هوش تجاری (Business Intelligence)
به اشتراک بگذاریم برای یادگیری، یاد بگیریم برای به اشتراک گذاریهوش تجاری (Business Intelligence)
به اشتراک بگذاریم برای یادگیری، یاد بگیریم برای به اشتراک گذاریجایگاه کلیک ویو در BI
جهت بررسی این موضوع ابتدا به معرفی اجمالی از کلیک ویو میپردازم.
کلیک ویو یکی از بهترین و انعطاف پذیرترین پلتفرم های هوش تجاری است. بیشتر از 24000 سازمان کوچک و بزرگ در سراسر جهان برای تحلیل گرافیکی داده هایشان از کلیک ویو استفاده میکنند.
این ابزار با ترکیب نمودن قابلیت هایی همچون ارائه پویا، تجزیه و تحلیل و به کارگیری آنی داده ها به کاربران توانایی اخذ تصمیمات تجاری مبتکرانه را میدهد و به بهترین نحو داده ها را به دانش تبدیل میکند. این نرم افزار با ارائه یک پلتفرم تجاری هوشمند و قدرتمند که به سادگی قابل استفاده میباشد، دید عمیق تر و شفاف تری از داده ها را به کاربران میدهد تا آنها در تصمیمات تجاری خود در تمام سطوح پیشگام باشند. کلیک ویو با ارائه تحلیلی دقیق و بدون محدودیت در دادهها، کاربران خود را در تصمیم گیری کمک میکند. ابزار کلیک ویو یک سطح کاملا جدیدی از تجزیه و تحلیل، بینش و ارزش دادههای موجود را با رابط کاربری بسیار شفاف، ساده و صریح ارائه میدهد.
بله! کلیک ویو یک داشبورد قدرتمند است که به وسیله آن میتوان دادهها را به صورت ویژوال کنار هم قرار داده و گزارشات متعدد با قابلیتهای بسیار بالا ایجاد نمود. اما آیا کلیک ویو به تنهایی قادر است که داشبوردهای گوناگون، زیبا و کاربردی ایجاد کند؟ قبل از پاسخ به این سوال به بررسی اجمالی پیش نیازها در یک پروژهی هوشمندی کسب و کار میپردازم.
سه بخش اصلی در هوشمندی کسب و کار وجود دارد که نبودن هر یک به منزله شکست پروژه است.
- منبع داده
- انبار داده
- داشبورد
منبع داده: هر سازمانی بنا به نیاز خود از سیستمهایی استفاده میکند. به عنوان مثال برای کارهای مالی، حقوق و دستمزد، فروش، منابع انسانی و ... سیستمهای نرم افزای فراهم میکند. این سیستمها میتوانند در قالب یک پکیج آماده باشند و یا یک تیم برنامه نویس بر اساس نیاز سازمان آن را نوشته باشد. به مرور زمان بر اساس نیاز، این نوع سیستمها گسترش پیدا میکنند و در نتیجه با حجم زیادی از دادهها روبرو میشویم.
با بالا رفتن حجم دادهها و زیاد شدن منابع داده، گزارش گیری بسیار سخت و گاهی ناممکن میشود در حالی که با حجم بالایی از دادهها روبرو هستیم، هیچ استفادهی مفیدی از آنها نمیتوانیم بکنیم.
در اینجا است که BI میتواند به کمک سازمان رفته و نیازهای آن را مرتفع کند.
انبار داده: در منابع دادهها اطلاعات بسیار زیادی وجود دارد که ممکن است تمام این اطلاعات مفید نباشد و از طرفی ممکن است نیاز به ترکیب دادهها از چند منبع با یکدیگر باشد. در اینجا انبار دادهها به کمک ما میآید و بوسیله آن میتوانیم اطلاعات مفید را از یک یا چند منبع مختلف کنار هم گردآوری کنیم. البته کار به این سادگی هم نیست! این کار نیاز به تحلیل و طراحی دارد که بنا به نیاز سازمان و چندین آیتم دیگر انجام میگیرد.
داشبورد: این همان مرحلهای است که میتوانید نتیجه کار را مشاهده کنید. ایجاد گزارشات و شاخصها با استفاده از نمودار و گیج همراه با امکاناتی همچون حرکت در سطوح مختلف گزارش و Drill Down در یک محیط کاملا انعطاف پذیر. این داشبوردها را میتوان توسط کلیک ویو و یا هر ابزار دیگهای که این قابلیت را داشته باشد ایجاد نمود.
نبود هر یک از این موارد به شکست پروژه خواهد انجامید.
اما بر میگردم به سوالی که کمی پیشتر پرسیدم! آیا کلیک ویو به تنهایی قادر است که داشبوردهای گوناگون، زیبا و کاربردی ایجاد کند؟
با وجود قدرت بسیار بالای کلیک ویو در برقراری ارتباط با منابع دادهای مختلف و یکپارچه کردن دادهها، پاسخ خیر است زیرا کلیک ویو یک ابزار است که باید از آن در مرحله Presentation استفاده کرد.
به طور کلی کلیک ویو ابزاری است بسیار قوی جهت ایجاد داشبوردهای مدیریتی که بواسطه آن مدیران بتوانند برای سازمان خود تصمیم گیری کنند.
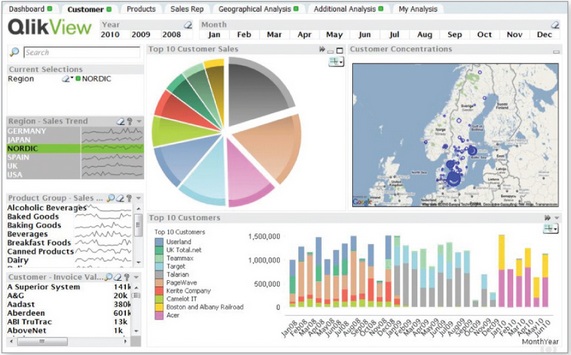
OLAP به زبان ساده
OLAP مجموعهای از مکعبها (Cubes) است. داخل این مکعبها دادههایی قرار دارند که از پیش انتخاب شدهاند. ارتباطات بین ابعاد از قبل تعریف شده و همه ابعاد (نتایج) از قبل محاسبه و پیشبینی شده است. هنگامی که یک مکعب ایجاد میشود، یک واسط کاربر نهایی که میتواند یک داشبورد باشد برای یک فرد واقعی پیادهسازی میشود که کاربر نهایی(مدیران و تصمیم گیرندگان سازمان) بتواند با جوابهای داخل مکعب تعامل داشته باشد.
اما فرض کنید در یک مکعب برای تحلیل فروش در یک سازمان مقدار و مبلغ فروش را بر اساس ابعادِ مناطق فروش، فروشنده (بازاریاب)، مشتری و ماه یا سال داشته باشیم. زمانی که این مکعب فرضی ساخته میشود، نرمافزار مبتنی بر OLAP کلیه ترکیبات عناصر دادهها را محاسبه و ذخیره میکند، کاربر نهایی به این دادهها از طریق داشبوردها و یا یک سری فرمها مثلا Pivot Table ها یا انواع دیگر فرمها دسترسی خواهد داشت.
در این مثال فرضی کاربر نهایی محدود به تحلیل در محدوده ابعاد از قبل تعریف شده مثل مناطق، نمایندگیها، مشتریها و ماه است. اگر کاربر بخواهد درباره فروش هفتگی، روزهای هفته یا محصولات فروخته شده (و یا صدها ترکیب دیگر از دادهها) اطلاعاتی کسب کند دیگر شانسی برای بدست آوردن آن ندارد، باید صبر کند که مکعب دیگری از اطلاعات مورد نیاز او ایجاد شود که این یعنی محدودسازی و کاهش بهرهوری و اثربخشی برای تصمیمگیران آن سازمان. به عبارت دیگر کاربر نهایی باید نیازهای خود را از پیش شناخته و برای این نیازها Cubeها، جداول حقایق (Fact) و ابعاد (Dimension) مورد نیاز را پیاده سازی کند تا با کنار هم قرار دادن گزارشات مختلف تا حدودی به دانش استخراج شده و مورد نیاز خود دست پیدا کند.OLAP برخی از قابلیتهای تحلیل را فراهم میکند، اما تقریبا میتوان گفت در کشورهای پیشرفته یک رویکرد قدیمی است و متاسفانه در کشور ما همچنان ناشناخته! یا کمتر شناخته شده است. در حال حاضر انواع مختلف OLAPوجود دارد، مثل MultiDimensiona OLAP (MOLAP) که به آن MMD نیز گفته میشود و Relational OLAP (ROLAP) یاRDBMS و سیستم های OLAP از نوع
HOLAP.
در پست جداگانه به تشریح انواع OLAP و مقایسه آنها میپردازم.
انبار دادههای AdventureWorks
کتابهای آموزشی ماکروسافت در حوزه Business Intelligence، برای طرح مثالهای خود از پایگاه دادههای AdventureWorks استفاده میکند. در واقع AdventureWorks نام سازمانی است که اطلاعات آن در یک انبار داده با همان نام گردآوری شده است. در انبار دادههای AdventureWorks جداول و Viewهایی برای استفاده در پروژههای مختلف BI ایجاد شده است. ممکن است در برخی از مثالها از انبار دادهی AdventureWorks استفاده کنم که لازم است پیشتر آن را نصب کرده باشید.
جهت اضافه کردن پایگاه دادههای AdventureWorks به SQL Server مراحل زیر را انجام دهید.
برای دریافت فایل مورد نظر به اینجا مراجعه کنید.
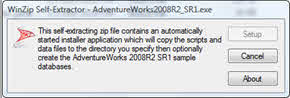
فایل دانلود شده را از حالت فشرده خارج کنید و AdventureWorks2008R2_SR1 را اجرا نمایید.
بر روی Setup کلیک کنید.
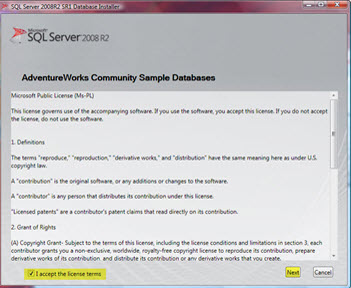
در صفحه SQL Server 2008R2 Database Installer چک باکس I accept the license terms را انتخاب و Next را کلیک کنید.
مطابق شکل زیر، بر روی Install کلیک کنید.
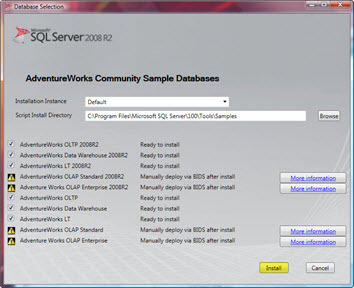
اگر در زمان نصب نرم افزار، آدرس محل نصب را تغییر دادید، باید در این قسمت نیز از همان آدرس استفاده کنید.
پس از پایان نصب بر روی Finish کلیک کنید.
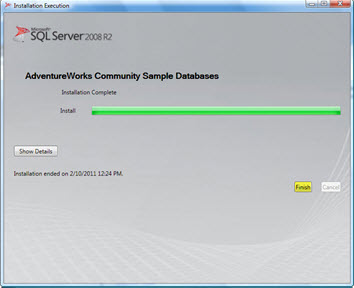
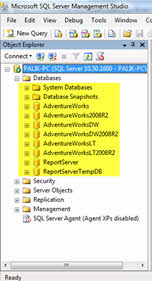
همان طور که در شکل زیر می بینید، انبار داده AdventureWorks2008R2 به همراه چند پایگاه دادهی دیگر بهSQL Server 2008 اضافه شده است.
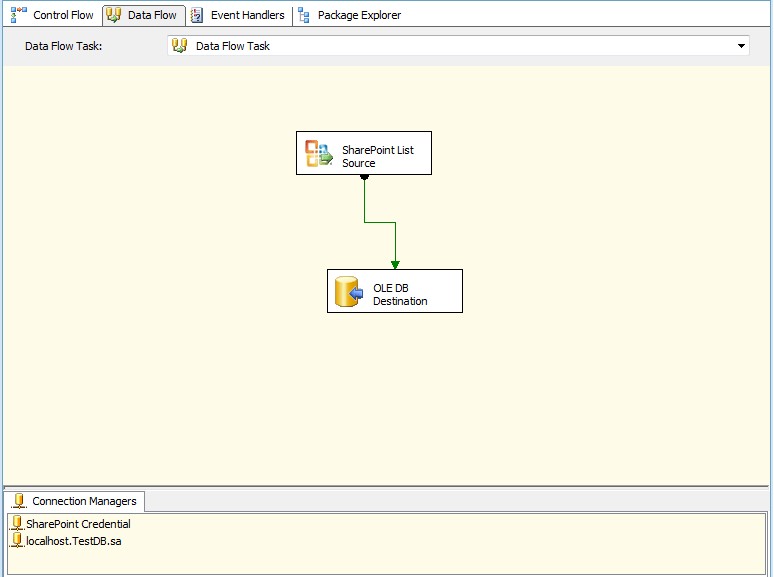
واکشی دادهها از شیرپوینت و بارگذاری در SQL توسط SSIS
امروزه استفاده از شیرپوینت به عنوان ابزار ایجاد کننده وب سایت به دلیل سرعت بالا در ایجاد و راهاندازی بسیار گسترش پیدا کرده است و بسیاری از سازمانها از آن استفاده میکنند. بنابراین میتوان شیرپوینت را به عنوان منبع دادهها در نظر گرفت.
برای خواندن و بارگذاری دادههای شیرپوینت در SQL Server از طریق SSIS چندین روش وجود دارد که در این مقاله به یکی از بهترین و سادهترین آنها که استفاده از SharePoint Web services است، میپردازم.
ابتدا باید Features مربوط به SharePoint List Source and Destination را از اینجا دریافت کنید.
پس از دانلود، مطابق تصاویر زیر مراحل نصب را انجام دهید.
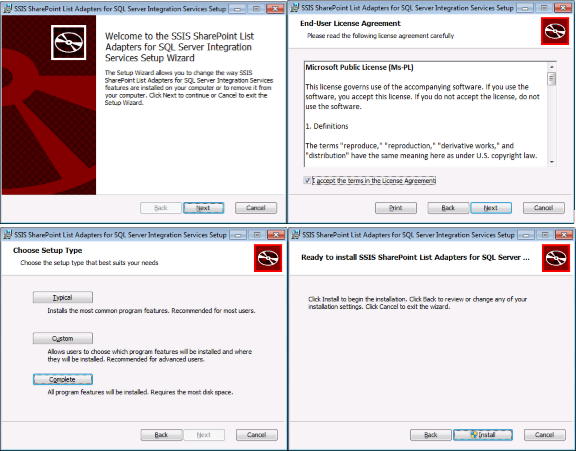
بعد از اتمام مراحل نصب باید کامپننتهای SharePoint List Source and Destination را به جعبه ابزار SSIS اضافه کنید. برای اینکار مراحل زیر را انجام دهید.
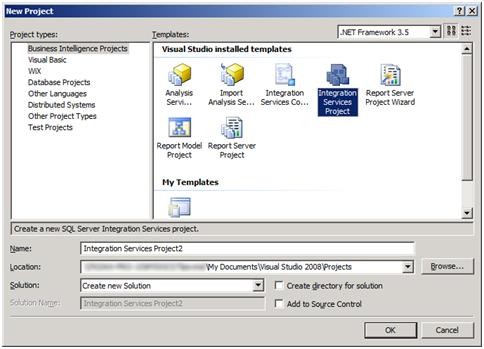
1- برنامه Business Intelligence Development Studio را باز کردهو مطابق تصویر زیر یک پروژهی جدید SSIS ایجاد کنید.
2- از منوی Tools گزینه Choose Toolbox Items را انتخاب کنید.
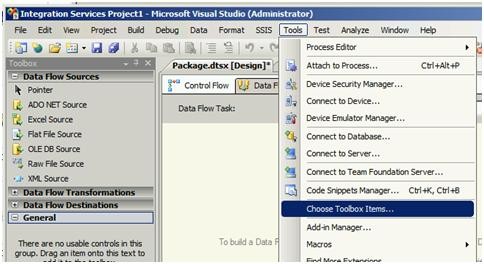
پنجره Choose Toolbox Items باز میشود.
3- از پنجره بازشده به سربرگ SSIS Data Flow Items رفته و چکباکس مربوط به SharePoint List Source و SharePoint List Destination را انتخاب نمایید. برروی Ok کلیک کنید.
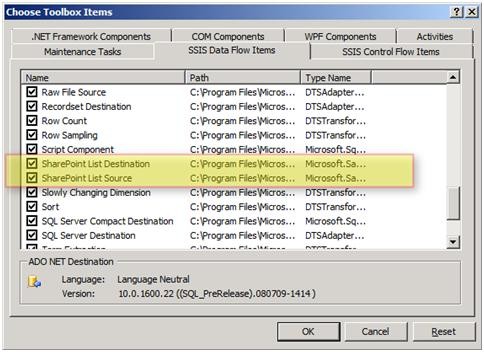
این دو کامپننت به قسمت General در جعبه ابزار SSIS اضافه میشوند. شما میتوانید هر یک از آنها را به محل مناسب خود منتقل کنید.
آماده سازی یک لیست شیرپوینت جهت انجام یک مثال
1- ایجاد لیستی با عنوان TestSharePointList که شامل اطلاعات زیر باشد.
نام: کارمندان
ستونها:
· شماره پرسنلی (نوع: عدد)
· نام کارمند(نوع: کاراکتر)
· جنسیت (انتخابی؛ انتخاب اول، زن انتخاب دوم، مرد)

ایجاد یک جدول در SQL مطابق با لیست ایجاد شده در شیرپوینت
1- وارد SSMS شده و یک بانک اطلاعاتی با نام TestDB ایجاد کنید.
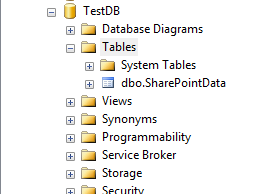
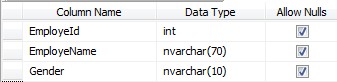
2- مطابق شکل زیر یک جدول با نام SharePointData ایجاد کنید.
استخراج داده از لیست شیرپوینتی ساخته شده توسط SharePoint List Source
1- در این قسمت ابتدا باید یک اتصال دهنده شیرپوینتی ایجاد نمود. برای انجام اینکار مطابق تصاویر زیر عمل کنید.
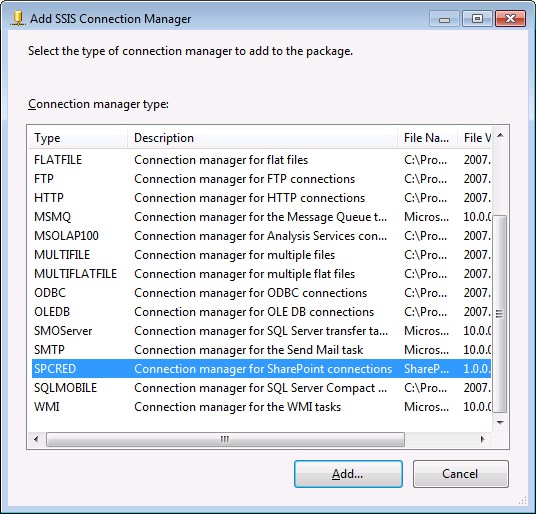
این اتصال دهنده پس از نصب Features مربوط به شیرپوینت که مراحل نصب آن در ابتدای مقاله توضیح داده شد، به لیست Add SSIS Conection Manager اضافه میشود.
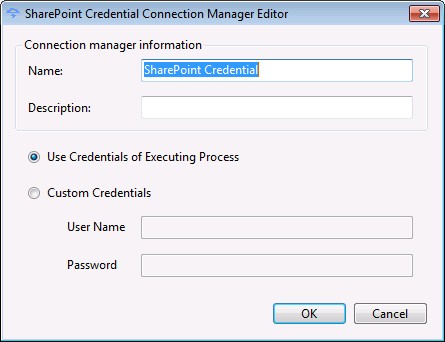
در صورتی که برای دسترسی به لیستهای شیرپوینتی نیاز به دسترسی خاصی دارید باید در قسمت Custom Credentials نام کاربری و رمز عبور آن User مربوطه را وارد کنید.
2- از جعبه ابزار یک کامپننت Data Flow Tasks به پکیج خود اضافه کنید. مجدد از جعبه ابزار SharePoint List Source را درون Data Flow Tasks قرار دهید.

3- انجام تنظیمات مربوط به SharePoint List Source، برای اینکار برروی کامپننت SharePoint List Source دوبار کلیک کرده و مطابق تصاویر زیر عمل نمایید.
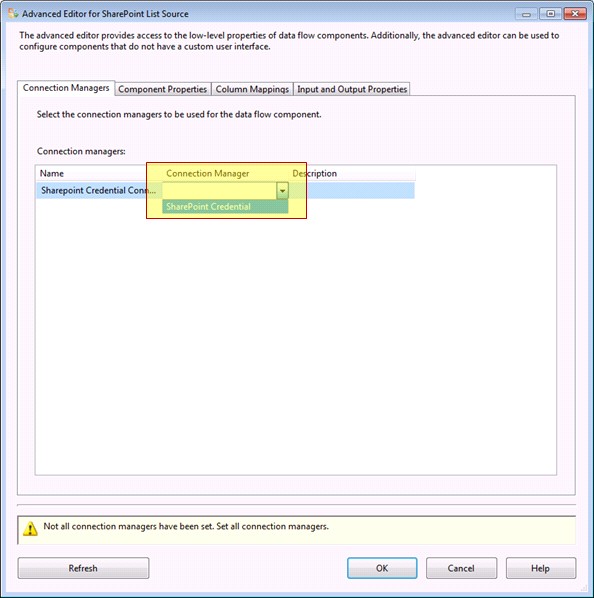
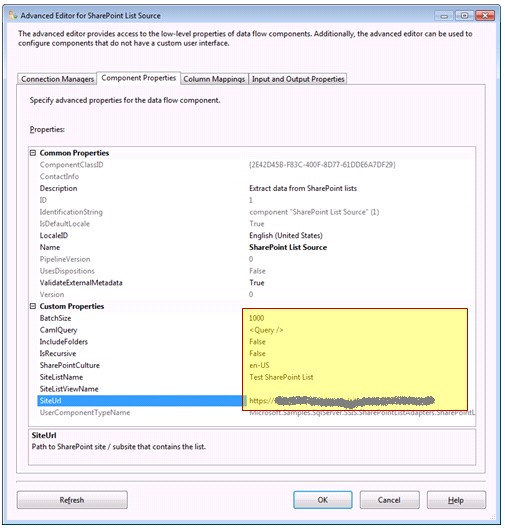
پس از وارد کردن آدرس مربوط به سایت لیست ساخته شده و نام آن در قسمت SiteUrl و SiteListName بر روی Refresh کلیک کنید تا ارتباط با لیست ساخته شده برقرار شود.
در این قسمت تنظیمات دیگری نیز وجود دارد که در مقالهای جداگانه به آنها خواهم پرداخت.
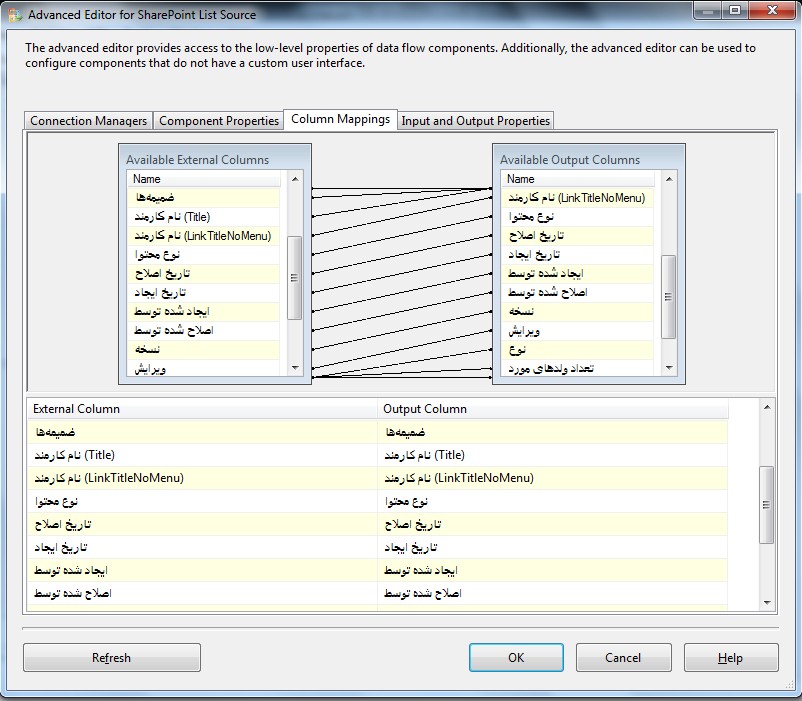
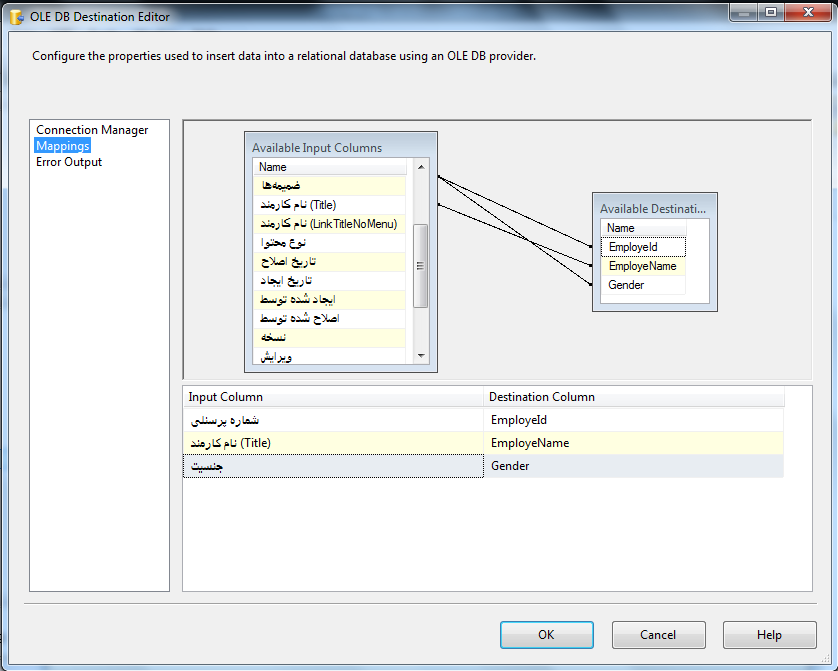
4- در مرحله بعد باید ستونهای مورد نظر خود را انتخاب کنید. برای اینکار به سربرگ Column Mappings بروید تا فیلدهای لیست شیرپوینتی نمایش داده شود. برخی از این فیلدها توسط خود شیرپوینت ساخته میشود. فیلدهایی که قصد دارید آنها را در خروجی داشته باشید را انتخاب کرده و بر روی Ok کلیک کنید.
5- از جعبه ابزار یک OLE DB Destination به پکیج اضافه کنید و تنظیمات آن را مطابق تصاویر زیر انجام دهید.
برروی کامپننت OLE DB Destination دوبار کلیک کنید تا صفحه مربوط به تنظیمات آن باز شود. سپس جدولی که پیشتر در SQL ساخته بودید را انتخاب نمایید.
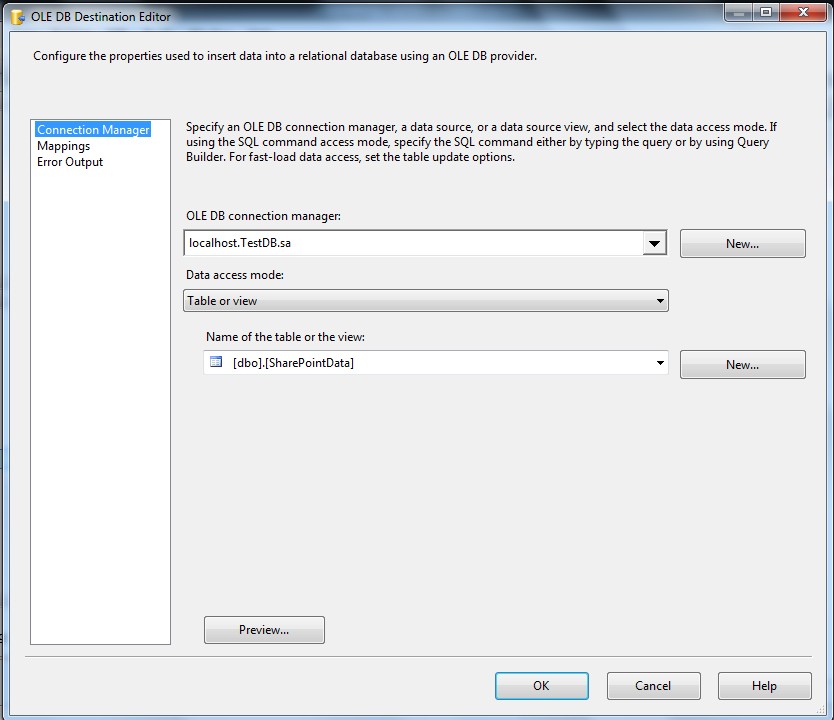
در قسمت Mapping فیلدهای جداول مبدا و مقصد را انتخاب کنید.
با کلیک برروی Ok کار تمام است و میتوانید پکیج را اجرا کنید.

دسته بندی الگوریتم های داده کاوی
از دادهکاوی برای کاوش در اطلاعات و بدست آوردن دانش استفاده میشود. برای اینکار الگوریتمهای زیادی وجود دارد که هر یک برای هدف خاصی کاربرد دارند. در SQL Server Business Intelligence Development Studioتعداد 9 الگوریتم مختلف برای انجام عمل دادهکاوی وجود دارد که در پنج دسته کلی به شرح زیر تقسیم میشوند.
الگوریتمهای طبقهبندی(Classification algorithms)
در این نوع از الگوریتمها پیش بینی بر اساس یک یا چند متغیر گسسته بر روی سایر ویژگیهای موجود در مجموعه دادهها انجام میشود.
الگوریتمهای رگرسیون(Regression algorithms)
در این نوع از الگوریتمها پیش بینی بر اساس یک یا چند متغیر پیوسته بر روی سایر ویژگیهای موجود در مجموعه دادهها میشوند.
الگوریتمهای دستهبندی(Segmentation algorithms)
این الگوریتمها اطلاعات را به چند گروه یا خوشه تقسیم میکنند. هر گروه ویژگیهای مشابه دارد.
الگوریتمهای وابستگی(Association algorithms)
ارتباط میان ویژگیهای مختلف موجود در مجموعه دادهها از طریق این الگوریتم کشف میشود. از این الگوریتم بیشتر در تجزیه و تحلیل سبد خرید کالا استفاده میشود.
الگوریتمهای تحلیل زنجیرهای(Sequence analysis algorithms)
این نوع الگوریتمها نتیجهی رویدادهای خاص را دنبال میکنند. مانند دنبال کردن رخدادهای آدرس یک سایت اینترنتی.
لازم به ذکر است که تعاریف و دستهبندیهای بالا دلیلی برای محدود کردن استفاده از یک الگوریتم نیست. معمولا در یک تحلیل خوب از یک الگوریتم برای تعیین ورودیهای موثر و از الگوریتمهای دیگر برای بدست آوردن پیش بینیهای مناسب در خروجی استفاده میشود. برای مثال، در یک مدل دادهکاوی میتوانید از الگوریتمهای خوشهبندی، درخت تصمیم و بیز جهت بررسی دادهها از جهات مختلف و کشف دانش استفاده کرد.