هوش تجاری (Business Intelligence)
به اشتراک بگذاریم برای یادگیری، یاد بگیریم برای به اشتراک گذاریهوش تجاری (Business Intelligence)
به اشتراک بگذاریم برای یادگیری، یاد بگیریم برای به اشتراک گذاریواکشی دادهها از شیرپوینت و بارگذاری در SQL توسط SSIS
امروزه استفاده از شیرپوینت به عنوان ابزار ایجاد کننده وب سایت به دلیل سرعت بالا در ایجاد و راهاندازی بسیار گسترش پیدا کرده است و بسیاری از سازمانها از آن استفاده میکنند. بنابراین میتوان شیرپوینت را به عنوان منبع دادهها در نظر گرفت.
برای خواندن و بارگذاری دادههای شیرپوینت در SQL Server از طریق SSIS چندین روش وجود دارد که در این مقاله به یکی از بهترین و سادهترین آنها که استفاده از SharePoint Web services است، میپردازم.
ابتدا باید Features مربوط به SharePoint List Source and Destination را از اینجا دریافت کنید.
پس از دانلود، مطابق تصاویر زیر مراحل نصب را انجام دهید.
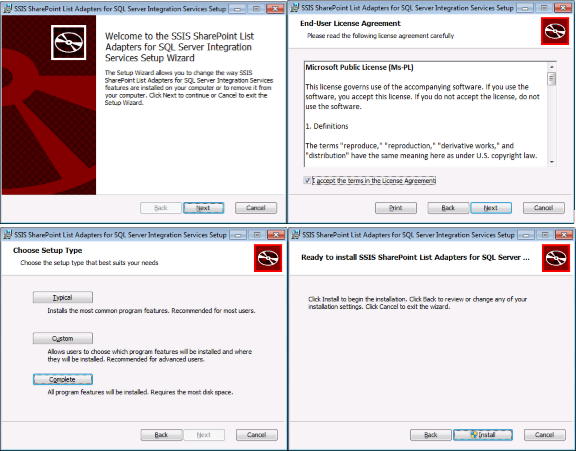
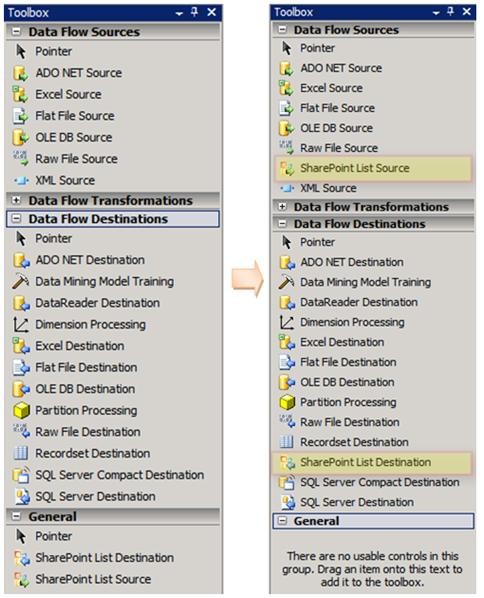
بعد از اتمام مراحل نصب باید کامپننتهای SharePoint List Source and Destination را به جعبه ابزار SSIS اضافه کنید. برای اینکار مراحل زیر را انجام دهید.
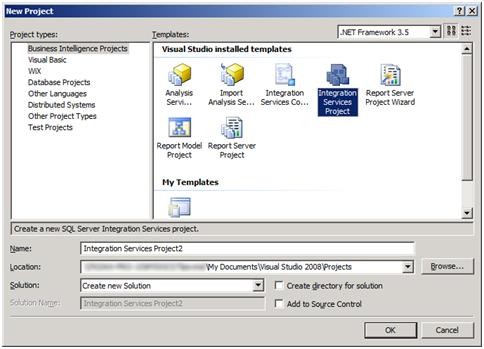
1- برنامه Business Intelligence Development Studio را باز کردهو مطابق تصویر زیر یک پروژهی جدید SSIS ایجاد کنید.
2- از منوی Tools گزینه Choose Toolbox Items را انتخاب کنید.
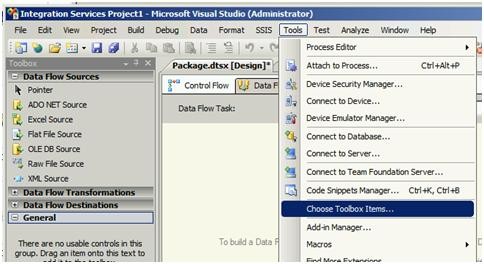
پنجره Choose Toolbox Items باز میشود.
3- از پنجره بازشده به سربرگ SSIS Data Flow Items رفته و چکباکس مربوط به SharePoint List Source و SharePoint List Destination را انتخاب نمایید. برروی Ok کلیک کنید.
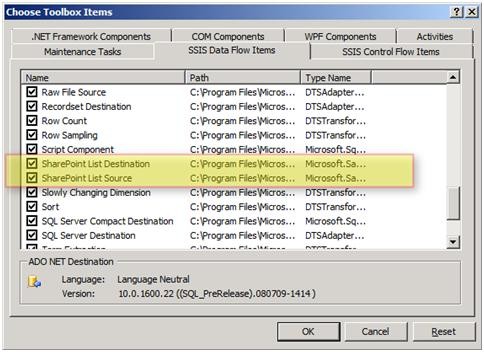
این دو کامپننت به قسمت General در جعبه ابزار SSIS اضافه میشوند. شما میتوانید هر یک از آنها را به محل مناسب خود منتقل کنید.
آماده سازی یک لیست شیرپوینت جهت انجام یک مثال
1- ایجاد لیستی با عنوان TestSharePointList که شامل اطلاعات زیر باشد.
نام: کارمندان
ستونها:
· شماره پرسنلی (نوع: عدد)
· نام کارمند(نوع: کاراکتر)
· جنسیت (انتخابی؛ انتخاب اول، زن انتخاب دوم، مرد)

ایجاد یک جدول در SQL مطابق با لیست ایجاد شده در شیرپوینت
1- وارد SSMS شده و یک بانک اطلاعاتی با نام TestDB ایجاد کنید.
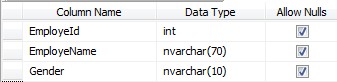
2- مطابق شکل زیر یک جدول با نام SharePointData ایجاد کنید.
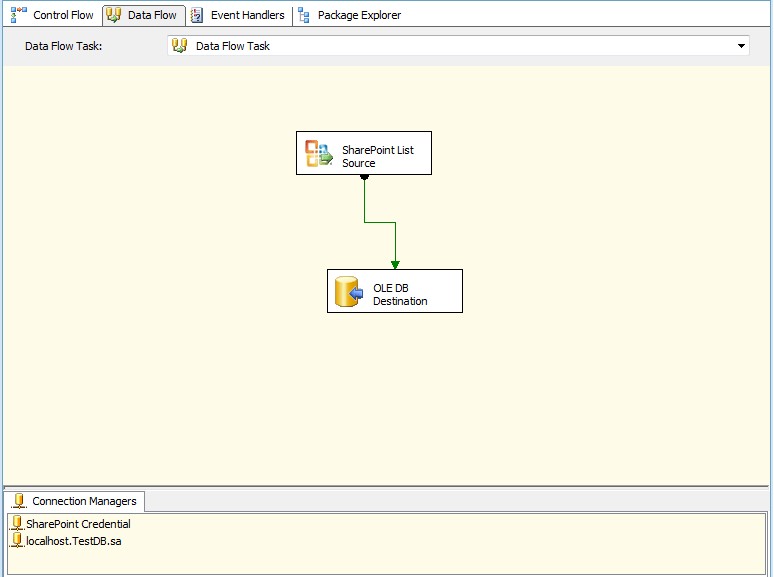
استخراج داده از لیست شیرپوینتی ساخته شده توسط SharePoint List Source
1- در این قسمت ابتدا باید یک اتصال دهنده شیرپوینتی ایجاد نمود. برای انجام اینکار مطابق تصاویر زیر عمل کنید.
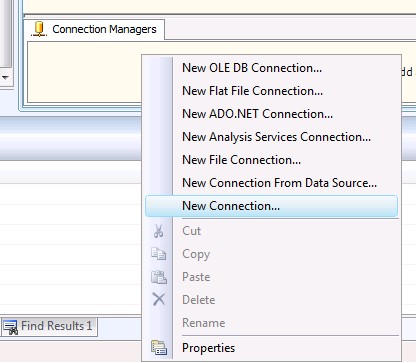
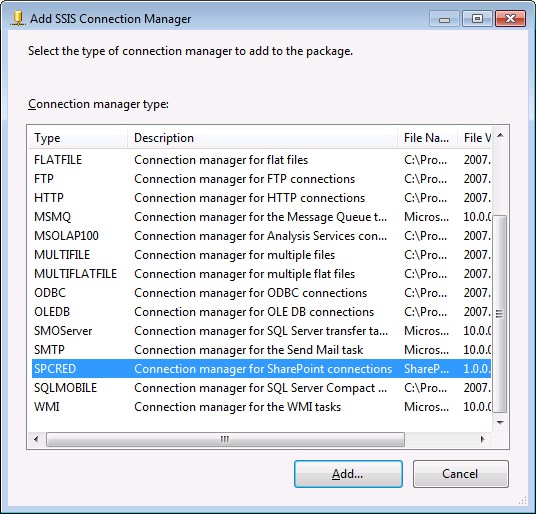
این اتصال دهنده پس از نصب Features مربوط به شیرپوینت که مراحل نصب آن در ابتدای مقاله توضیح داده شد، به لیست Add SSIS Conection Manager اضافه میشود.
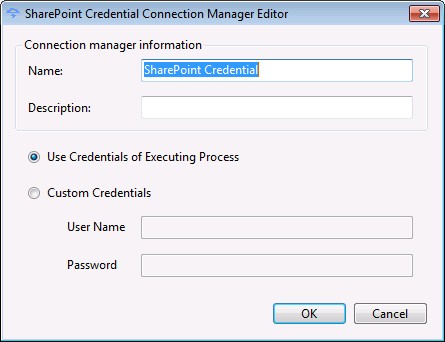
در صورتی که برای دسترسی به لیستهای شیرپوینتی نیاز به دسترسی خاصی دارید باید در قسمت Custom Credentials نام کاربری و رمز عبور آن User مربوطه را وارد کنید.
2- از جعبه ابزار یک کامپننت Data Flow Tasks به پکیج خود اضافه کنید. مجدد از جعبه ابزار SharePoint List Source را درون Data Flow Tasks قرار دهید.

3- انجام تنظیمات مربوط به SharePoint List Source، برای اینکار برروی کامپننت SharePoint List Source دوبار کلیک کرده و مطابق تصاویر زیر عمل نمایید.
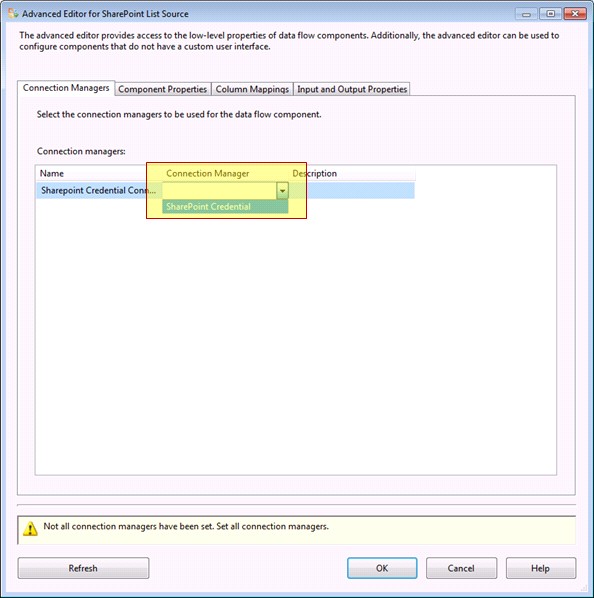
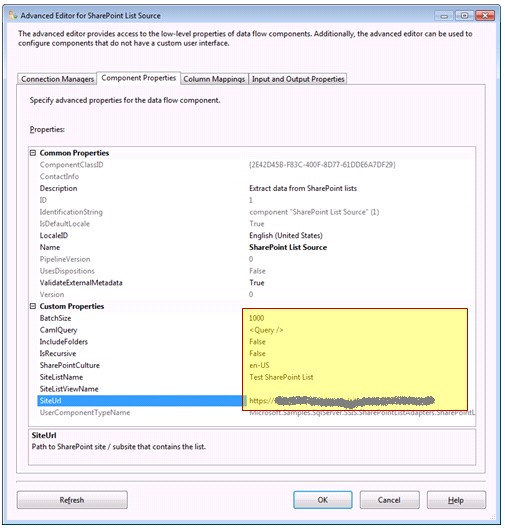
پس از وارد کردن آدرس مربوط به سایت لیست ساخته شده و نام آن در قسمت SiteUrl و SiteListName بر روی Refresh کلیک کنید تا ارتباط با لیست ساخته شده برقرار شود.
در این قسمت تنظیمات دیگری نیز وجود دارد که در مقالهای جداگانه به آنها خواهم پرداخت.
4- در مرحله بعد باید ستونهای مورد نظر خود را انتخاب کنید. برای اینکار به سربرگ Column Mappings بروید تا فیلدهای لیست شیرپوینتی نمایش داده شود. برخی از این فیلدها توسط خود شیرپوینت ساخته میشود. فیلدهایی که قصد دارید آنها را در خروجی داشته باشید را انتخاب کرده و بر روی Ok کلیک کنید.
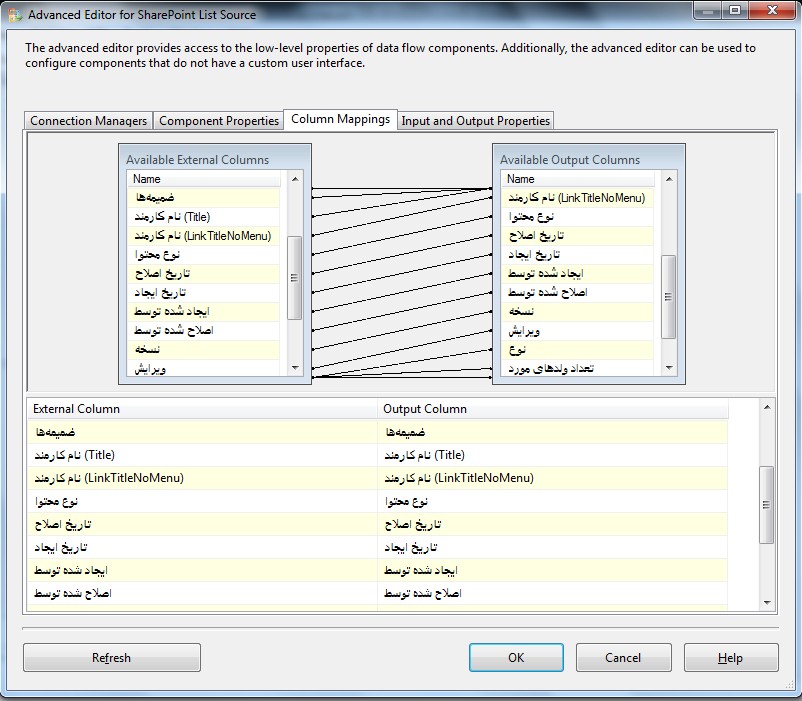
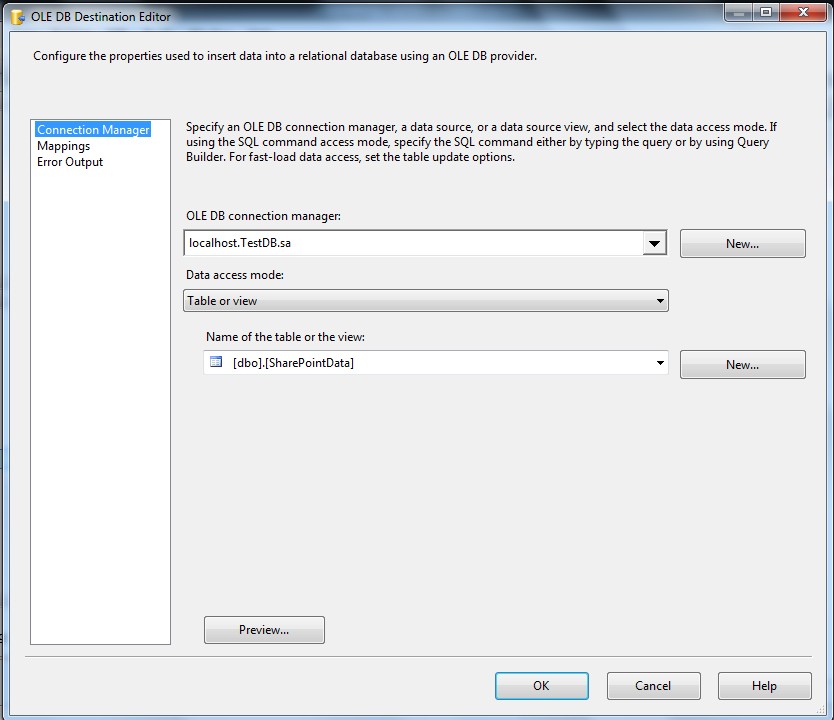
5- از جعبه ابزار یک OLE DB Destination به پکیج اضافه کنید و تنظیمات آن را مطابق تصاویر زیر انجام دهید.
برروی کامپننت OLE DB Destination دوبار کلیک کنید تا صفحه مربوط به تنظیمات آن باز شود. سپس جدولی که پیشتر در SQL ساخته بودید را انتخاب نمایید.
در قسمت Mapping فیلدهای جداول مبدا و مقصد را انتخاب کنید.
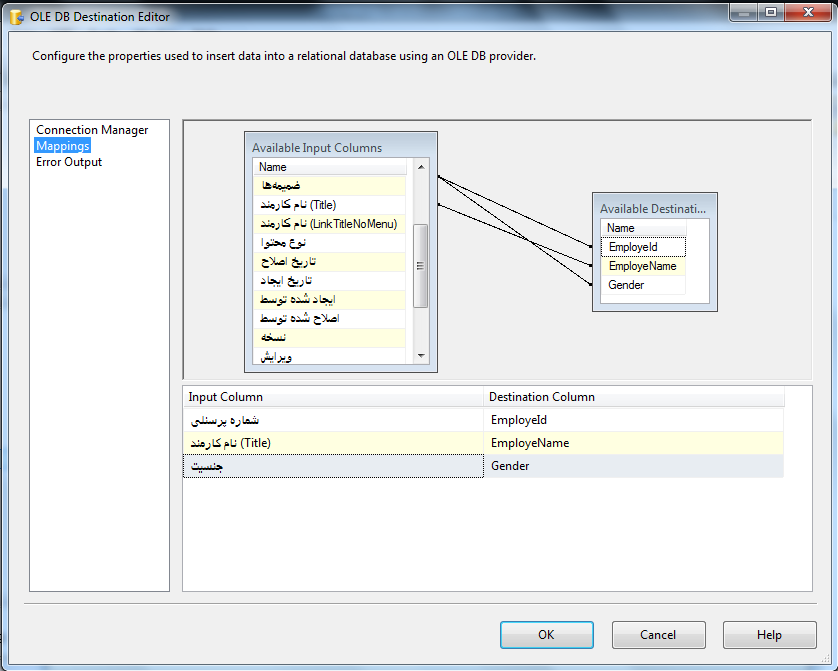
با کلیک برروی Ok کار تمام است و میتوانید پکیج را اجرا کنید.

دسته بندی الگوریتم های داده کاوی
از دادهکاوی برای کاوش در اطلاعات و بدست آوردن دانش استفاده میشود. برای اینکار الگوریتمهای زیادی وجود دارد که هر یک برای هدف خاصی کاربرد دارند. در SQL Server Business Intelligence Development Studioتعداد 9 الگوریتم مختلف برای انجام عمل دادهکاوی وجود دارد که در پنج دسته کلی به شرح زیر تقسیم میشوند.
الگوریتمهای طبقهبندی(Classification algorithms)
در این نوع از الگوریتمها پیش بینی بر اساس یک یا چند متغیر گسسته بر روی سایر ویژگیهای موجود در مجموعه دادهها انجام میشود.
الگوریتمهای رگرسیون(Regression algorithms)
در این نوع از الگوریتمها پیش بینی بر اساس یک یا چند متغیر پیوسته بر روی سایر ویژگیهای موجود در مجموعه دادهها میشوند.
الگوریتمهای دستهبندی(Segmentation algorithms)
این الگوریتمها اطلاعات را به چند گروه یا خوشه تقسیم میکنند. هر گروه ویژگیهای مشابه دارد.
الگوریتمهای وابستگی(Association algorithms)
ارتباط میان ویژگیهای مختلف موجود در مجموعه دادهها از طریق این الگوریتم کشف میشود. از این الگوریتم بیشتر در تجزیه و تحلیل سبد خرید کالا استفاده میشود.
الگوریتمهای تحلیل زنجیرهای(Sequence analysis algorithms)
این نوع الگوریتمها نتیجهی رویدادهای خاص را دنبال میکنند. مانند دنبال کردن رخدادهای آدرس یک سایت اینترنتی.
لازم به ذکر است که تعاریف و دستهبندیهای بالا دلیلی برای محدود کردن استفاده از یک الگوریتم نیست. معمولا در یک تحلیل خوب از یک الگوریتم برای تعیین ورودیهای موثر و از الگوریتمهای دیگر برای بدست آوردن پیش بینیهای مناسب در خروجی استفاده میشود. برای مثال، در یک مدل دادهکاوی میتوانید از الگوریتمهای خوشهبندی، درخت تصمیم و بیز جهت بررسی دادهها از جهات مختلف و کشف دانش استفاده کرد.
SSIS و کاربرد آن در پروژه
شرکت ماکروسافت سرویس SSIS را برای ایجاد راهحلهای مختلف جهت مدیریت و انتقال دادهها فراهم کرده است.
با یک مثال به معرفی بهتر SSIS میپردازم؛ فرض کنید توسط SSAS یک پروژهی بزرگ سازمانی که شامل چندین Cube، Dimension، KPI و ... است، ایجاد کردهاید و از آنجایی که در این پروژه از روش ذخیرهسازی MOLAP استفاده شده، در هر بار به روز رسانی دادهها در انبار داده باید مکعبهای داده و ابعاد نیز پردازش شوند. از طرفی نه درست است و نه منطقی که کاربر نهایی هر روز وارد SSAS شود و Solution را پردازش کند.
بهترین روشی که برای حل این مشکل معرفی میشود، استفاده از SSIS است. در SSIS با ایجاد یک Package و استفاده از کامپننتهای مربوطه این کار به راحتی انجام میشود. کاربرد SSIS تنها برای پردازش Solutionها نیست. در واقع SSIS یک پلتفرم (Platform) سطح بالا برای فراهم کردن راهکارهای مختلف جهت مدیریت و انتقال اطلاعات است. از این سرویس برای کپی کردن یا دانلود فایل، ارسال و دریافت ایمیل، بهروز رسانی انبار داده، پاکسازی و کاوش در دادهها، مدیریت شیءها (Objects) و دادههای SQL استفاده میشود. علاوه بر این SSIS توانایی استخراج (Extract) و تبدیل کردن (Transform) دادهها از فایلهای دادهای XML و منابع داده رابطهای و بارگذاری (Load) در یک یا چند مقصد را دارد.
گرافیکی بودن ابزارها از دیگر مزایای SSIS است. به سادگی میتوان از این ابزارها برای ساخت Package استفاده نمود بدون نیاز به حتی یک خط کد نویسی! البته در صورت نیاز به کد نویسی ابزار و شرایط آن فراهم است.
هر پکیج دارای یک یا چند کامپننت است که میتوانند به تنهایی و یا با ترکیبی از هم اجرا شوند. هر پکیج نیز میتواند به تنهایی یا با هماهنگی با سایر پکیجها اجرا شود.
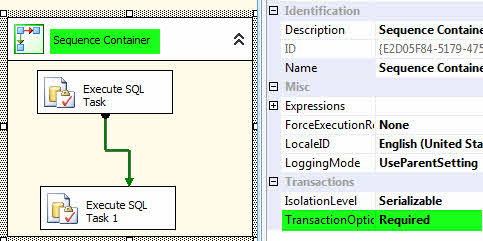
RollBack در SSIS
اگر با Stored Procedures نویسی در SQL آشنا باشید، به خوبی با مفهموم Roll Back و ضرورت استفاده از آن اطلاع دارید. گاهی نیاز به Roll Back در پکیج ضروری است. به این معنا که اگر یکی از کامپننتها با خطا مواجه شد کل عملیات باید لغو شود و همه چیز به حالت اول برگردد. یکی از روشهای انجام اینکار در SSIS استقاده از Sequence Container است. در واقع Sequence Container دسته بندیهای اجرای کامپننتها را بر عهده دارد. کامپننتهای موجود در هر Sequence Container با هم اجرا میشوند و سپس اجرای سایر کامپننتها یا Sequence Containerها انجام میشود.
با این وجود مسئلهی Roll Back همچنان وجود دارد. برای حل این مسئله باید از خصوصیت TransactionOption استفاده کنیم. به صورت پیش فرض این خصوصیت Supported است، آن را به Required تغییر دهید.
کار تمام است! حال در صورتی که یکی از کامپننتهای داخل Sequence Container با خطا مواجه شود تمامی کارهای انجام شده Roll Back شده و به حالت اول باز میگردد.
فرآیند داده کاوی- CRISP
چرخه حیات داده کاوی شامل 6 بخش است. شکل زیر مراحل این فرآیند را نمایش میدهد. در این سیکل حرکت به عقب و جلو امری عادی است. خروجی هر مرحله رابطه مستقیم با انجام وظایف در مرحله بعدی دارد و حرکت فلشها برای وابستگیهای میان مراحل بسیار مهم است.
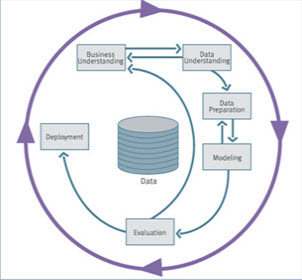
در ادامه هر سیکل را به طور خلاصه شرح میدهم.
درک و فهم موضوع (Business understanding)
اولین مرحلهی این چرخه، تمرکز بر روی هدف و درک نیازمندیها و موضوع پروژه است. تبدیل اطلاعات اولیه به آگاهی و رسیدن به تعریفی مناسب برای حل مسئله دادهکاوی و طراحی برنامه اولیه جهت دسترسی به هدف مورد نظر اولین قدم در یک پروژهی دادهکاوی است. ممکن است گذر از این مرحله ماهها طول بکشد که البته به نوع سازمان نیز بستگی دارد.
درک و فهم دادهها (Data understanding)
این مرحله با جمع آوری دادههای اولیه از منابع داده، بررسی ویژگیها و کیفیت داده، پردازش فعالیتها به منظور آشنایی با دادهها، شناسایی مشکلات و اکتشاف بینش اولیه از دادهها شروع میشود.
آماده سازی دادهها (Data preparation)
مرحله آماده سازی دادهها، تمامی فعالیتها را برای ساخت دادههای خام اولیه به مجموعه دادههای نهایی پوشش میدهد. این فعالیتها شامل پاک سازی، ادغام و قالب بندی دادهها است. از آنجایی که از این دادهها در مراحل بعدی استفاده میشود این مرحله بسیار مهم میباشد.
مدل سازی (Modeling)
در این مرحله تکنیکهای مدل سازی مختلف انتخاب و اعمال میشوند تا پارامترهای آنها به مقادیر مطلوب برسند. پس از انتخاب روش مدل سازی باید یک مدل آزمون ایجاد کنیم تا کیفیت و اعتبار مدل را آزمایش کنیم. در نهایت یک مدل نهایی که به نظر میرسد از لحاظ تجزیه و تحلیل داده دارای کیفیت بالایی است، ساخته میشود.
ارزیابی (Evaluation)
قبل از استقرار نهایی مدل باید مشخص شود که آیا مدل انتخاب شده، ما را به هدفی که در اولین قدم تعیین نموده بودیم میرساند.
گسترش (Deployment)
حتی اگر هدف از ساخت مدل، افزایش دانش باشد، عموماً ساخت یک مدل پایان پروژه نیست. اطلاعات حاصله احتیاج به سازماندهی و ارائه به روشهایی که کاربران نهایی بتوانند از آن استفاده کنند دارد. اغلب به کار بردن مداوم این مدل، در سازماندهی و فرایندِ ساخت تصمیمات مدنظر است.
در هر یک از این مراحل میتوانیم به مرحله قبل برگردیم و با بازنگری به پیشبرد هدف سازمان کمک کنیم. پس از مرحله گسترش نیز میتوانیم از ابتدا مراحل را مورد بررسی قرار داده و در صورت نیاز پروژه را گسترش دهیم.
برگرفته از CRISPWP