هوش تجاری (Business Intelligence)
به اشتراک بگذاریم برای یادگیری، یاد بگیریم برای به اشتراک گذاریهوش تجاری (Business Intelligence)
به اشتراک بگذاریم برای یادگیری، یاد بگیریم برای به اشتراک گذاریساخت پارتیشن برای Cube
همانطور که پیشتر گفته شد، سه روش MOLAP، ROLAP و HOLAP برای ذخیرهسازی اطلاعات در Cube وجود دارد.
در روش ذخیره سازی MOLAP، دادههای جدیدی که وارد انبار داده میشوند در صورتی به Cube منتقل میشوند که مجدد پردازش شوند. گاهی ممکن است حجم اطلاعات بسیار زیاد باشد که این مسئله باعث طولانی شدن مدت زمان پردازش میشود. طولانی شدن مدت زمان پردازش علاوه بر حجم زیاد اطلاعات دلیل دیگری نیز دارد و آن پردازش تمامی اطلاعات موجود در انبار داده است. برای رفع این مشکل باید از قابلیت پارتیشن بندی Cube استقاده کنیم. اما باید پارتیشن را طوری طراحی کرد که به صورت داینامیک و بدون دخالت کاربر عمل ایجاد پارتیشن جدید انجام گیرد. به همین منظور در این مقاله به آموزش قدم به قدم و چگونگی ایجاد پارتیشن پویا (Dynamic) میپردازم.
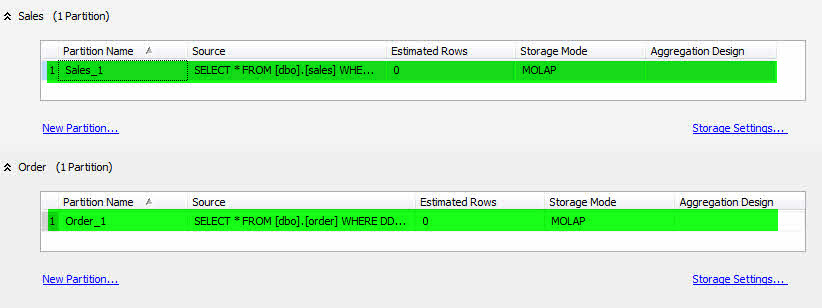
در این آموزش فرض بر وجود دو گروه معیار (Measure Group) با نام های Sales و Order است.
- پس از ایجاد Cube در SSAS به سربرگ Partition رفته و پارتیشنهای ایجاد شده را حذف کنید.
- برروی NewPartition.. مربوط به Sales کلیک کرده و پارتیشن جدیدی با نام Sales_1 ایجاد نمایید.
- کوئری موجود در پارتیشن را مطابق کد زیر قرار دهید.
SELECT * FROM [dbo].[sales] WHERE DDate>='1383/01/01' and DDate<'1383/01/10'
- همین کار را برای Order انجام دهید و در پایان نام آن را Order_1 قرار دهید.
حال Cube را پردازش کرده و از SSAS خارج شوید.
-مطابق تصویر زیر در بر رویMicrosoft Analysis Services Sales_1 راست کلیک کنید و یک ((اسکریپتِ ایجاد)) ساخته و با نام CreatePartition-Sales_1 ذخیره نمایید.
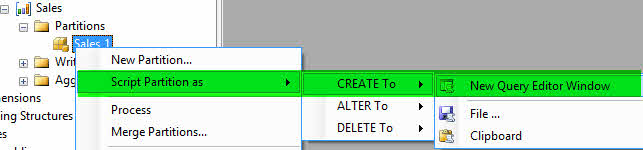
-مجدد بر روی Sales_1 کلیک راست کرده و Process را انتخاب کنید.
-در صفحهی باز شده بر روی Script کلیک کنید تا کد XML مربوط به پردازش نمایش داده شود. کد را با نام ProcessPartition-Sales_1 ذخیره نمایید.
-مراحل بالا را برای Order_1 انجام دهید. از نامهای CreatePartition-Order _1 و ProcessPartition-Order _1 برای ذخیره فایلهای XML استفاده کنید.
مطابق شکل زیر یک جدول با عنوان PartitionsLog ایجاد کنید.
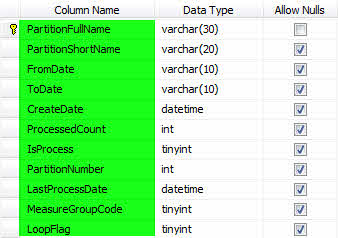
سه رویه زیر را دریافت و ایجاد کنید.
دومین SP برای دریافت
اطلاعات پارتیشنهای قبلی جهت ساخت پارتیشن جدید ایجاد شده است.
سومین SP وظیفه ثبت اطلاعات پارتیشن جدید در PartitionsLog را دارد.
تا به اینجای کار مراحل اولیه آماده سازی شد، از این پس در SSIS به ایجاد یک Package برای ایجاد پارتیشن میپردازیم.
یک پروژهی SSIS با نام Partition ایجاد کرده و مطابق شکل زیر در قسمت Variable متغیرها را تعریف نمایید.
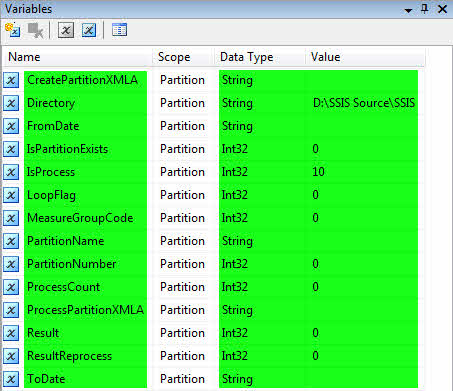
در جدول زیر شرح مختصری از وظیفه متغیرها آمده
|
برای ساخت XMLA جدید از آن استفاده میشود. |
CreatePartitionXMLA |
|
آدرس فایلهای XMLA که پیشتر ساخته شده را در خود دارد. |
Directory |
|
مشخص کننده تاریخ شروع اطلاعات موجود در پارتیشن است. |
FromDate |
|
نشان دهنده وجود داشتن/ نداشتن پارتیشن است. |
IsPartitionExists |
|
نشان دهنده پارتیشن پردازش شده / پارتیشن پردازش نشده است. |
IsProcess |
|
اطلاعات مربوط به تکرار را در خود ذخیره میکند. |
LoopFlag |
|
کد گروه معیار را در خود جای میدهد. |
MeasureGroupCode |
|
نام پارتیشن در این متغیر قرار میگیرد. |
PartitionName |
|
شماره پارتیشن در این متغیر قرار میگیرد. |
PartitionNumber |
|
تعداد دفعات پردازش یک پارتیشن در این متغیر قرار میگیرد. |
ProcessCount |
|
جهت پردازش پارتیشن از این متغیر استفاده میشود. |
ProcessPartitionXMLA |
|
خروجی SP دوم که برای پردازش مجدد استفاده میشود در این متغیر قرار میگیرد. |
Result |
|
نتیجه پردازش مجدد |
ResultReprocess |
|
اطلاعات موجود در Fact تا این تاریخ در پارتیشن ثبت میشود. |
ToDate |
-مطابق شکل زیر 11 عدد Execute SQL Task، یک Analysis Services Processing Task، 2عدد For Loop Container، 4 عدد Analysis Services Execute DDL Task و 4 عدد Script Task به پروژه اضافه کرده و به هم متصل کنید.
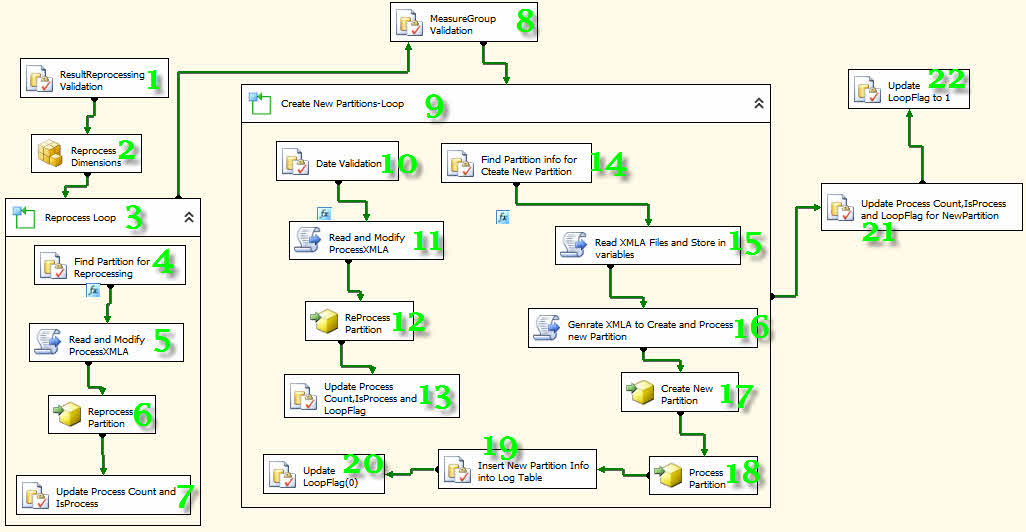
با توجه به شمارههای قرار گرفته بر روی هر کامپننت توضیحاتی میدهم که باید قدم به قدم اجرا شود.
1- رویه Findisprocess را فراخوانی کرده تا اطلاعات پارتیشنهایی که فیلد IsProcess آنها صفر است در متغیرها قرار گیرد.
2- تمامی دایمنشنها را پردازش میکند.
3- برای پردازش مجدد تمامی پارتیشنها، یک حلقه ایجاد میکند و تا زمانی که نتیجه پردازش 1 است به کار خود ادامه میدهد.
4- رویه Findisprocess را فراخوانی کرده تا تمامی اطلاعات مربوط به پارتیشن را دریافت کند.
5- توسط این کامپننت میتوانیم از زبانهای برنامه نویسی C# و VB در پکیج استفاده کنیم. توسط مجموعه کدهای نوشته شده در این قسمت تغییرات مورد نیاز جهت پردازش مجدد اعمال میشوند.
کدهای مربوط به کامپننتهای Script Task شماره 5 را از اینجا دریافت کنید.
6- پارتیشن مورد نظر را پردازش میکند.
7- فیلدهای موجود در PartitionsLog بروزرسانی میشوند.
8- گروه معیارها شناسایی میشوند.
9- از آنجایی که دو گروه معیار داریم، برای ایجاد پارتیشن به یک حلقه نیاز داریم. در این حلقه ابتدا در صورت نیاز آخرین پارتیشنها پردازش میشوند و سپس پارتیشنهای جدید ایجاد میشوند.
10- تمامی اطلاعات مورد نیاز برای پردازش مجدد پارتیشن دریافت میشود.
11- تغییرات مورد نیاز جهت پردازش مجدد اعمال میشوند.
کدهای مربوط به کامپننت Script Task شماره 11 را از اینجا دریافت کنید.
12- پارتیشن مورد نظر را پردازش میکند.
13- فیلدهای موجود در PartitionsLog بروزرسانی میشوند.
14- تمامی اطلاعات مورد نیاز برای ایجاد و پردازش پارتیشن دریافت میشود.
15- فایلهای XMLA ایجاد شده در ابتدای پروژه را بازخوانی و متغیرهای مربوطه را بارگذاری میکند.
کدهای مربوط به کامپننت Script Task شماره 15 را از اینجا دریافت کنید.
16- اطلاعات مورد نیاز برای ایجاد و پردازش پارتیشن را آماده میکند.
کدهای مربوط به کامپننت Script Task شماره 16 را از اینجا دریافت کنید.
17- پارتیشن جدید را ایجاد میکند.
18- پارتیشن ایجاد شده را پردازش میکند.
19- اطلاعات مربوط به پارتیشن جدید توسط رویه InsertNewPartitionInfo ثبت میشود.
20- مقدار فیلد LoopFlag را به صفر تغییر میدهد. دلیل اینکار جلوگیری از تکرار بیدلیل در پردازش پارتیشن است.
21- اطلاعات تکمیلی پارتیشن جدید را بروزرسانی میکند.
22- مقدار فیلد LoopFlag را به یک تغییر میدهد. دلیل اینکار فراهم نمودن شرایط تکرار در پردازش پارتیشن در صورت لزوم است.
کار تمام است! حال میتوانید از Package خود استفاده کنید.
لازم به ذکر است که با کمی کار بیشتر و ایجاد تغییرات جزئی میتوان این پکیج را بهینه کرد.
شروع به کار با SSIS
در مقاله SSIS و کاربرد آن در پروژه به معرفی SSIS پرداخته شد و همچنین در مقالات دیگری (اینجا) با چند نمونه عملی به شرح بهتر و بیشتر آن پرداخته شد. اما اگر نیاز به آموزش قدم به قدم مفاهیم ابتدایی SSIS دارید می توانید از ماکروسافت کمک بگیرید.
ETL چیست؟
ETL مخفف Extract Transform and Load است که به معنای استخراج، پالایش و بارگذاری اطلاعات میباشد. از ETL در زمان ساخت انبار دادهها (Data Warehouse) استفاده میشود. فرایندی که به موجب آن اطلاعات از یک یا چند منبع مختلف جمع آوری، پالایش و در نهایت در انبار داده بارگذاری میشود.نمیتوان ETL و Data Warehouse را از یکدیگر جدا کرد. در واقع با انجام ETL، تحلیل و طراحی انجام گرفته برای Warehouse به ثمر میرسد. پیشتر در مقاله " مراحل و نحوه بارگذاری داده ها در انبار داده " به ETL پرداخته شده بود. در این مقاله به تشریح مراحل و ابزارهای ETL میپردازم.
Extract: منظور استخراج داده از یک یا چند منبع مختلف است. پس از آنکه تحلیل و طراحی مدل Warehouse به پایان رسید، نوبت به بارگذاری دادهها در آن میرسد. اما بارگذاری دادهها تابع قوانین خاصی هستند و باید به آنها توجه شود. ابتدا باید منابعی که قرار است اطلاعات آنها را در Warehouse داشته باشیم شناسایی کنیم و پس از آن دادهها را در یک محیط واسط قرار دهیم. این عملیات میتواند توسط یکی از ابزارهای ETL و یا Stored Procedureها، Functionها و کوئریها انجام گیرد. منظور از محیط واسط یک بانک اطلاعاتی است که میان انبار دادهها و منابع داده قرار گیرد. دلیل استفاده از محیط واسط این است که معمولا دادههای منبع نیاز به پالایش دارند که اولا این پالایش نباید در منبع دادهها انجام گیرد و دوما اطلاعاتی که در Warehouse بارگذاری میشوند باید به صورت پالایش شده باشد. باید در زمان استخراج، دادهها را از منابع مختلف جمع آوری و در یک محیط واسط قرار دهیم.
Transform: منظور پالایش دادههای استخراج شده است. پالایش دادهها بسیار مهم است چرا که بعد از پالایش دادهها باید آنها را در انبار داده بارگذاری کرد. برای این کار از یک محیط واسط که کم و بیش شبیه انبار داده است استفاده میشود. پالایش دادهها شامل موارد زیر است.
· بررسی کیفیت دادهها (Verify data quality)
کیفیت دادهها به وسیله پرسشهایی از قبیل سوالات زیر مورد بررسی قرار میگیرند:
آیا دادهها کامل هستند (مواردی مورد نیازمان را پوشش میدهند)؟
دادهها صحیح هستند یا اشتباهاتی دارند؟ اگر اشتباه هستند علت اشتباهات چیست؟
آیا ارزشهای گم شده در داده وجود دارد؟ اگر اینگونه است آنها چگونه نمایش
داده میشود؟ عموماً در کجا اتفاق افتاده است؟
· پاکسازی دادهها (Clean data)
بالا بردن کیفیت دادهها نیازمند انتخاب تکنیک آنالیز میباشد. این انتخاب شامل پاک کردن زیر مجموعهای از دادههای نامناسب و درج پیشفرضهای مناسب میباشد.
· شکل دادن دادهها (Construct data)
این قسمت شامل عملیات ویژهای مانند تولید خصوصیتهای مشتق شده، تولید رکوردهای جدید و کامل یا مقادیر تبدیل شده از خصوصیات موجود میباشد.
· ادغام دادهها (Integrate data)
روشهایی وجود دارد که به وسیله آن اطلاعات از چند جدول ترکیب شده و رکوردهای جدید یا مقادیری جدیدی ایجاد میشود.
· قالب بندی دادهها (Format data)
منظور از قالب بندی دادهها، تغییر و تبدیل قواعد اولیه داده مورد نیاز ابزار مدل سازی می باشد.
Load: آخرین کاری که در ETL انجام میگیرد بارگذاری دادههای استخراج و پالایش شده از منابع مختلف در انبار دادهها است. معمولا در زمان بارگذاری در انبار داده تغییرات خاصی روی دادهها انجام نمیگیرد و آنها بدون هیچ تغییری از محیط واسط در انبار دادهها بارگذاری میشوند.
یکی از بهترین و قویترین ابزارها برای عملیات ETL، ابزار SSIS است که استفاده از آن سرعت و دقت در عملیات را بالا میبرد.
تبدیل تاریخ شمسی به میلادی،میلادی به شمسی ومیلادی به قمری در SQL
با کمی جستجو در اینترنت مشاهده خواهید کرد که توابع زیادی برای تبدیل تاریخ وجود دارد اما برخی از آنها یا کامل نیستند و یا اشکالاتی دارند. در این پست توابع تبدیل تاریخ شمسی به میلادی، میلادی به شمسی و میلادی به قمری را در کنار هم قرار دادهام. در نهایت نیز یک تابع جهت بدست آوردن سن افراد از تاریخ تولدشان معرفی شده است. این توابع برای تبدیل در بعضی تاریخ ها مشکلاتی داشتند که با یادآوری خوانندگان بلاگ رفع شد.
لازم به ذکر است که تابع تبدیل تاریخ میلادی به شمسی توسط آقای رضا راد نوشته شده است.
توابع تبدیل تاریخ میلادی به شمسی و شمسی به میلادی را از اینجا دریافت کنید.
پس از دانلود و اجرای کوئری ها، از طریق دستورات زیر میتوانید تبدیل تارخ میلادی به شمسی و شمسی به میلادی را انجام دهید.
از کوئری زیر برای مشاهده نتیجه استفاده کنید.
select dbo.GregorianToPersian('1980/01/01')
select dbo.ShamsitoMiladi('1358/10/11')
تبدیل تاریخ میلادی به قمری
از دستور زیر برای تبدلی تاریخ میلادی به قمری استفاده کنید.
SELECT CONVERT (nvarchar(30),GETDATE(),130) as Date
برای بدست آوردن سن از دستور زیر استفاده کنید.
SELECT DateDiff(yy , (select dbo.ShamsitoMiladi ('1365/01/01') ), GetDate())
داده کاوی و OLAP - مکمل یا متفاوت با هم؟
تکنیکهای بسیاری جهت جمع آوری ، پالایش و آنالیز داده ها نظیر OLAP و Data Mining با هدف استخراج اطلاعات از رکوردهای عملیاتی سازمان و نظم دهی آن به منظور انجام تحلیل های مختلف وجود دارد.
یکی از متداولترین سوالات در حوزه پردازش دادهها به صورت حرفهای در مورد تفاوت داده کاوی و OLAP میباشد. این دو ابزار در عین حال که تفاوتهایی با هم دارند مکمل یکدیگر نیز میباشند.
کاربر در مورد یک رابطه و تائید آن با مجموعهای از پرس و جوها در مقابل دادهها، به شکل یک فرضیه روبرو است. به عنوان مثال ممکن است تحلیلگر بخواهد تا عواملی که سبب ناتوانی در بازپرداخت بدهی وام منجر میگردد را تجزیه و تحلیل نماید.
در تجزیه و تحلیل پایگاه داده OLAP ابتدا ممکن است این گونه فرض شود که افرادی که در اعتبارات مالی درآمد پایین و ریسک بالا دارند، نتوانند بدهی خود را پرداخت کنند و فرضیه افراد کم درآمد و کم اعتبار تائید (و یا رد) شود.
اگر فرضیه توسط دادهها تصدیق نشد تحلیلگر ممکن است به بدهی بالا به عنوان عامل منجر به ریسک نگاه کند. اگر این مطلب را دادهها نیز تایید نکنند او ممکن است بدهی و درآمد را با هم به عنوان بهترین نمایانگر ریسک اعتبار مالی بد در نظر بگیرد.
به عبارت دیگر OLAP یک تجزیه و تحلیلی از مجموعهای از فرضیهها تولید کرده و پارامترها و ارتباطات را برای استفاده به سمت کوئری های پایگاه داده برای تائید یا رد آنها ارسال میکند. تجزیه و تحلیلهای OLAP برای پردازشهای استنتاجی یک ضرورت است.
داده کاوی با OLAP تفاوت دارد زیرا الگوهای فرضیهها را سریعتر تائید میکند، با استفاده از همان دادهها به کشف الگوهای همانند میپردازد و همچنین برای پردازشهای استنتاجی ضروری میباشد. برای مثال فرض کنید شخصی قصد داشته باشد تا فاکتورهای همراه با ریسک جهت وام گرفتن را با استفاده از داده کاوی تجزیه و تحلیل و شناسایی کند. ممکن است ابزارهای داده کاوی اشخاص با بدهی بالا، درآمد پایین و اعتبار مالی بد را کشف کنند. این نوع تجزیه و تحلیل ممکن است از موارد تاثیرگذار دیگری چشم پوشی کند. بعنوان مثال سن می تواند یک عامل تعیین کننده در بازپرداخت وام باشد.
اینجا جایی است که داده کاوی و OLAP میتوانند یکدیگر را کامل کنند. قبل از کار بر روی الگو و تجزیه و تحلیل بر روی اطلاعات، نیاز به دانستن پیامدهای مالی و همچنین خواستار کشف الگوهایی برای کنترل اعتبار کافی اشخاص میباشیم. تکنولوژی OLAP میتواند به این قسمت از سوال پاسخ دهد. در OLAP با استفاده از MDX و با دقت و تمرکز خود بر روی مقادیر مهم میتواند استثناها را شناسایی و یا تعاملات را کشف کند.