هوش تجاری (Business Intelligence)
به اشتراک بگذاریم برای یادگیری، یاد بگیریم برای به اشتراک گذاریهوش تجاری (Business Intelligence)
به اشتراک بگذاریم برای یادگیری، یاد بگیریم برای به اشتراک گذاریRollBack در SSIS
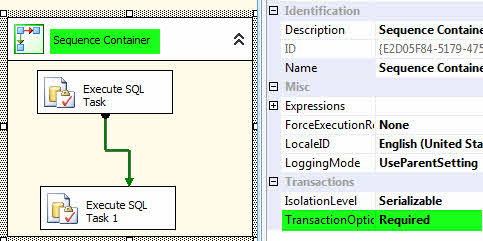
اگر با Stored Procedures نویسی در SQL آشنا باشید، به خوبی با مفهموم Roll Back و ضرورت استفاده از آن اطلاع دارید. گاهی نیاز به Roll Back در پکیج ضروری است. به این معنا که اگر یکی از کامپننتها با خطا مواجه شد کل عملیات باید لغو شود و همه چیز به حالت اول برگردد. یکی از روشهای انجام اینکار در SSIS استقاده از Sequence Container است. در واقع Sequence Container دسته بندیهای اجرای کامپننتها را بر عهده دارد. کامپننتهای موجود در هر Sequence Container با هم اجرا میشوند و سپس اجرای سایر کامپننتها یا Sequence Containerها انجام میشود.
با این وجود مسئلهی Roll Back همچنان وجود دارد. برای حل این مسئله باید از خصوصیت TransactionOption استفاده کنیم. به صورت پیش فرض این خصوصیت Supported است، آن را به Required تغییر دهید.
کار تمام است! حال در صورتی که یکی از کامپننتهای داخل Sequence Container با خطا مواجه شود تمامی کارهای انجام شده Roll Back شده و به حالت اول باز میگردد.
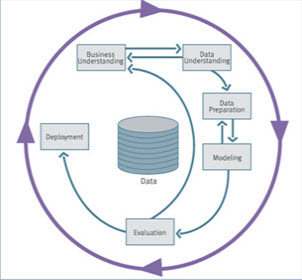
فرآیند داده کاوی- CRISP
چرخه حیات داده کاوی شامل 6 بخش است. شکل زیر مراحل این فرآیند را نمایش میدهد. در این سیکل حرکت به عقب و جلو امری عادی است. خروجی هر مرحله رابطه مستقیم با انجام وظایف در مرحله بعدی دارد و حرکت فلشها برای وابستگیهای میان مراحل بسیار مهم است.
در ادامه هر سیکل را به طور خلاصه شرح میدهم.
درک و فهم موضوع (Business understanding)
اولین مرحلهی این چرخه، تمرکز بر روی هدف و درک نیازمندیها و موضوع پروژه است. تبدیل اطلاعات اولیه به آگاهی و رسیدن به تعریفی مناسب برای حل مسئله دادهکاوی و طراحی برنامه اولیه جهت دسترسی به هدف مورد نظر اولین قدم در یک پروژهی دادهکاوی است. ممکن است گذر از این مرحله ماهها طول بکشد که البته به نوع سازمان نیز بستگی دارد.
درک و فهم دادهها (Data understanding)
این مرحله با جمع آوری دادههای اولیه از منابع داده، بررسی ویژگیها و کیفیت داده، پردازش فعالیتها به منظور آشنایی با دادهها، شناسایی مشکلات و اکتشاف بینش اولیه از دادهها شروع میشود.
آماده سازی دادهها (Data preparation)
مرحله آماده سازی دادهها، تمامی فعالیتها را برای ساخت دادههای خام اولیه به مجموعه دادههای نهایی پوشش میدهد. این فعالیتها شامل پاک سازی، ادغام و قالب بندی دادهها است. از آنجایی که از این دادهها در مراحل بعدی استفاده میشود این مرحله بسیار مهم میباشد.
مدل سازی (Modeling)
در این مرحله تکنیکهای مدل سازی مختلف انتخاب و اعمال میشوند تا پارامترهای آنها به مقادیر مطلوب برسند. پس از انتخاب روش مدل سازی باید یک مدل آزمون ایجاد کنیم تا کیفیت و اعتبار مدل را آزمایش کنیم. در نهایت یک مدل نهایی که به نظر میرسد از لحاظ تجزیه و تحلیل داده دارای کیفیت بالایی است، ساخته میشود.
ارزیابی (Evaluation)
قبل از استقرار نهایی مدل باید مشخص شود که آیا مدل انتخاب شده، ما را به هدفی که در اولین قدم تعیین نموده بودیم میرساند.
گسترش (Deployment)
حتی اگر هدف از ساخت مدل، افزایش دانش باشد، عموماً ساخت یک مدل پایان پروژه نیست. اطلاعات حاصله احتیاج به سازماندهی و ارائه به روشهایی که کاربران نهایی بتوانند از آن استفاده کنند دارد. اغلب به کار بردن مداوم این مدل، در سازماندهی و فرایندِ ساخت تصمیمات مدنظر است.
در هر یک از این مراحل میتوانیم به مرحله قبل برگردیم و با بازنگری به پیشبرد هدف سازمان کمک کنیم. پس از مرحله گسترش نیز میتوانیم از ابتدا مراحل را مورد بررسی قرار داده و در صورت نیاز پروژه را گسترش دهیم.
برگرفته از CRISPWP
تعاریف پایه در SSAS- بخش دوم
پارتیشن (Partitions)
معمولا زمانی از پارتیشن استفاده میکنیم که با حجم زیادی از دادهها روبرو باشیم. برای پردازش دادههای حجیم زمان زیادی را باید صرف کرد، از طرفی نیازی نیست دادههای از پیش پردازش شده را مجدد پردازش نمود و فقط باید دادههای جدیدی که به انبار دادهها اضافه میشوند را مورد پردازش قرار داد.جهت اینکار دادهها را پارتیشن بندی میکنیم.
پیشمحاسبه(Aggregation)
کلمه Aggregation در لغت به معنای تجمیع و تراکم است اما مفهوم آن در SSAS پیشمحاسبه (Precalculated) است. به این معنا که در هنگام پردازش دادهها یک پیشمحاسبه نیز انجام میشود. این عمل همانند آماده و همراه داشتن خلاصهای از پاسخهای احتمالی، پیش از طرح سوال است. برای مثال زمانی که با یک جدول از هزاران رکورد روبرو هستیم، در هر زمان برای پاسخ به هر یک از سوالها (کوئری) زمان زیادی طول میکشد تا پاسخ مناسب دریافت شود. در صورتی که اگر پاسخ سوالات از پیش آماده شده باشند سرعت پاسخ گویی به مراتب بیشتر میشود.
Perspective
در OLAP برای دستهبندی و جداسازی معیارها، ابعاد، KPIها و... از Perspective استفاده میشود.
Browser
در SSAS خروجی Cubeهای ایجاد شده در این قسمت نمایش داده میشوند.
MDX
زبان برنامهنویسی در OLAP است که مخفف Multidimensional Expressions میباشد.
مجموعه داده(Named Set)
یکی از ابزارهای موجود در سربرگ Calculations، مجموعه داده است که توسط آن میتوان عضوهای یک بٌعد خاص را دسته بندی کرد. برای مثال میتوانیم 10 عضو برتر بعد مشتری را که بیشترین خرید را داشتهاند نمایش داد. این عملیات توسط عبارات MDX انجام میگیرد.
Script Command
در این قسمت از MDX برای ایجاد عبارات خاص استفاده میشود.
Named Query
در واقع همان View است. توسط این قسمت میتوان Viewهایی در DSV ایجاد کرد. دیدهای ایجاد شده فقط در SSAS نمایش داده میشوند.
Named Calculation
در صورت نیاز به تعریف Attribute در ابعاد استفاده میشود. برای تعریف این نوع Attribute از عبارات MDX و Query استفاده میشود.
Mining Structure
پروژههای دادهکاوی در این قسمت تعریف میشوند.
Mining Models
برای ایجاد مدلهای مختلف دادهکاوی و اعمال تغییرات در خصوصیات آنها از این قسمت استفاده میشود.
Mining Model Viewer
در SSAS خروجی مدلهای دادهکاوی در این قسمت نمایش داده میشوند.
Mining Accuracy
جهت بررسی بهتر صحت خروجیهای نمایش داده شده و همچنین مقایسه مدلهای دادهکاوی ساخته شده در Mining Models از این قسمت استفاده میشود.
Mining Model Prediction
در برخی از الگوریتمها قابلیت پیشبینی وجود دارد. از این قسمت برای ایجاد پیش بینی استفاده میشود.
DMX
زبان برنامهنویسی در دادهکاوی است که مخفف Data Mining Expressions میباشد.
MOLAP، ROLAP و HOLAP
در یک پروژهی OLAP از یک یا چند مکعب داده (Cube) استفاده میشود. از اینرو Cube به عنوان یکی از مزایای پروژه هوش تجاری شناخته میشود. قرار گرفتن دادهها در یک فرمت بهینه جهت ذخیرهسازی به انجام سریعتر کوئریها میانجامد. معمولا نحوه ذخیرهسازی اطلاعات حجیم در Cube باعث تاخیر در ذخیره و بازیابی انبوه اطلاعات میشود. به طور معمول در SSAS پردازش دادهها از یک بانک اطلاعاتی رابطهای به Cube منتقل میشود. پس از اتمام این ارتباط نه چندان طولانی میان پایگاه دادههای رابطهای و Cube اطلاعات وارد Cube میشوند و با تغییر دادهها در پایگاه داده هیچ تغییری در اطلاعات موجود در Cube ایجاد نمیشود مگر آنکه Cube را مجدد پردازش کنید.
در SSAS2008 سه نوع ذخیرهسازی وجود دارد؛ MOLAP، ROLAP و HOLAP
در این پست هر یک از انواع ذخیرهسازی را به صورت خلاصه شرح داده و در پایان با یکدیگر مقایسه میکنم.
MOLAP(Multidimensional Online Analytical Processing)
این نوع ذخیرهسازی بیشترین کاربرد در ذخیره اطلاعات را دارد همچنین به صورت پیش فرض جهت ذخیرهسازی اطلاعات انتخاب شده است. در این نوع تنها زمانی دادههای منتقل شده به Cube به روز میشوند که Cube پردازش شود که این امر باعث تاخیر بالا در پردازش و انتقال دادهها میشود.
ROLAP (Relational Online Analytical Processing)
در ذخیرهسازی ROLAP زمان انتقال بالا نیست که از مزایای این نوع ذخیرهسازی نسبت به MOLAP است. در ROLAP اطلاعات و پیشمحاسبهها (Aggregations) در یک حالت رابطهای ذخیره میشوند و این به معنای زمان انتقال نزدیک به صفر میان منبع داده (بانک اطلاعاتی رابطهای) و Cube میباشد. از معایب این روش میتوان به کارایی پایین آن اشاره کرد زیرا زمان پاسخ برای پرسوجوهای اجرا شده توسط کاربران طولانی است. دلیل این کارایی پایین بکار نبردن تکنیکهای ذخیرهسازی چند بعدی است.
HOLAP (Hybrid Online Analytical Processing)
این نوع ذخیرهسازی چیزی مابین دو حالت قبلی است. ذخیره اطلاعات با روش ROLAP انجام میشود، بنابراین زمان انتقال تقزیبا صفر است. از طرفی برای بالابردن کارایی، پیشمحاسبهها به صورت MOLAP انجام میگیرد در این حالت SSAS آماده است تا تغییری در اطلاعات مبداء رخ دهد و زمانی که تغییرات را ثبت کرد نوبت به پردازش مجدد پیشمحاسبهها میشود. با این نوع ذخیرهسازی زمان انتقال دادهها به Cube را نزدیک به صفر و زمان پاسخ برای اجرای کوئریهای کاربر را زمانی بین نوع ROLAP و MOLAP میرسانیم.
مقایسه انواع ذخیره سازی در جدول زیر نمایش داده شده است.
مدت زمان انتقال داده | سرعت اجرای کوئری | محل ذخیرهسازی پیشمحاسبات | محل ذخیرهسازی دادهها | |
بالا | بالا | Cube | Cube | MOLAP |
پایین | متوسط | Cube | بانک اطلاعاتی رابطهای | HOLAP |
پایین | پایین | بانک اطلاعاتی رابطهای | بانک اطلاعاتی رابطهای | ROLAP |
کلیات فرآیند ایجاد پروژهی هوشمندی کسب و کار
به طور کلی فرآیند ایجاد پروژههای هوشمندی کسب و کار به سه دسته عمدهی ((شناخت و تحلیل، طراحی و ساخت و گسترش و پشتیبانی)) تقسیم میشود.
1-شناخت و تحلیل
مهمترین قسمت در هر پروژهای شناخت سازمان است. کسب اطلاعات دقیق از قسمتهای مختلف و نحوه فعالیت سازمان در حوزههای مختلف نقش اساسی در موفقیت پروژه دارد. یک شرکت تولیدی با چندین شعبه را در نظر بگیرید، مادامی که از فرآیند تولید، فروش، دریافت مواد اولیه و... در این شرکت اطلاعات کافی و دقیقی نداشته باشید، نمیتوانید نیازهای شرکت را به خوبی درک کنید و در نهایت به شکست پروژه منجر خواهد شد. پس باید گام اول در پروژه به خوبی پشت سر گذاشته شود. معمولا شناخت سازمان، وضع موجود فناوری اطلاعات، تحلیل نیازمندیها و شاخصهای کلیدی عملکرد در این فاز بررسی و تعریف میشوند. این اطلاعات از روی مستندات و مصاحبههای حضوری بدست میآید.
2- طراحی و ساخت
در فاز طراحی و ساخت، با توجه به اطلاعات بدست آمده از سازمان و درک نیازها به طراحی و ساخت مدل و راهکارهای هوش تجاری میپردازیم. طراحی و ایجاد انبار داده، Solutionهای هوشمند کسب و کار (OLAP, Data Mining) و گزارشگیری در این فاز از پروژه انجام میشود.
پس از انجام مراحل فوق، شما می توانید نسبت به ساخت یا خرید یک نرم افزار گزارش گیری تصمیم گیری نمایید. به طور معمول هزینه ساخت یک نرم افزار گزارش گیری، بالاتر از هزینه خرید آن از یک شرکت داخلی یا خارجی است.
در نهایت برای کشف دانش، توسط یکی از ابزارهای گزارشگیری (ابزاری که توانایی ساخت داشبورد مدیریتی داشته باشد) از حوزههای مختلف فعالیت سازمان داشبوردهای مدیریتی ایجاد میشود تا به واسطهی آن مدیر بتواند وضعیت سازمان را به درستی تحلیل کند و برای آینده برنامه ریزیهای لازم را انجام دهد.
3- گسترش و پشتیبانی
مطمئنا هر پروژهای نیاز به پشتیبانی و نگهداری دارد تا در صورت بروز مشکلات احتمالی به سرعت رفع شود و سیستم مجدد به کار خود ادامه دهد. در این فاز پشتیبانی پروژهی هوشمندی کسب و کار انجام میشود. معمولا این پشتیبانی توسط تیمی که پروژه را انجام داده است انجام میشود.
علاوه بر این ممکن است پس از مدتی سازمان قصد گسترش پروژه را داشته باشد. معمولا برای گسترش پروژه نیز در اختیار تیم قبلی ساخت پروژه قرار میگیرد.