هوش تجاری (Business Intelligence)
به اشتراک بگذاریم برای یادگیری، یاد بگیریم برای به اشتراک گذاریهوش تجاری (Business Intelligence)
به اشتراک بگذاریم برای یادگیری، یاد بگیریم برای به اشتراک گذاریساخت پارتیشن برای Cube
همانطور که پیشتر گفته شد، سه روش MOLAP، ROLAP و HOLAP برای ذخیرهسازی اطلاعات در Cube وجود دارد.
در روش ذخیره سازی MOLAP، دادههای جدیدی که وارد انبار داده میشوند در صورتی به Cube منتقل میشوند که مجدد پردازش شوند. گاهی ممکن است حجم اطلاعات بسیار زیاد باشد که این مسئله باعث طولانی شدن مدت زمان پردازش میشود. طولانی شدن مدت زمان پردازش علاوه بر حجم زیاد اطلاعات دلیل دیگری نیز دارد و آن پردازش تمامی اطلاعات موجود در انبار داده است. برای رفع این مشکل باید از قابلیت پارتیشن بندی Cube استقاده کنیم. اما باید پارتیشن را طوری طراحی کرد که به صورت داینامیک و بدون دخالت کاربر عمل ایجاد پارتیشن جدید انجام گیرد. به همین منظور در این مقاله به آموزش قدم به قدم و چگونگی ایجاد پارتیشن پویا (Dynamic) میپردازم.
در این آموزش فرض بر وجود دو گروه معیار (Measure Group) با نام های Sales و Order است.
- پس از ایجاد Cube در SSAS به سربرگ Partition رفته و پارتیشنهای ایجاد شده را حذف کنید.
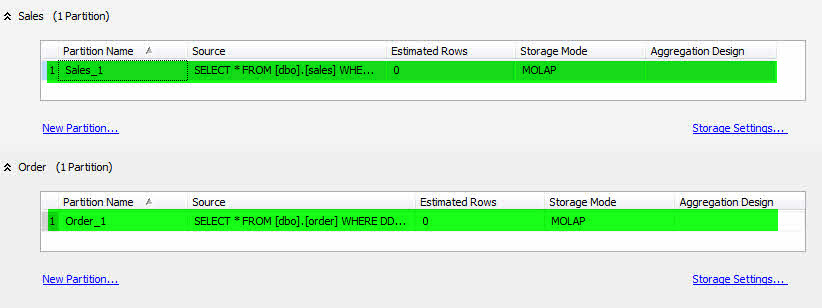
- برروی NewPartition.. مربوط به Sales کلیک کرده و پارتیشن جدیدی با نام Sales_1 ایجاد نمایید.
- کوئری موجود در پارتیشن را مطابق کد زیر قرار دهید.
SELECT * FROM [dbo].[sales] WHERE DDate>='1383/01/01' and DDate<'1383/01/10'
- همین کار را برای Order انجام دهید و در پایان نام آن را Order_1 قرار دهید.
حال Cube را پردازش کرده و از SSAS خارج شوید.
-مطابق تصویر زیر در بر رویMicrosoft Analysis Services Sales_1 راست کلیک کنید و یک ((اسکریپتِ ایجاد)) ساخته و با نام CreatePartition-Sales_1 ذخیره نمایید.
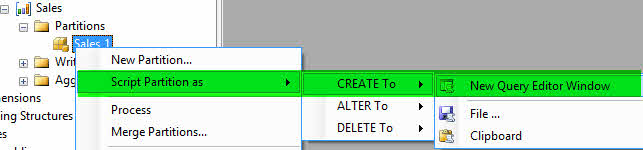
-مجدد بر روی Sales_1 کلیک راست کرده و Process را انتخاب کنید.
-در صفحهی باز شده بر روی Script کلیک کنید تا کد XML مربوط به پردازش نمایش داده شود. کد را با نام ProcessPartition-Sales_1 ذخیره نمایید.
-مراحل بالا را برای Order_1 انجام دهید. از نامهای CreatePartition-Order _1 و ProcessPartition-Order _1 برای ذخیره فایلهای XML استفاده کنید.
مطابق شکل زیر یک جدول با عنوان PartitionsLog ایجاد کنید.
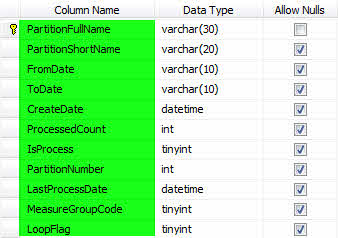
سه رویه زیر را دریافت و ایجاد کنید.
دومین SP برای دریافت
اطلاعات پارتیشنهای قبلی جهت ساخت پارتیشن جدید ایجاد شده است.
سومین SP وظیفه ثبت اطلاعات پارتیشن جدید در PartitionsLog را دارد.
تا به اینجای کار مراحل اولیه آماده سازی شد، از این پس در SSIS به ایجاد یک Package برای ایجاد پارتیشن میپردازیم.
یک پروژهی SSIS با نام Partition ایجاد کرده و مطابق شکل زیر در قسمت Variable متغیرها را تعریف نمایید.
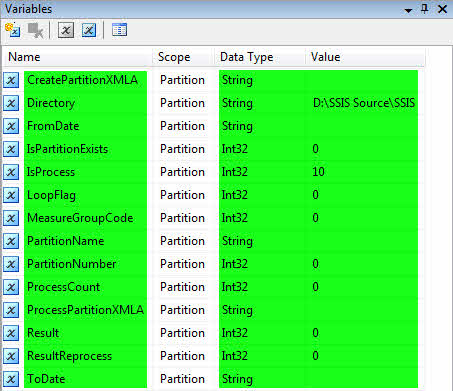
در جدول زیر شرح مختصری از وظیفه متغیرها آمده
|
برای ساخت XMLA جدید از آن استفاده میشود. |
CreatePartitionXMLA |
|
آدرس فایلهای XMLA که پیشتر ساخته شده را در خود دارد. |
Directory |
|
مشخص کننده تاریخ شروع اطلاعات موجود در پارتیشن است. |
FromDate |
|
نشان دهنده وجود داشتن/ نداشتن پارتیشن است. |
IsPartitionExists |
|
نشان دهنده پارتیشن پردازش شده / پارتیشن پردازش نشده است. |
IsProcess |
|
اطلاعات مربوط به تکرار را در خود ذخیره میکند. |
LoopFlag |
|
کد گروه معیار را در خود جای میدهد. |
MeasureGroupCode |
|
نام پارتیشن در این متغیر قرار میگیرد. |
PartitionName |
|
شماره پارتیشن در این متغیر قرار میگیرد. |
PartitionNumber |
|
تعداد دفعات پردازش یک پارتیشن در این متغیر قرار میگیرد. |
ProcessCount |
|
جهت پردازش پارتیشن از این متغیر استفاده میشود. |
ProcessPartitionXMLA |
|
خروجی SP دوم که برای پردازش مجدد استفاده میشود در این متغیر قرار میگیرد. |
Result |
|
نتیجه پردازش مجدد |
ResultReprocess |
|
اطلاعات موجود در Fact تا این تاریخ در پارتیشن ثبت میشود. |
ToDate |
-مطابق شکل زیر 11 عدد Execute SQL Task، یک Analysis Services Processing Task، 2عدد For Loop Container، 4 عدد Analysis Services Execute DDL Task و 4 عدد Script Task به پروژه اضافه کرده و به هم متصل کنید.
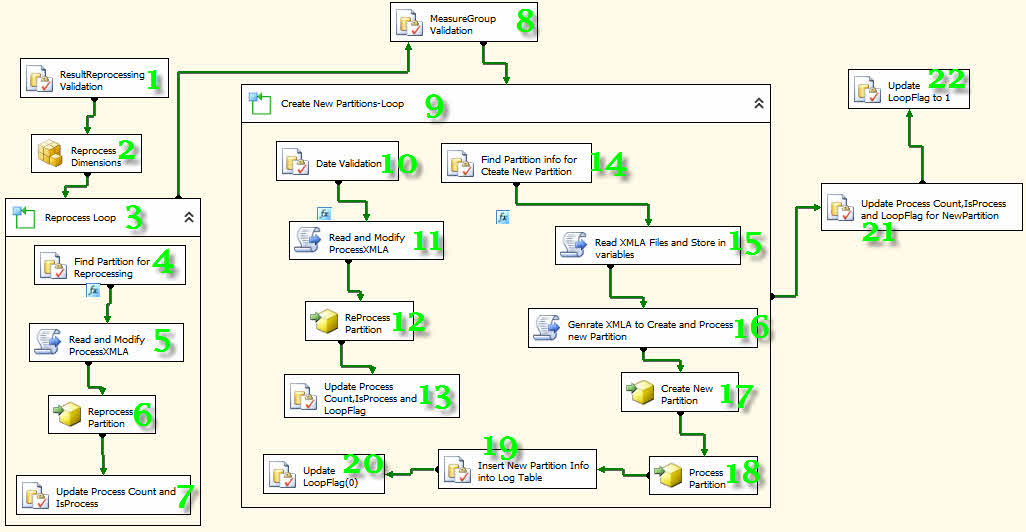
با توجه به شمارههای قرار گرفته بر روی هر کامپننت توضیحاتی میدهم که باید قدم به قدم اجرا شود.
1- رویه Findisprocess را فراخوانی کرده تا اطلاعات پارتیشنهایی که فیلد IsProcess آنها صفر است در متغیرها قرار گیرد.
2- تمامی دایمنشنها را پردازش میکند.
3- برای پردازش مجدد تمامی پارتیشنها، یک حلقه ایجاد میکند و تا زمانی که نتیجه پردازش 1 است به کار خود ادامه میدهد.
4- رویه Findisprocess را فراخوانی کرده تا تمامی اطلاعات مربوط به پارتیشن را دریافت کند.
5- توسط این کامپننت میتوانیم از زبانهای برنامه نویسی C# و VB در پکیج استفاده کنیم. توسط مجموعه کدهای نوشته شده در این قسمت تغییرات مورد نیاز جهت پردازش مجدد اعمال میشوند.
کدهای مربوط به کامپننتهای Script Task شماره 5 را از اینجا دریافت کنید.
6- پارتیشن مورد نظر را پردازش میکند.
7- فیلدهای موجود در PartitionsLog بروزرسانی میشوند.
8- گروه معیارها شناسایی میشوند.
9- از آنجایی که دو گروه معیار داریم، برای ایجاد پارتیشن به یک حلقه نیاز داریم. در این حلقه ابتدا در صورت نیاز آخرین پارتیشنها پردازش میشوند و سپس پارتیشنهای جدید ایجاد میشوند.
10- تمامی اطلاعات مورد نیاز برای پردازش مجدد پارتیشن دریافت میشود.
11- تغییرات مورد نیاز جهت پردازش مجدد اعمال میشوند.
کدهای مربوط به کامپننت Script Task شماره 11 را از اینجا دریافت کنید.
12- پارتیشن مورد نظر را پردازش میکند.
13- فیلدهای موجود در PartitionsLog بروزرسانی میشوند.
14- تمامی اطلاعات مورد نیاز برای ایجاد و پردازش پارتیشن دریافت میشود.
15- فایلهای XMLA ایجاد شده در ابتدای پروژه را بازخوانی و متغیرهای مربوطه را بارگذاری میکند.
کدهای مربوط به کامپننت Script Task شماره 15 را از اینجا دریافت کنید.
16- اطلاعات مورد نیاز برای ایجاد و پردازش پارتیشن را آماده میکند.
کدهای مربوط به کامپننت Script Task شماره 16 را از اینجا دریافت کنید.
17- پارتیشن جدید را ایجاد میکند.
18- پارتیشن ایجاد شده را پردازش میکند.
19- اطلاعات مربوط به پارتیشن جدید توسط رویه InsertNewPartitionInfo ثبت میشود.
20- مقدار فیلد LoopFlag را به صفر تغییر میدهد. دلیل اینکار جلوگیری از تکرار بیدلیل در پردازش پارتیشن است.
21- اطلاعات تکمیلی پارتیشن جدید را بروزرسانی میکند.
22- مقدار فیلد LoopFlag را به یک تغییر میدهد. دلیل اینکار فراهم نمودن شرایط تکرار در پردازش پارتیشن در صورت لزوم است.
کار تمام است! حال میتوانید از Package خود استفاده کنید.
لازم به ذکر است که با کمی کار بیشتر و ایجاد تغییرات جزئی میتوان این پکیج را بهینه کرد.
OLAP چیست؟
سیستم های OLAP نام خود را از عبارت (Online Analytical Process) با معنی "سیستم های پردازش تحلیلی برخط" گرفته اند. می توان به جای OLAP از واژه پردازش سریع اطلاعات چند بعدی و یا به عبارت بهتر از " فن آوری تحلیل داده ها" استفاده کرد. این سیستمها بر اساس تکامل سیستمهای OLTP به معنی پردازش آنلاین تراکنش ها ایجاد شده اند .تکنولوژیOLAP به طیف گستردهای از تکنیکها اطلاق میشود و از ابزارهای پشتیبانی کنندۀ تصمیم گیری میباشد. ابزارهای گزارش گیری و کوئری های سنتی، داراییها و اشیاء پایگاه داده را توصیف کرده و آنها را شرح میدهند. سیستم های OLAP برای ارائه پاسخهای سریع به سوالات و جستجوهای تحلیلی روی داده های "چند بعدی" طراحی شده اند . بطور معمول اگر بخواهیم مشابه همین پرس و جوهای تحلیلی را روی سیستم های اطلاعاتی عادی OLTP اجرا کنیم ممکن است نتایج در زمانی طولانی و غیرکاربردی بازگردانده شود در حالیکه استفاده از OLAP تضمین می کند که اطلاعات و گزارشات تحلیلی با زمان پاسخ مناسبی به کاربر تحویل داده شود.
اما همانطور که گفته شد تکنولوژیOLAP پاسخی جدید به مشکلات سیستمهای حمایت از تصمیمگیری است. باید در نظر داشت که OLAP یک تکنیک ساده نیست بلکه مجموعهای از مفاهیمی از قبیل سازمان پایگاه داده، نمایش داده و مدل کردن کوئری میباشد. تکنولوژی OLAP ابزارها و مفاهیمی را ارائه میکند که به وسیله آنها امکان انجام یک تحلیل موثر و دلخواه بر روی هر نوع دادهای فراهم میگردد.
کاربردهای معمول OLAP عبارتند از : گزارشات تجاری فروش، بازاریابی، گزارشات مالی و مواردی از این قبیل. این سیستم ها داده های خود را به نحوی خاص نگهداری می کنند که از نظر سرعت در برخورد با داده های چند بعدی بهتر از سیستمهای OLTP عمل می کنند و از این رو به آنها بانکهای اطلاعاتی سلسله مراتبی هم گفته میشود.
OLAP و پایگاه داده های مربوطه با استفاده از یک ساختار سلسله مراتبی و یک data model چندبعدی قدرتمند جهت سازماندهی اطلاعات به ساده سازی محاسبات پرداخته وگزارشاتی بسیار سریعتر نسبت به روش های قبلی ارائه می دهند.
بانکهای اطلاعاتی به کار رفته در OLAP که Datawarehouse یا انبار داده ها نامیده می شوند متشکل از مکعبهای اطلاعاتی چند بعدی بوده که امکان آنالیز سریع اطلاعات پایگاه داده های مختلف را فراهم میآورند. بعنوان مثال یک پایگاه داده چند بعدی می تواند فروش کل سالیانه را با ماه فروش ، تعداد مشتری و قیمت متقاطع سازد. حاصل این تقاطع این است که گزارشات بسیار متنوعی مثل مجموع فروش در ماه خاص یا بهترین قیمت و مشتری سال و ... از سیستم به راحتی قابل استخراج است.