هوش تجاری (Business Intelligence)
به اشتراک بگذاریم برای یادگیری، یاد بگیریم برای به اشتراک گذاریهوش تجاری (Business Intelligence)
به اشتراک بگذاریم برای یادگیری، یاد بگیریم برای به اشتراک گذاریمراحل و نحوه بارگذاری داده ها در انبار داده
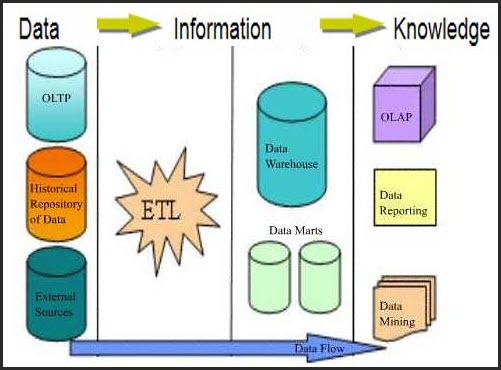
پس از شناخت و تحلیل سازمان، اولین قدم برای ساخت یک پروژهی هوش تجاری ایجاد انبار داده است. بر اساس نیاز باید اطلاعات را از منابع مختلف استخراج و جمع آوری(Extract)، پالایش (Transform) و در یک پایگاه داده ذخیره (Load) کنیم. به عملیات استخراج، پالایش و بارگذاری، ETL گفته میشود. امروزه ابزارهای زیادی برای انجام فرآیند ETL وجود دارد که تا حدود زیادی دقت و سرعت انجام این عملیات را بالا برده است. هر یک از این مراحل جزئیاتی دارند که در ادامه به شرح آن میپردازم.
۱- استخراج دادهها از پایگاههای داده به یک مخزن واحد
شناخت منابع دادههای سازمان و استخراج دادههای ارزشمند از آنها یکی از اصلی ترین مراحل ایجاد انبار داده است. دادههایی که بایست در قالب انبار گرد هم آیند غالباً به صورت پراکنده تولید شدهاند. برای مثال در یک فروشگاه زنجیرهای دادهها از طریق کامپیوترهای مراکز خرید مختلف، دستگاههای خرید اتوماتیک (مثل دستگاههای خرید نوشابه یا روزنامه) و نرم افزارهای انبارداری و حسابداری، به دست میآیند. انبار داده برای انجام وظیفه خود که همان تحلیل دادهها است باید همه این دادهها را با هر قالبی که تولید میشوند به طور مرتب و دقیق دریافت نماید. استخراج دادهها در یک محیط واسط که کم و بیش شبیه انبار دادهها است صورت میگیرد.
۲- پالایش دادهها
دادههای استخراج شده را باید بررسی نماییم و در صورت نیاز تغییراتی در آنها ایجاد کنیم. دلیل این کار، استخراج اطلاعات از پایگاه دادههای مختلف و برطرف نمودن نیازهای سازمان است. معمولا تمامی مراحل پالایش دادهها در محیط واسط انجام میگیرد اما گاهی برخی از مراحل پالایش در هنگام بارگذاری در انبار داده انجام میشود.
در پالایش دادهها مراحل زیر انجام میشود.
پاکسازی دادهها (Data Cleaner): ممکن است در دنیای امروز میلیونها مجموعه داده وجود داشته باشد، اما به راستی تمام این مجموعه از دادهها بدون اشکال هستند؟ آیا تمامی مقادیر فیلدهای هر رکورد پر شده است و یا مقادیر داخل فیلدها دادههای صحیح دارند؟ اگر دادهها از منابع یکسان مثل فایلها یا پایگاههای دادهای گرفته شوند خطاهایی از قبیل اشتباهات تایپی، دادههای نادرست و فیلدهای بدون مقدار را خواهیم داشت و چنانچه دادهها از منابع مختلف مثل پایگاه دادههای مختلف یا سیستم اطلاعاتی مبتنی بر وب گرفته شوند با توجه به نمایشهای دادهای مختلف خطاها بیشتر بوده و پاکسازی دادهها اهمیت بیشتری پیدا خواهد کرد.
با اندکی توجه به مجموعهای از دادهها متوجه خواهیم شد که از این قبیل اشکالات در بسیاری از آنها وجود دارد. مسلماً هدف از گردآوری آنها، تحلیل و بررسی و استفاده از دادهها برای تصمیم گیریها است. بنابراین وجود دادههای ناقص یا ناصحیح باعث میشود که تصمیمها یا تحلیلهای ما هم غلط باشند. به پروسه تکراری که با کشف خطا و تصحیح آنها آغاز و با ارائه الگوها به اتمام میرسد، پاکسازی دادهها گفته میشود.
یکپارچهسازی (Integration): این فاز شامل ترکیب دادههای دریافتی از منابع اطلاعاتی مختلف، استفاده از متادادهها برای شناسایی، حذف افزونگی دادهها، تشخیص و رفع برخوردهای دادهای میباشد.
یکپارچه سازی دادهها از سه فاز کلی تشکیل شده است:
شناسایی فیلدهای یکسان: فیلدهای یکسان که در جدولهای مختلف دارای نامهای مختلف میباشند.
شناسایی افزونگیهای موجود در دادههای ورودی: دادههای ورودی گاهی دارای افزونگی هستند. مثلاً بخشی از رکورد در جدول دیگری وجود دارد.
مشخص کردن برخوردهای دادهای: مثالی از برخوردهای دادهای، یکسان نبودن واحدهای نمایش دادهای است. مثلاً فیلد وزن در یک جدول بر حسب کیلوگرم و در جدولی دیگر بر حسب گرم ذخیره شده است.
تبدیل دادهها (Data Transformation): در مجموعه داده های بزرگ، به نمونه هایی که از رفتار کلی مدل داده ای تبعیت نمیکنند و بطور کلی متفاوت یا ناهماهنگ با مجموعه باقیانده داده ها هستند، داده های نامنطبق گفته میشود.
دادههای نامنطبق میتوانند توسط خطای اندازه گیری ایجاد شونده یا نتیجه نوع داده ای درونی باشند. برای مثال اگر سن فردی در پایگاه داده 1- باشد، مقدار فوق قطعا غلط است و با یک مقدار پیش فرض فیلد "سن ثبت نشده" می تواند در برنامه مشخص گردد.
کاهش دادهها (Reduction): در این مرحله، عملیات کاهش دادهها انجام میگیرد که شامل تکنیکهایی برای نمایش کمینه اطلاعات موجود است.
این فاز از سه بخش تشکیل میشود:
کاهش دامنه و بعد: فیلدهای نامربوط، نامناسب و تکراری حذف میشوند. برای تشخیص فیلدهای اضافی، روشهای آماری و تجربی وجود دارند؛ یعنی با اعمال الگوریتمهای آماری و یا تجربی بر روی دادههای موجود در یک بازه زمانی مشخص، به این نتیجه میرسیم که فیلد یا فیلدهای خاصی، کاربردی در انبار داده نداشته و آنها را حذف میکنیم.
فشرده سازی دادهها: از تکنیکهای فشردهسازی برای کاهش اندازه دادهها استفاده میشود.
کد کردن دادهها: دادهها در صورت امکان با پارامترها و اطلاعات کوچکتر جایگزین میشوند.
٣- بارگذاری داده های پالایش شده
پس از انجام مراحل استخراج و پالایش نوبت به بارگذاری دادهها در انبار دادهها است. معمولا در این مرحله فقط عمل بارگذاری انجام میگیرد اما گاهی ممکن است انجام یکی از مراحل پالایش در هنگام بارگذاری صورت گیرد. درانبار داده فیلدها در جاهای مختلفی تکرار می شوند و روابط بین جداول کمتر به چشم می خورند. علت آن هم افزایش سرعت پردازش اطلاعات هنگام گزارشات و عملیات آماری میباشد.
حال انبار دادهها با مقادیر اولیه ساخته شده است، اما این پایان کار نیست! هر روزه دادههای بیشتر و جدیدی به پایگاه دادهها اضافه میشود و باید شرایطی را فراهم کنیم تا این دادهها به صورت خودکار و بدون دخالت کاربر، پس از استخراج و پالایش در انبار داده بارگذاری شود.
پس از بارگذاری دادهها نوبت به استفاده از اطلاعات ذخیره شده در انبار دادهها است. این کار توسط ابزارهای گزارش گیری (Reporting Services)، دادهکاوی و OLAP انجام میشود.
مرکز دادهها یا Data Mart: انبار داده ها حجم عظیمی از اطلاعات را در واحد های منطقی کوچکتری به نام مرکز داده نگهداری می کند مرکز داده ها نمونه های کوچکی از انبارداده ها بوده و همانند آنها حاوی کپی هایی ثابت از داده هایی هستند که در موارد خاص استفاده می شوند.
حذف صفرهای سمت چپ عدد در SQL
برای اینکار فقط کافیست دادهها را به نوع int تبدیل کنید. برای درک بهتر این موضوع کوئری زیر را اجرا کنید.
create table #data (data varchar(10)) insert into #data select '12345' as data union all select '00123' as data union all select '0060' union all select '00101' union all select '00021' union all select '20000' select data as Before, case when convert(int,data) is not null then cast(cast(data as int) as varchar(10)) else data end as After from #data
ثبت رویدادها در SSIS
زمانی که با یک پکیج بزرگ و پیچیده سروکار داریم بررسی روند اجرای کامپننتها و خطایابی کمی سخت میشود. در چنین شرایطی وجود یک فایل یا جدولی که Log پکیج را در هر بار اجرا ذخیره کند ضروری است. در SSIS این امکان وجود دارد که از رویدادهای مختلف Log گرفته شود. این کار از دو طریق امکان پذیر است؛ مدیریت رخدادها با تنظیمات دستی و مدیریت رخدادها توسط SSIS Loging
در این مقاله روش اول را شرح میدهم و به روش دوم در مقالهای جداگانه خواهم پرداخت.
مدیریت رخدادها به صورت دستی
اولین روشی که قصد دارم به آن بپردازم، ذخیره Log به صورت دستی است. در این روش باید از سربرگ Event Handlers استفاده کنید. در این قسمت باید از منوی باز شوندهی Executable کامپننت مورد نظر و سپس از منوی باز شوندهی Event handler رخداد مورد نظر را انتخاب کنید.
برای انجام این کار مراحل زیر را انجام دهید.
۱- ابتدا توسط کوئری زیر یک جدول Log ایجاد کنید. از این جدول برای ذخیره خروجی رویدادها استفاده میشود.
CREATE TABLE [dbo].[Log]( [ID] [int] IDENTITY(1,1) NOT NULL, [PackageID] [uniqueidentifier] NULL, [Error] [nvarchar](max) NULL, [Source] [nvarchar](100) NULL, [PackageName] [nvarchar](100) NULL ) ON [PRIMARY] GO |
۲- در Control Flow با استفاده از Execute SQL Task و کوئری زیر یک پکیج ساده ایجاد کنید
select * from shop.Test
۳- به سربرگ Event Handlers رفته و از منوی باز شوندهی Executable کامپننت Execute SQL Task و از منوی باز شوندهی Event handler رخداد onError را انتخاب کنید. برروی Click here to create an ‘onError’ event handler for executable ‘Execute SQL Task’ کلیک کنید تا فعال شود.
۴- از جعبه ابزار یک Execute SQL Task به این قسمت اضافه کنید.
۵- برروی Execute SQL Task دوبار کلیک کنید تا صفحه مربوط به تنظیمات آن باز شود. از کوئری زیر در قسمت SQL Statement استفاده کنید.
insert into Log(PackageID,Error,Source,PackageName) values (?, ?, ?, ?) |
۶- از لیست سمت چپ به قسمت Parameter Mapping رفته و مطابق با شکل زیر آن را تنظیم کنید.
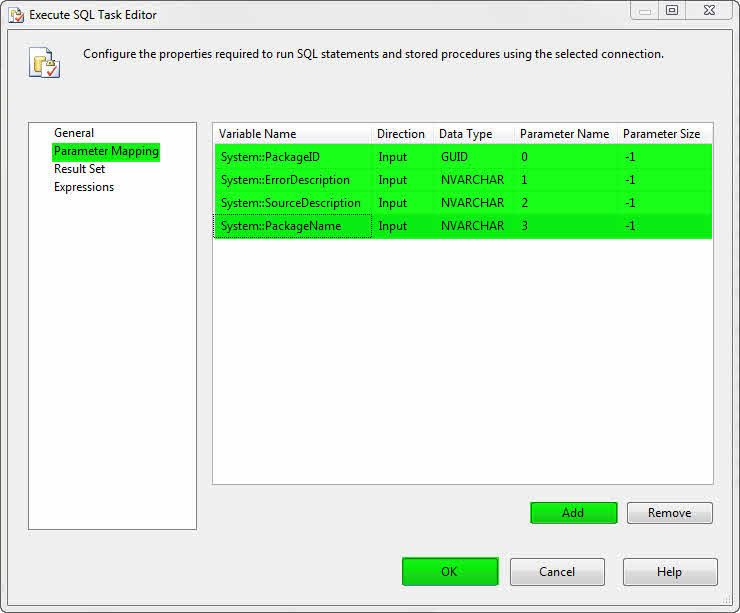
توسط کلید F5 پکیج را اجرا کنید. از آنجایی که جدولی با نام Test وجود ندارد پکیج با خطا مواجه میشود و در این لحظه کامپننت Execute SQL Task که در سربرگ Event Handlers ایجاد شده است شروع به کار میکند و از طریق پارامترهایی که به آن تخصیص دادیم مشخصات مورد نظر را به جدول Log ساخته شده در ابتدای آموزش انتقال میدهد.
در پایان جدول Log به شکل زیر میباشد.

پشتیبانگیری خودکار از بانکاطلاعاتی توسط MaintenancePlan Wizard
فایل پشتیبان (Backup) یک جزء اساسی و جدا نشدنی در حفظ و نگه داری دادهها است. بانکهای اطلاعاتی که وظیفه ذخیره دادهها را بر عهده دارند نیز از این قاعده مستثنی نیستند و در واقع میتوان گفت که فایلهای پشتیبانی در بانکهای اطلاعاتی حیاتی هستند.
روشهای گوناگونی برای گرفتن فایل پشتیبان از بانک اطلاعاتی وجود دارد و گاهی برای انجام اینکار نیاز به کوئریهای پیچیده است. در این پست قصد دارم به یک روش ساده جهت پشتیبان گیری خودکار بپردازم.
در 2008 SQL Server برای اینکار از Maintenance Plan Wizard استفاده میکنیم. البته Maintenance Plan Wizard کارهای مختلفی انجام میدهد که یکی از این کارها Backupگیری است.
برای انجام این کار مراحل زیر را انجام دهید.
۱- ابتدا مطمئن شوید که SQL Server Agent در حالت Start قرار دارد.
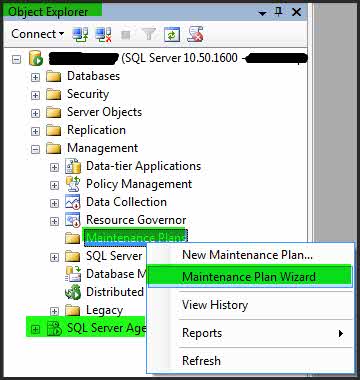
۲- در Object Explorer به قسمت Maintenance رفته و برروی Maintenance Plans کلیک راست کنید و از منوی باز شده Maintenance Plan Wizard را انتخاب نمایید.
۳- در صفحهی Select Plan Properties نام دلخواه خود را در قسمت Name وارد کرده و گزینهی Separate schedules for each task را انتخاب کنید.
با انتخاب این گزینه میتوانید در ادامه زمانبندی اجرای عملیات پشتیبان گیری را مدیریت کنید.
۴- برروی Next کلیک کنید.
۵- در صفحهی Select Maintenance Tasks گزینه Back Up Databases(Full) را انتخاب کنید.
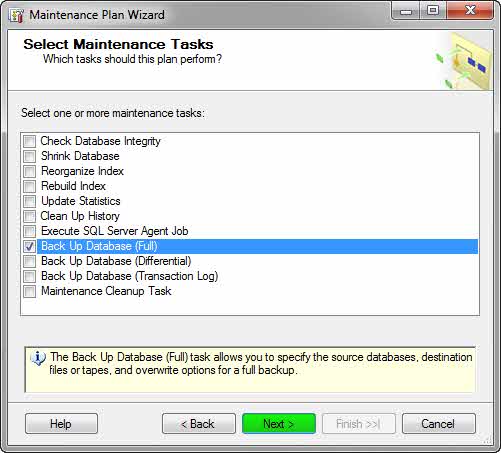
همانطور که مشاهده میکنید، Maintenance Plans کارهای مختلفی انجام میدهد که یکی از آنها پشتیبان گیری است.
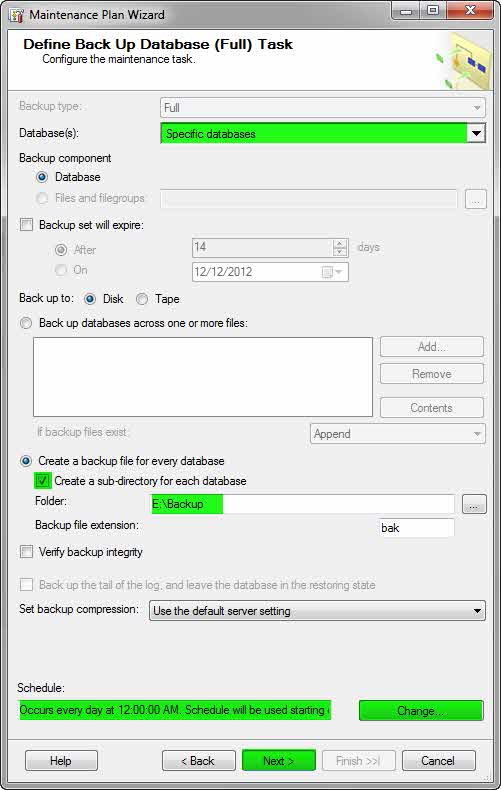
۶- دوبار Next کنید تا به صفحهی Define Back Up Database (Full) Task برسید. در این صفحه تنظیمات مربوط به ایجاد فایل پشتیبان قرار دارد.
این تنظیمات شامل، انتخاب بانک اطلاعاتی، محل ذخیره سازی فایل پشتیبان و زمانبندی پشتیبانگیری است. مطابق شکل زیر تنظیمات را انجام دهید و زمانبندی پشتیبان گیری را با کلیک برروی Change انجام دهید.
۷- مراحل را ادامه دهید تا پس از کلیک بر روی Finish مراحل کار به شکل زیر تمام شود.
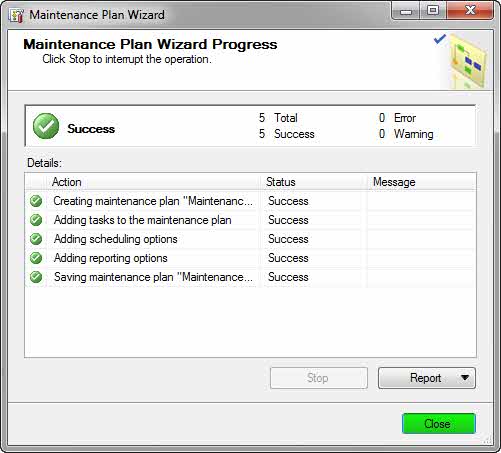
حال در زمان و تاریخ مشخص شده از بانک اطلاعتی شما فایل پشتیبان در آدرس تعیین شده، گرفته میشود.
مقایسه رکوردهای دو جدول و ثبت نتایج مقایسه
برای مقایسه اطلاعات دو جدول راههای زیادی وجود دارد. یکی از این روشها را در اینجا شرح دادم. اما اگر بخواهیم پس از مقایسه اطلاعات دو جدول آنها را دقیقا مشابه هم کنیم، باید از کوئریهای پیچیده جهت انتقال اطلاعات و یکسان سازی استفاده کنیم.
برای حل این مسئله روش بهتر و سادهتری نیز وجود دارد. TableDiff این امکان را برای ما فراهم میکند که بتوانیم رکوردهای دو جدول را با هم مقایسه و مطابق کنیم. در واقع TableDiff با مقایسهی تمامی رکوردهای جدول A با تمامی رکوردهای جدول B اختلافات را شناسایی ذخیره میکند.
جهت استفاده از TableDiff مراحل زیر را انجام دهید.
۱- ابتدا باید از نصب بودن TableDiff در SQL اطمینان حاصل کنیم. برای اینکار به آدرس C:\Program Files\Microsoft SQL Server\100\COM\ رفته تا فایل tablediff.exe را مشاهده کنید.
۲- فعال کردن دسترسی به تابع xp_cmdshell.
اجرای دستورات tablediff از طریق تابع xp_cmdshell امکان پذیر است. برای فعال کردن این تابع از دستور زیر استفاده کنید.
EXEC sp_configure 'show advanced options', 1 GO RECONFIGURE GO EXEC sp_configure 'xp_cmdshell', 1 GO RECONFIGURE GO |
۳- دو جدول مشابه با نامهای A و B در یک بانک اطلاعاتی به نام Shop ایجاد کنید. در جدول A چند سطر رکورد وارد کنید.
دقت داشته باشید که این جداول حتما باید فیلدهای یکسان داشته باشند.
۴- با اجرای کوئری زیر دو جدول A و B با هم مقایسه میشوند و نتیجهی آن در فایل Result.sql در درایو C ذخیره میشود.
exec master..xp_cmdshell'"C:\Program Files\Microsoft SQL Server\100\COM\tablediff.exe" -sourceserver (local) -sourcedatabase Shop -sourcetable A -destinationserver (local) -destinationdatabase Shop -destinationtable B -f C:\ Result.sql' |
۵- با اجرای کوئری ساخته شده در فایل Result.sql اطلاعات جدول B همانند اطلاعات جدول A خواهد شد.