هوش تجاری (Business Intelligence)
به اشتراک بگذاریم برای یادگیری، یاد بگیریم برای به اشتراک گذاریهوش تجاری (Business Intelligence)
به اشتراک بگذاریم برای یادگیری، یاد بگیریم برای به اشتراک گذاریمراحل و نحوه بارگذاری داده ها در انبار داده
پس از شناخت و تحلیل سازمان، اولین قدم برای ساخت یک پروژهی هوش تجاری ایجاد انبار داده است. بر اساس نیاز باید اطلاعات را از منابع مختلف استخراج و جمع آوری(Extract)، پالایش (Transform) و در یک پایگاه داده ذخیره (Load) کنیم. به عملیات استخراج، پالایش و بارگذاری، ETL گفته میشود. امروزه ابزارهای زیادی برای انجام فرآیند ETL وجود دارد که تا حدود زیادی دقت و سرعت انجام این عملیات را بالا برده است. هر یک از این مراحل جزئیاتی دارند که در ادامه به شرح آن میپردازم.
۱- استخراج دادهها از پایگاههای داده به یک مخزن واحد
شناخت منابع دادههای سازمان و استخراج دادههای ارزشمند از آنها یکی از اصلی ترین مراحل ایجاد انبار داده است. دادههایی که بایست در قالب انبار گرد هم آیند غالباً به صورت پراکنده تولید شدهاند. برای مثال در یک فروشگاه زنجیرهای دادهها از طریق کامپیوترهای مراکز خرید مختلف، دستگاههای خرید اتوماتیک (مثل دستگاههای خرید نوشابه یا روزنامه) و نرم افزارهای انبارداری و حسابداری، به دست میآیند. انبار داده برای انجام وظیفه خود که همان تحلیل دادهها است باید همه این دادهها را با هر قالبی که تولید میشوند به طور مرتب و دقیق دریافت نماید. استخراج دادهها در یک محیط واسط که کم و بیش شبیه انبار دادهها است صورت میگیرد.
۲- پالایش دادهها
دادههای استخراج شده را باید بررسی نماییم و در صورت نیاز تغییراتی در آنها ایجاد کنیم. دلیل این کار، استخراج اطلاعات از پایگاه دادههای مختلف و برطرف نمودن نیازهای سازمان است. معمولا تمامی مراحل پالایش دادهها در محیط واسط انجام میگیرد اما گاهی برخی از مراحل پالایش در هنگام بارگذاری در انبار داده انجام میشود.
در پالایش دادهها مراحل زیر انجام میشود.
پاکسازی دادهها (Data Cleaner): ممکن است در دنیای امروز میلیونها مجموعه داده وجود داشته باشد، اما به راستی تمام این مجموعه از دادهها بدون اشکال هستند؟ آیا تمامی مقادیر فیلدهای هر رکورد پر شده است و یا مقادیر داخل فیلدها دادههای صحیح دارند؟ اگر دادهها از منابع یکسان مثل فایلها یا پایگاههای دادهای گرفته شوند خطاهایی از قبیل اشتباهات تایپی، دادههای نادرست و فیلدهای بدون مقدار را خواهیم داشت و چنانچه دادهها از منابع مختلف مثل پایگاه دادههای مختلف یا سیستم اطلاعاتی مبتنی بر وب گرفته شوند با توجه به نمایشهای دادهای مختلف خطاها بیشتر بوده و پاکسازی دادهها اهمیت بیشتری پیدا خواهد کرد.
با اندکی توجه به مجموعهای از دادهها متوجه خواهیم شد که از این قبیل اشکالات در بسیاری از آنها وجود دارد. مسلماً هدف از گردآوری آنها، تحلیل و بررسی و استفاده از دادهها برای تصمیم گیریها است. بنابراین وجود دادههای ناقص یا ناصحیح باعث میشود که تصمیمها یا تحلیلهای ما هم غلط باشند. به پروسه تکراری که با کشف خطا و تصحیح آنها آغاز و با ارائه الگوها به اتمام میرسد، پاکسازی دادهها گفته میشود.
یکپارچهسازی (Integration): این فاز شامل ترکیب دادههای دریافتی از منابع اطلاعاتی مختلف، استفاده از متادادهها برای شناسایی، حذف افزونگی دادهها، تشخیص و رفع برخوردهای دادهای میباشد.
یکپارچه سازی دادهها از سه فاز کلی تشکیل شده است:
شناسایی فیلدهای یکسان: فیلدهای یکسان که در جدولهای مختلف دارای نامهای مختلف میباشند.
شناسایی افزونگیهای موجود در دادههای ورودی: دادههای ورودی گاهی دارای افزونگی هستند. مثلاً بخشی از رکورد در جدول دیگری وجود دارد.
مشخص کردن برخوردهای دادهای: مثالی از برخوردهای دادهای، یکسان نبودن واحدهای نمایش دادهای است. مثلاً فیلد وزن در یک جدول بر حسب کیلوگرم و در جدولی دیگر بر حسب گرم ذخیره شده است.
تبدیل دادهها (Data Transformation): در مجموعه داده های بزرگ، به نمونه هایی که از رفتار کلی مدل داده ای تبعیت نمیکنند و بطور کلی متفاوت یا ناهماهنگ با مجموعه باقیانده داده ها هستند، داده های نامنطبق گفته میشود.
دادههای نامنطبق میتوانند توسط خطای اندازه گیری ایجاد شونده یا نتیجه نوع داده ای درونی باشند. برای مثال اگر سن فردی در پایگاه داده 1- باشد، مقدار فوق قطعا غلط است و با یک مقدار پیش فرض فیلد "سن ثبت نشده" می تواند در برنامه مشخص گردد.
کاهش دادهها (Reduction): در این مرحله، عملیات کاهش دادهها انجام میگیرد که شامل تکنیکهایی برای نمایش کمینه اطلاعات موجود است.
این فاز از سه بخش تشکیل میشود:
کاهش دامنه و بعد: فیلدهای نامربوط، نامناسب و تکراری حذف میشوند. برای تشخیص فیلدهای اضافی، روشهای آماری و تجربی وجود دارند؛ یعنی با اعمال الگوریتمهای آماری و یا تجربی بر روی دادههای موجود در یک بازه زمانی مشخص، به این نتیجه میرسیم که فیلد یا فیلدهای خاصی، کاربردی در انبار داده نداشته و آنها را حذف میکنیم.
فشرده سازی دادهها: از تکنیکهای فشردهسازی برای کاهش اندازه دادهها استفاده میشود.
کد کردن دادهها: دادهها در صورت امکان با پارامترها و اطلاعات کوچکتر جایگزین میشوند.
٣- بارگذاری داده های پالایش شده
پس از انجام مراحل استخراج و پالایش نوبت به بارگذاری دادهها در انبار دادهها است. معمولا در این مرحله فقط عمل بارگذاری انجام میگیرد اما گاهی ممکن است انجام یکی از مراحل پالایش در هنگام بارگذاری صورت گیرد. درانبار داده فیلدها در جاهای مختلفی تکرار می شوند و روابط بین جداول کمتر به چشم می خورند. علت آن هم افزایش سرعت پردازش اطلاعات هنگام گزارشات و عملیات آماری میباشد.
حال انبار دادهها با مقادیر اولیه ساخته شده است، اما این پایان کار نیست! هر روزه دادههای بیشتر و جدیدی به پایگاه دادهها اضافه میشود و باید شرایطی را فراهم کنیم تا این دادهها به صورت خودکار و بدون دخالت کاربر، پس از استخراج و پالایش در انبار داده بارگذاری شود.
پس از بارگذاری دادهها نوبت به استفاده از اطلاعات ذخیره شده در انبار دادهها است. این کار توسط ابزارهای گزارش گیری (Reporting Services)، دادهکاوی و OLAP انجام میشود.
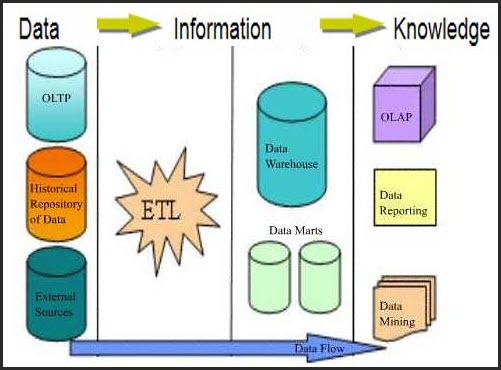
مرکز دادهها یا Data Mart: انبار داده ها حجم عظیمی از اطلاعات را در واحد های منطقی کوچکتری به نام مرکز داده نگهداری می کند مرکز داده ها نمونه های کوچکی از انبارداده ها بوده و همانند آنها حاوی کپی هایی ثابت از داده هایی هستند که در موارد خاص استفاده می شوند.
مهندس جان عالی بود
خسته نباشید.
سلام .
کلی کیف کردم وقتی شما را یافتم