعات مبداء رخ دهد و زمانی که تغییرات را ثبت کرد نوبت به پردازش مجدد پیشمحاسبهها میشود. با این نوع ذخیرهسازی زمان انتقال دادهها به Cube را نزدیک به صفر و زمان پاسخ برای اجرای کوئریهای کاربر را زمانی بین نوع ROLAP و MOLAP میرسانیم.
مقایسه انواع ذخیره سازی در جدول زیر نمایش داده شده است.
مدت زمان انتقال داده | سرعت اجرای کوئری | محل ذخیرهسازی پیشمحاسبات | محل ذخیرهسازی دادهها | |
بالا | بالا | Cube | Cube | MOLAP |
پایین | متوسط | Cube | بانک اطلاعاتی رابطهای | HOLAP |
پایین | پایین | بانک اطلاعاتی رابطهای | بانک اطلاعاتی رابطهای | ROLAP |