هوش تجاری (Business Intelligence)
به اشتراک بگذاریم برای یادگیری، یاد بگیریم برای به اشتراک گذاریهوش تجاری (Business Intelligence)
به اشتراک بگذاریم برای یادگیری، یاد بگیریم برای به اشتراک گذاریمعرفی الگوریتم های داده کاوی
همانطور که در اینجا گفته شد الگوریتم های داده کاوی به پنج دسته کلی تقسیم می شوند. در این مقاله هر یک از الگوریتم های داده کاوی را به صورت مختصر شرح میدهم.
الگوریتم وابستگی(Association algorithm)
الگوریتم وابستگی نوعی آنالیز پیوندی است که برای تشخیص رفتار یک رویداد و یا یک پروسهی خاص استفاده میشود. این الگوریتم از دو بخش شرط و نتیجه تشکیل شده. بخش شرط یک آیتم خاص از اطلاعات را کشف و در بخش نتیجه آیتمی دیگر از اطلاعات که وابسته به شرط است را پیدا میکند. در واقع شرحی از دو کلمهی "اگر" و "پس" ، برای کشف رابطههای ناشناخته میان اطلاعات است. برای مثال، میتوان گفت که "اگر" شخصی چکش بخرد "پس" به احتمال 80 درصد میخ هم خریداری میکند.
الگوریتم وابستگی بسیار مفید است چراکه توسط آن میتوانیم رفتار مشتریان را تجزیه و تحلیل و پیشبینی کنیم. بعلاوه این الگوریتم نقش مهمی در تحلیل اطلاعات سبد خرید و چیدمان محصولات دارد که در نتیجه سبب میشود تا کالاها را به صورت هدف دار به مشتریان پیشنهاد دهیم.
الگوریتم خوشهبندی(Clustering algorithm)
خوشهبندی از جمله الگوریتمهای دستهبندی دادهکاوی است. الگوریتم خوشهبندی اطلاعاتی را که ویژگیهای نزدیک به هم و مشابه دارند را در قطعههایی جداگانه که به آن خوشه گفته میشود قرار میدهد. به بیان دیگر خوشهبندی همان دستهبندیهای سادهای است که در کارهای روزانه انجام میدهیم. وقتی با یک مجموعه کوچک از صفات روبرو باشیم این دسته بندی به سادگی قابل اجراست، برای مثال در یک مجموعه از خودکارهای آبی، مشکی، قرمز و سبز به راحتی میتوانیم آنها را در 4 دسته قرار دهیم اما اگر در همین مجموعه ویژگیهای دیگری مثل سایز، شرکت سازنده، وزن، قیمت و... مطرح باشد کار کمی پیچیده میشود. حال فرض کنید در یک مجموعه متشکل از هزاران رکورد و صدها ویژگی قصد دسته بندی دارید، چگونه باید این کار را انجام دهید؟!
بخش بندی دادهها به گروهها یا خوشههای معنادار به طوری که محتویات هر خوشه ویژگیهای مشابه و در عین حال نسبت به اشیاء دیگر در سایر خوشهها غیر مشابه باشند را خوشهبندی میگویند. از این الگوریتم در مجموعه دادههای بزرگ و در مواردی که تعداد ویژگیهای داده زیاد باشد استفاده میشود.
گاهی اوقات ممکن است با مشاهده اولیه، خوشهبندی انجام شده منطقی به نظر نرسد اما با کمی تحلیل متوجهی دقت این الگوریتم میشوید.
الگوریتم درخت تصمیم(Decision Trees algorithm)
درخت تصمیم یکی از قویترین و پرکاربردترین الگوریتمهای دادهکاوی است که برای کاوش در دادهها و کشف دانش کاربرد دارد. این الگوریتم دادهها را به مجموعههای مشخصی تقسیم میکند. هر مجموعه شامل چندین زیر مجموعه از دادههای کم و بیش همگن که دارای ویژگیهای قابل پیش بینی هستند تقسیم میشود. برای مثال فرض کنید که اطلاعاتی از محصولات فروخته شده خود دارید. با بررسی این اطلاعات مشخص میشود که تعداد 9 فروش از 10 فروش محصول دوچرخه توسط افراد 15 تا 25 ساله انجام گرفته است و تنها یک فروش برای افراد بالای 25 سال داشتهاید. از این اطلاعات میتوان نتیجه گرفت که سن مشتری نقش مهمی در فروش دوچرخههای شما دارد.
الگوریتم درخت تصمیم نیز اینگونه عمل میکند، در مورد یک هدف خاص چندین ویژگی را تجزیه و تحلیل کرده و شرایط را برای پیشبینی و هدفمندی فروش فراهم میکند.
الگوریتم رگرسیون خطی(Linear Regression algorithm)
رگرسیون فن و تکنیکی آماری برای بررسی و مدل سازی روابط میان دادهها است. رگرسیون خطی از فرمولهای مناسبی جهت محاسبه مقادیر A و B برای رسیدن به پیش بینی C استفاده میکند.
رگرسیون در دادهکاوی تنوع دیگری از درخت تصمیم است به شکلی که به محاسبهی یک ارتباط خطی میان متغیرهای وابسته و غیر وابسته کمک میکند. محاسبههای انجام شده در پیش بینیها کاربرد دارند.
الگوریتم بیز(Naive Bayes Algorithm)
این الگوریتم بر پایهی قضیه بیز برای مدل سازی پیشگویانه ارائه شده است. قضیه بیز از روشی برای دستهبندی پدیدهها بر پایه احتمال وقوع یا عدم وقوع یک پدیده استفاده میکند و احتمال رخ دادن یک پدیده محاسبه و دسته بندی میشود. به مثال زیر توجه کنید:
بخش بازاریابی شرکت قصد دارد به عنوان یک استراتژی تبلیغاتی برای مشتریان بالقوه نامههای تبلیغاتی ارسال کند. از طرفی برای کاهش هزینهها قصد دارد فقط به مشتریانی که علاقهمند هستند و ممکن است واکنش مثبت نشان دهند نامهها را ارسال کند. در پایگاه داده شرکت اطلاعاتی از افرادی که به نامههای قبلی واکنش نشان داده بودند ذخیره شده است.
آنها میخواهند ببینند که به وسیله اطلاعات آماری مانند سن، موقعیت مکانی و به وسیله مقایسه پتانسیل مشتریان بالقوه با مشتریانی که مشخصات مشترک دارند و اینکه چه اشخاصی در گذشته از شرکت خریداری کرده است می توانند به واکنشها و پاسخهای دریافتی خود بی افزاییند.
به طور کلی می خواهند تفاوت مشتریانی که محصول خریداری کردهاند و مشتریانی که هیچ محصولی نخریدهاند را پیدا کنند.
با استفاده از الگوریتم بیز سازمانها برای بازاریابی میتوانند نتیجه را برای یک مشتری خاص به سرعت پیش بینی کنند، بنابراین مشخص می شود که کدام مشتری علاقه بیشتری به پاسخ دادن نامه دارد.
الگوریتم شبکههای عصبی(Neural Network Algorithm)
شبکه های عصبی از پرکاربردترین و عملی ترین روشهای مدلسازی مسائل پیچیده و بزرگ که شامل صدها متغیر هستند، میباشد. شبکه های عصبی میتوانند برای مسائل طبقهبندی (که خروجی یک کلاس است) یا مسائل رگرسیون (که خروجی یک مقدار عددی است) استفاده شوند.
هر شبکه عصبی شامل یک لایه ورودی است که هر گره در این لایه معادل یکی از متغیرهای پیش بینی میباشد. این الگوریتم برای تجزیه و تحلیل دادههای پیچیدهای که انجام آن توسط سایر الگوریتمها به سادگی انجام نمیگیرد کاربرد دارد.
الگوریتم شبکههای عصبی در موارد زیر پیشنهاد میشود:
بازاریابی، مانند رسیدن به موفقیت در ارسال نامههای تبلیغاتی
پیشبینی حرکت سهام، نوسانات نرخ ارز و یا سایر اطلاعات سیال مالی که دارای پیشینه هستند
تجزیه و تحلیل فرآیندهای تولیدی و صنعتی
متن کاوی و هر مدل پیشبینی که شامل تحلیلهای پیچیدهای از ورودیهای زیاد و خروجیهای نسبتا کم باشد.
الگوریتم رگرسیون منطقی یا لجستیک(Logistic regression algorithm)
رگرسیون منطقی یک روش آماری برای مدل سازیهایی که نتایج دودویی دارند، است. برای شرایطی که هدف برآورد مفاهیمی چون "رخ دادن" یا "رخ ندادن" است مانند نتیجهی یک مسابقه فینال که دو حالت بیشتر ندارد.
ممکن است مقادیر پیشبینی شده بی معنی باشد و یا در عمل تفسیر پذیر نباشند یا امکان مقایسه مقادیر پیشبینی با هم نباشد که ممکن است از نتایج الگوریتمهای درخت تصمیم و رگرسیون خطی باشد در چنین شرایطی برای رفع ابهامات از این الگوریتم استفاده میشود. از این مدل برای بدست آوردن نتایج بهینه پیشبینی استفاده میشود. از رگرسیون لجستیک میتوان به عنوان تنوع دیگری از الگوریتم شبکههای عصبی نام برد. رگرسیون منطقی یک مدل آماری رگرسیون برای متغیرهای باینری است.
الگوریتم خوشهبندی زنجیرهای(Sequence Clustering algorithm)
این الگوریتم شباهت زیادی به خوشهبندی دارد اما برخلاف الگوریتم خوشهبندی، خوشهها را بر پایه یک مدل جستجو میکند و نه بر اساس شباهت رکوردها. این مدل زنجیرهای رویدادها را بر اساس زنجیرهی مارکوف ایجاد میکند. در زنجیرهی مارکوف توزیع احتمال شرطی حالت بعدی تنها به حالت فعلی بستگی دارد و به وقایع قبل از آن وابسته نیست. زنجیره مارکوف ابتدا یک ماتریسی از ترکیب تمامی وضعیتهای شدنی(امکان پذیر) ایجاد میکند و سپس در هر خانهی ماتریس احتمالات حرکت از یک وضعیت به وضعیت دیگر را ثبت میکند. از طریق این احتمالات محاسباتی انجام میشود که در نتیجه یک مدل بر پایهی آن ایجاد میشود. به مثال زیر توجه کنید:
فرض کنید برای فروش اینترنتی محصولات خود یک وبسایت دارید که اطلاعات کاربران و صفحات بازدید شده ثبت میشود. هر مشتری برای خرید باید اطلاعاتی از خود در سایت ثبت کند و با هر کلیک مشتریان، اطلاعاتی از مشتری و صفحه ثبت میشود. با استفاده از الگوریتم خوشهبندی زنجیرهای بر روی این اطلاعات میتوانید مشتریانی که کلیکها و الگوهای مشابه داشتهاند را گروه بندی کنید. با تحلیل گروهبندیها میتوانید بفهمید که چه کاربرانی به سایت شما میآیند، کدام صفحات سایت شما پر بازدیدتر هستند و ارتباط بیشتری با فروشهای شما دارند و صفحهی بعدی از سایت شما که بازدید خواهد شد، کدام است.
الگوریتم سریهای زمانی(Time Series Algorithm)
روش سریهای زمانی یکی دیگر از روشهای پیش بینی است. این مدل نوعی الگوریتم رگرسیون است که برای پیش بینی مقادیر پیوسته مانند فروش محصولات در طول زمان استفاده میشود. سایر الگوریتمهای ماکروسافت مانند درخت تصمیم نیازمند ستونهای اضافی از اطلاعات به عنوان ورودی برای روند پیش بینی می باشند در حالی که در الگوریتم سری زمانی نیازی به این ستونهای اضافی نمی باشد. در این الگوریتم می توان از خروجی یک سری، بر پایه رفتار سری دیگر استفاده نمود.
در واقع سریهای زمانی، مجموعهای اطلاعات از افزایشهای متوالی دادهها که در یک دوره زمانی جمع آوری شده اند میباشد. دنیای پیرامون ما ثابت نیست و متغیرهای بسیاری با تغییر زمان ارزش خود را تغییر میدهند، ترتیب ارزشهای یک متغیر درطول زمان،یک سری زمانی را تشکیل میدهد.
هدف اصلی از جمع آوری دادههای سری زمانی پیشبینی و یا پیشگویی درباره مقادیر آینده است. به مثالهای زیر توجه کنید.
یک کارخانه به پیشبینی درخواستهای مشتریان در ماههای آینده جهت برنامه ریزی تولید نیاز دارد.
یک وب سایت باید رشد کاربری و ترافیک کاربران را به منظور استفاده از یک سخت افزار مناسب تخمین بزند.
یک فروشگاه باید فروش محصولات را به منظور بهینه سازی انبار، پیشبینی نماید.
معرفی و نحوه کار با SSRS
هدف از ایجاد پروژههای هوش تجاری، تحلیل و آنالیز دادهها و کشف دانش از اطلاعات است. رسیدن به این مهم با ایجاد گزارشات هدفمند برای مدیران و کارشناسان مربوطه میسر میشود؛ SSRS یک ابزار گزارش ساز است که با استفاده از یکسری کامپننت و سریس، راه را برای ایجاد گزارشات هموار کرده است. ماکروسافت این ابزار را به عنوان مکملی برای پروژههای هوشمندی کسب و کار فراهم کرده. استفاده از SSRS حتما نیازمند انبار داده، OLAP و Data Mining نیست بلکه میتوان از این ابزار در بانکهای اطلاعاتی رابطهای نیز استفاده کرد و گزارشات مختلف ایجاد نمود.
علاوه بر SSRS نرم افزار اکسل نیز توانایی ایجاد گزارشات را دارد، اما یکی از بهترین نرم افزارهای داخلی تولید گزارش، سامانه هوش تجاری و داشبورد مدیران مبنا است که قابلیت تولید داشبورد برای مدیران را نیز دارد.
ایجاد یک گزارش با استفاده از SSRS
در SSRS به دو طریق wizard و دستی میتوان گزارش ایجاد کرد. در این قسمت نحوه ایجاد گزارش توسط wizard را شرح میدهم.
1- به مسیر FileàNew Project در SQL Server Business Intelligence Development Studio رفته و Report Server Project Wizard رانتخاب کنید.
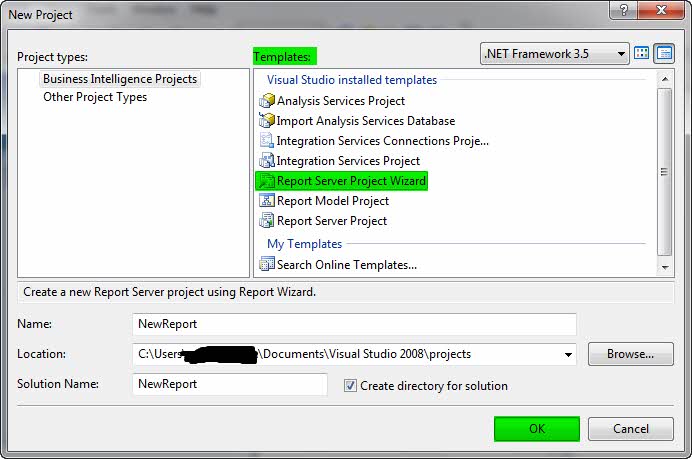
2- در صفحهی Welcome to the Report Wizard بر روی Next کلیک کنید.
3- در صفحهی Select the Data Source نام و نوع منبع دادهی خود را انتخاب کنید و با کلیک بر روی Edit تنظیمات مربوط به بانک اطلاعاتی را انجام دهید.
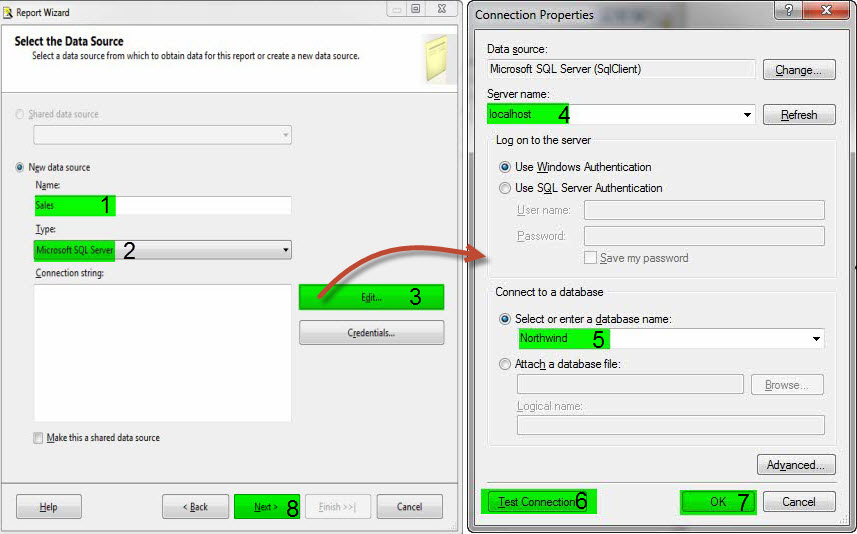
4- در صفحهی Design the Query، کوئری مورد نظر خود را وارد کنید. برای اینکار میتوانید از Query Builder نیز استفاده کنید.
در صورت استقاده از بانک اطلاعاتی Northwind، از کوئری زیر استفاده کنید.
SELECT p.ProductName, c.CategoryName, ROUND(SUM(od.UnitPrice * (1 - od.Discount) * od.Quantity), 2) AS Sales FROM Products AS p INNER JOIN [Order Details] AS od ON p.ProductID = od.ProductID INNER JOIN Categories AS c ON c.CategoryID = p.CategoryID GROUP BY od.ProductID, p.ProductName, c.CategoryName |
5- در صفحهی Select the Report Typeمیتوانید نوع گزارش خود را انتخاب کنید. نوع جدولی(Tabular) را انتخاب کرده و بر روی Next کلیک کنید.
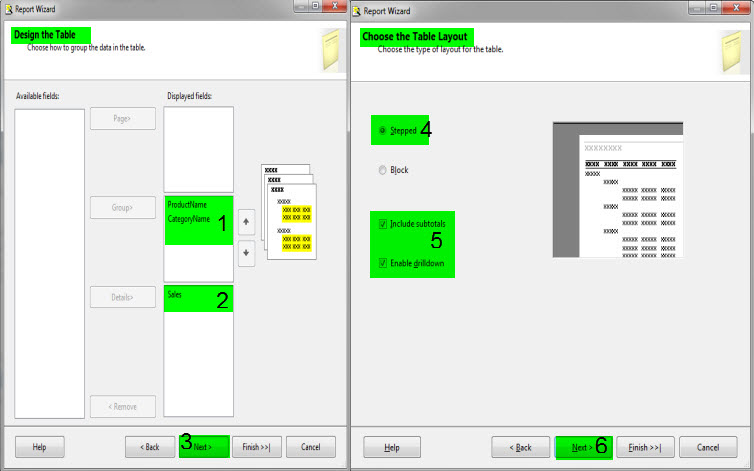
6- تنظیمات صفحهی Design the Table و Choose the Table Layout را مطابق تصاویر زیر انجام دهید.
7- در مرحله بعد باید محل و آدرس Deploy شدن گزارش مشخص شود. بروری Finish کلیک کنید.
8- با اجرای پروژه گزارش ساخته شده را مشاهده خواهید کرد.
تبدیل تاریخ شمسی به میلادی،میلادی به شمسی ومیلادی به قمری در SQL
با کمی جستجو در اینترنت مشاهده خواهید کرد که توابع زیادی برای تبدیل تاریخ وجود دارد اما برخی از آنها یا کامل نیستند و یا اشکالاتی دارند. در این پست توابع تبدیل تاریخ شمسی به میلادی، میلادی به شمسی و میلادی به قمری را در کنار هم قرار دادهام. در نهایت نیز یک تابع جهت بدست آوردن سن افراد از تاریخ تولدشان معرفی شده است. این توابع برای تبدیل در بعضی تاریخ ها مشکلاتی داشتند که با یادآوری خوانندگان بلاگ رفع شد.
لازم به ذکر است که تابع تبدیل تاریخ میلادی به شمسی توسط آقای رضا راد نوشته شده است.
توابع تبدیل تاریخ میلادی به شمسی و شمسی به میلادی را از اینجا دریافت کنید.
پس از دانلود و اجرای کوئری ها، از طریق دستورات زیر میتوانید تبدیل تارخ میلادی به شمسی و شمسی به میلادی را انجام دهید.
از کوئری زیر برای مشاهده نتیجه استفاده کنید.
select dbo.GregorianToPersian('1980/01/01')
select dbo.ShamsitoMiladi('1358/10/11')
تبدیل تاریخ میلادی به قمری
از دستور زیر برای تبدلی تاریخ میلادی به قمری استفاده کنید.
SELECT CONVERT (nvarchar(30),GETDATE(),130) as Date
برای بدست آوردن سن از دستور زیر استفاده کنید.
SELECT DateDiff(yy , (select dbo.ShamsitoMiladi ('1365/01/01') ), GetDate())
مدلهای چند بعدی و جدولی در SQL Server 2012
در BI برای ایجاد گزارشات چند بعدی و تحلیل دادهها از مدل سازی چند بعدی (Multidimensional Modeling) استفاده میشود. مدل سازی چند بعدی بر پایهی روش سنتی تحلیلهای بر خط (OLAP) ؛ مکعبهای دادهای، معیارها و ابعاد را ایجاد میکند. در OLAP چند تکنیک ذخیره سازی وجود دارد و به واسطهی آن، با وجود حجم زیادی از دادهها سرعت پاسخ به کوئریها کوتاه است.
با انتشار SQL Server 2012 از سوی ماکروسافت قابلیتها و ابزارهای جدیدی نیز به SQL اضافه شد. یکی از این قابلیتها در بخش هوش تجاری، مدل سازی جدولی یا فهرستی (Tabular Modeling ) میباشد که نوع دیگری از مدل سازی است. از این نوع مدل سازی نیز در ایجاد گزارشات و تحلیل دادهها استفاده می شود.
مدل سازی جدولی بر اساس PowerPivot و برای Excel 2010 ایجاد شده است. در مدل سازی جدولی دادهها در جداول رابطهای سازماندهی میشوند و از دو روش In-Memory و DirectQuery برای ذخیرهسازی استفاده میکند و به همین دلیل سرعت دسترسی به دادهها بسیار بالا است. این نوع مدل سازی برای افرادی که سالهاست با برنامههایی همچون Excel کار میکنند بسیار مناسب است.
جهت استفاده از حالت جدولی در SQL باید در هنگام نصب برنامه مشخص نمود که قصد استفاده از مدلسازی جدولی را داریم.
در جدول زیر برخی از مهمترین ویژگیهای دو مدل چند بعدی و جدولی با یکدیگر مقایسه شدهاند.
ویژگیها | مدلسازی چند بعدی | مدلسازی جدولی | توضیحات |
مدت زمان ایجاد یک Solution | زیاد | کم | در مدلسازی جدولی سرعت ایجاد Solution بسیار بالاتر است. |
مدت زمان یادگیری | زیاد | کم | یادگیری مدلسازی جدولی بسیار سریعتر از مدلهای چند بعدی است. |
نحوه ارتباط میان دادهها | - یک به چند - چند به چند | - یک به چند - چند به چند با استفاده از عبارات DAX | در مدلسازی جدولی فقط با استفاده از DAX میتوان به یک ارتباط چند به چند دست پیدا کرد. |
سلسله مراتبها | - سلسله مراتبهای استاندارد - سلسله مراتبهای پدر فرزندی
| - سلسله مراتبهای استاندارد - سلسله مراتبهای پدر فرزندی با استفاده از DAX | در مدلسازی جدولی فقط با استفاده از DAX میتوان سلسله مراتبهای پدر فرزندی ایجاد نمود. |
ویژگیهای اضافی در مدلسازی | Perspectives, translations, actions, drillthrough, stored procedures, and write-back. | Perspectives and drillthrough. | در مدل سازی جدولی فقط میتوان از drillthrough و Perspectives استفاده نمود. |
زبان برنامه نویسی | MDX | DAX | در مدل سازی جدولی برای نوشتن عبارات محاسباتی از DAX استفاده میشود. |
عبارات محاسباتی | تمامی عبارات محاسباتی ساده و پیچیده | تمامی عبارات محاسباتی ساده و برخی از عبارات پیچیده | در مدل سازی جدولی نمیتوان از بسیاری عبارات محاسباتی پیچیده استفاده کرد. |
توابع تجمیعی | Sum, Count, Min, Max, Distinct Count, None, ByAccount, AverageOfChildren, FirstChild, LastChild, FirstNonEmpty, and LastNonEmpty. | Sum, Count, Min, Max, Average, DistinctCount, and various time intelligence functions like FirstDate, LastDate, OpeningBalanceMonth, and ClosingBalanceMonth. | در این قسمت نیز در مدل چند بعدی بهتر عمل شده است. |
کلیدهای ارزیابی عملکرد (KPIs) | دارد | دارد |
|
تبدیل نرخ ارز
| پشتیبانی توسط Business Intelligence Wizard | پشتیبانی توسط DAX |
|
حجم دادهها جهت دسترسی و ذخیرهسازی | چندین ترابایت | چند میلیون رکورد | مدلسازی جدولی برا حجم وسیعی از دادهها پیشنهاد نمیشود. |
منبع دادهها | بانکهای اطلاعاتی رابطهای | - بانکهای اطلاعاتی رابطهای - فایلهای Excel - فایلهای متنی - OData feeds Azure Data Market- Analysis Services- |
|
ذخیرهسازی دادهها | -MOLAP -ROLAP | - In-Memory -DirectQuery | In-Memory تمامی دادهها در حافظه کش میشوند. DirectQuery دادهها در SQL Server 2012 ذخیره میشوند. |
فشرده سازی دادهها | معمولا تا 3x | معمولا تا 10x |
|
امنیت | - امنیت در سطح عضوهای دایمنشن | - امنیت در سطح هر سطر
|
|
با توجه به جدول بالا به نظر میرسد استفاده از مدلسازی جدولی برای سازمانهای کوچکی که حجم داده کمی دارند بسیار مفید، کم هزینه و مناسب باشد.
بدست آوردن تعداد سطرهای جدول
معمولا برای بدست آوردن تعداد سطرهای یک جدول از دستور زیر استفاده میشود.
Select count(*) from table_name
اما برای بدست آوردن تعداد سطرهای یک جدول روشهای دیگری نیز وجود دارد. هر یک از کوئریهای زیر این کار را انجام میدهند.
select sum(1) from table_name
select count(1) from table_name
'exec sp_spaceused ‘table_name
DBCC CHECKTABLE(‘table_name’)