هوش تجاری (Business Intelligence)
به اشتراک بگذاریم برای یادگیری، یاد بگیریم برای به اشتراک گذاریهوش تجاری (Business Intelligence)
به اشتراک بگذاریم برای یادگیری، یاد بگیریم برای به اشتراک گذاریسریهای زمانی ماکروسافت(Microsoft Time Series )
الگوریتم سریهای زمانی (Time Series) یک الگوریتم پیش بینی بر جسته است. در واقع ترکیبی از رگرسیون اتوماتیک و تکنیکهای درخت تصمیم میباشد. این الگوریتم را ART (Auto Regression Tree) هم مینامند. به مثال زیر توجه کنید:
فرض کنید که مالک یک فروشگاه هستید و قصد دارید پیش بینی فروش چند هفته آینده را برای هر گروه از محصولات بدانید، تا بتوانید موجودی کالاهایتان را مدیریت نمایید. نمیخواهید موجودی بیشتری در انبار داشته باشید و همچنین کالاها را بیش از اندازه در انبار نگه دارید. از طرفی هم میدانید که در تعطیلات، فروش برخی از کالاها ممکن است افزایش یابد و میخواهید بدانید که چه زمانی و به چه مقدار از هر کدام از این محصولات باید سفارش دهید و در انبار داشته باشید.
الگوریتم سریهای زمانی ماکروسافت به منظور پاسخ به این نوع سوالات طراحی شده است.
معرفی الگوریتم سریهای زمانی
سریهای زمانی شامل یک سری اطلاعات از افزایشهای متوالی در طول زمان یا سایر شاخص های متوالی که در یک دوره زمانی جمع آوری شدهاند؛ می باشد. دنیای پیرامون ما ثابت نیست و متغیرهای بسیاری با تغییر زمان ارزش خود را تغییر میدهند و در نهایت ترتیب ارزشهای یک متغیر در طول زمان یک سری زمانی را تشکیل می دهد.
به عنوان مثال قیمت نهایی سهام ماکروسافت که به صورت روزانه می باشد در یک سری زمانی نمایش داده شده است.
فروش ماهانه شرکت پیسی یک سری زمانی را تشکیل میدهد و همچنین در آمد هر فصل یک شرکت نیز یک سری زمانی است. در سریهای زمانی بیشتر اوقات ارزش و مقدار متعلق به یک زمان، به ارزش در زمان قبل بستگی دارد. .به عنوان مثال قیمت نهایی سهام میکروسافت در 10 می(May) شدیدا به قیمت تمام شده آن در 8 و 9 می بستگی دارد.
مقادیر مشاهده شده در سریهای زمانی ممکن است پیوسته و یا گسسته باشند. ما تنها سریهای زمانیای را که مقادیر آنها پیوسته میباشند را در نظر می گیریم.
ارزش سهام، میزان فروش یک فروشگاه و درآمد شرکت به شکل پیوسته است و یک سری زمانی از پیش بینی وضعیت آب و هوا، مشاهداتی از مقادیر گسستهی، آفتابی، ابری، بادی یا بارانی است.
همانطور که پیشتر گفته شد هدف اصلی از جمع آوری دادههای سری زمانی پیش بینی و یا پیشگویی درباره مقادیر آینده است. به مثالهای زیر توجه کنید:
در یک کارخانه صنعتی به پیش بینی درخواستهای مشتریان در ماههای آینده جهت برنامه ریزی تولید نیاز است.
یک وب سایت باید رشد و ترافیک کاربران را به منظور استفاده از یک سخت افزار مناسب تخمین بزند و همچنین یک فروشگاه خرده فروشی باید فروش محصولات را به منظور بهینه سازی موجودی انبار پیش بینی نماید.
همگام سازی (Synchronize) دو جدول در SSIS
پیشتر مطالبی در مورد روشهای مقایسه رکوردهای دو جدول نوشته بودم. یکی از این روشها استفاده از tablediff است که مطالب مربوط به آن را میتوانید اینجا مشاهده کنید، اما برای انجام آن دو مسئله وجود دارد. اول اینکه پس از ایجاد فایل تغییرات، باید آن فایل را باز کرده و اجرا کنیم و دوم گرفتن خطا توسط SQL در زمان ایجاد مجدد است، چراکه این فایل قبلا ایجاد شده است. البته از چند طریق میتوان این مشکلات را حل کرد.
در این پست قصد دارم به حل این مسئله از طریق ایجاد یک پکیج در SSIS بپردازم.
1- در SSIS یک Package مطابق شکل زیر ایجاد کنید.
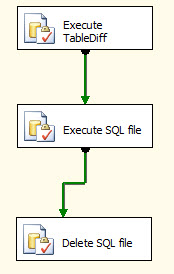
2- قطعه کد زیر را در Execute TableDiff قرار دهید.
exec master..xp_cmdshell'"C:\Program Files\Microsoft SQL Server\100\COM\tablediff.exe" -sourceserver (local) -sourcedatabase Shop -sourcetable A -destinationserver (local) -destinationdatabase Shop -destinationtable B -f C:\Result.sql'
برای اطلاع از سایر پارامترها و ویژگی های Tablediff به اینجا مراجعه کنید.
همانطور که در مطالب مربوط به tablediff گفتم، با اجرای این کوئری رکوردهای دو جدول با هم مقایسه و نتیجهی آن در فایل Result.sql ذخیره میشود.
3- توسط Execute SQL file فایل SQL ایجاد شده در مرحله قبل را اجرا کنید.
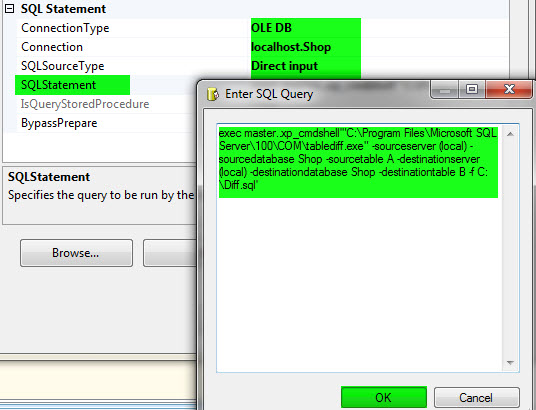
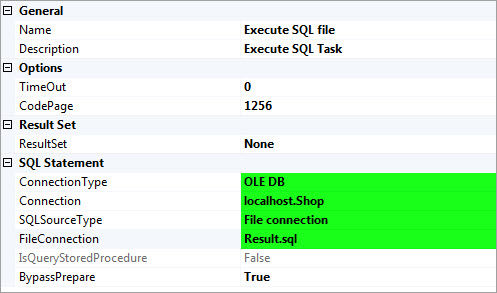
4- برای اینکه در زمان اجرای مجدد پکیج و ایجاد فایل به مشکل بر نخوریم، با استفاده از یک دستور ساده فایل ایجاد شده در مرحله قبل را حذف میکنیم.
xp_cmdshell 'del c:\Result.sql'
کار تمام است! حال هر زمان که اطلاعات موجود در جدول اول تغییر کرد میتوانید پکیج را اجرا کنید و جدول دوم را همانند جدول اول داشته باشید.
OLAP به زبان ساده
OLAP مجموعهای از مکعبها (Cubes) است. داخل این مکعبها دادههایی قرار دارند که از پیش انتخاب شدهاند. ارتباطات بین ابعاد از قبل تعریف شده و همه ابعاد (نتایج) از قبل محاسبه و پیشبینی شده است. هنگامی که یک مکعب ایجاد میشود، یک واسط کاربر نهایی که میتواند یک داشبورد باشد برای یک فرد واقعی پیادهسازی میشود که کاربر نهایی(مدیران و تصمیم گیرندگان سازمان) بتواند با جوابهای داخل مکعب تعامل داشته باشد.
اما فرض کنید در یک مکعب برای تحلیل فروش در یک سازمان مقدار و مبلغ فروش را بر اساس ابعادِ مناطق فروش، فروشنده (بازاریاب)، مشتری و ماه یا سال داشته باشیم. زمانی که این مکعب فرضی ساخته میشود، نرمافزار مبتنی بر OLAP کلیه ترکیبات عناصر دادهها را محاسبه و ذخیره میکند، کاربر نهایی به این دادهها از طریق داشبوردها و یا یک سری فرمها مثلا Pivot Table ها یا انواع دیگر فرمها دسترسی خواهد داشت.
در این مثال فرضی کاربر نهایی محدود به تحلیل در محدوده ابعاد از قبل تعریف شده مثل مناطق، نمایندگیها، مشتریها و ماه است. اگر کاربر بخواهد درباره فروش هفتگی، روزهای هفته یا محصولات فروخته شده (و یا صدها ترکیب دیگر از دادهها) اطلاعاتی کسب کند دیگر شانسی برای بدست آوردن آن ندارد، باید صبر کند که مکعب دیگری از اطلاعات مورد نیاز او ایجاد شود که این یعنی محدودسازی و کاهش بهرهوری و اثربخشی برای تصمیمگیران آن سازمان. به عبارت دیگر کاربر نهایی باید نیازهای خود را از پیش شناخته و برای این نیازها Cubeها، جداول حقایق (Fact) و ابعاد (Dimension) مورد نیاز را پیاده سازی کند تا با کنار هم قرار دادن گزارشات مختلف تا حدودی به دانش استخراج شده و مورد نیاز خود دست پیدا کند.OLAP برخی از قابلیتهای تحلیل را فراهم میکند، اما تقریبا میتوان گفت در کشورهای پیشرفته یک رویکرد قدیمی است و متاسفانه در کشور ما همچنان ناشناخته! یا کمتر شناخته شده است. در حال حاضر انواع مختلف OLAPوجود دارد، مثل MultiDimensiona OLAP (MOLAP) که به آن MMD نیز گفته میشود و Relational OLAP (ROLAP) یاRDBMS و سیستم های OLAP از نوع
HOLAP.
در پست جداگانه به تشریح انواع OLAP و مقایسه آنها میپردازم.
انبار دادههای AdventureWorks
کتابهای آموزشی ماکروسافت در حوزه Business Intelligence، برای طرح مثالهای خود از پایگاه دادههای AdventureWorks استفاده میکند. در واقع AdventureWorks نام سازمانی است که اطلاعات آن در یک انبار داده با همان نام گردآوری شده است. در انبار دادههای AdventureWorks جداول و Viewهایی برای استفاده در پروژههای مختلف BI ایجاد شده است. ممکن است در برخی از مثالها از انبار دادهی AdventureWorks استفاده کنم که لازم است پیشتر آن را نصب کرده باشید.
جهت اضافه کردن پایگاه دادههای AdventureWorks به SQL Server مراحل زیر را انجام دهید.
برای دریافت فایل مورد نظر به اینجا مراجعه کنید.
فایل دانلود شده را از حالت فشرده خارج کنید و AdventureWorks2008R2_SR1 را اجرا نمایید.
بر روی Setup کلیک کنید.
در صفحه SQL Server 2008R2 Database Installer چک باکس I accept the license terms را انتخاب و Next را کلیک کنید.
مطابق شکل زیر، بر روی Install کلیک کنید.
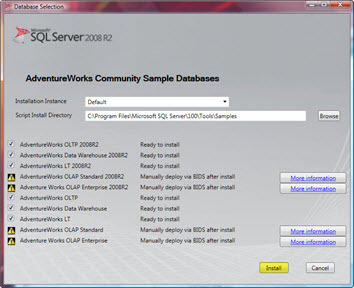
اگر در زمان نصب نرم افزار، آدرس محل نصب را تغییر دادید، باید در این قسمت نیز از همان آدرس استفاده کنید.
پس از پایان نصب بر روی Finish کلیک کنید.
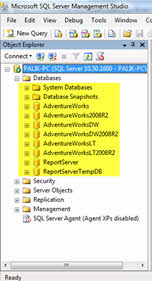
همان طور که در شکل زیر می بینید، انبار داده AdventureWorks2008R2 به همراه چند پایگاه دادهی دیگر بهSQL Server 2008 اضافه شده است.
دسته بندی الگوریتم های داده کاوی
از دادهکاوی برای کاوش در اطلاعات و بدست آوردن دانش استفاده میشود. برای اینکار الگوریتمهای زیادی وجود دارد که هر یک برای هدف خاصی کاربرد دارند. در SQL Server Business Intelligence Development Studioتعداد 9 الگوریتم مختلف برای انجام عمل دادهکاوی وجود دارد که در پنج دسته کلی به شرح زیر تقسیم میشوند.
الگوریتمهای طبقهبندی(Classification algorithms)
در این نوع از الگوریتمها پیش بینی بر اساس یک یا چند متغیر گسسته بر روی سایر ویژگیهای موجود در مجموعه دادهها انجام میشود.
الگوریتمهای رگرسیون(Regression algorithms)
در این نوع از الگوریتمها پیش بینی بر اساس یک یا چند متغیر پیوسته بر روی سایر ویژگیهای موجود در مجموعه دادهها میشوند.
الگوریتمهای دستهبندی(Segmentation algorithms)
این الگوریتمها اطلاعات را به چند گروه یا خوشه تقسیم میکنند. هر گروه ویژگیهای مشابه دارد.
الگوریتمهای وابستگی(Association algorithms)
ارتباط میان ویژگیهای مختلف موجود در مجموعه دادهها از طریق این الگوریتم کشف میشود. از این الگوریتم بیشتر در تجزیه و تحلیل سبد خرید کالا استفاده میشود.
الگوریتمهای تحلیل زنجیرهای(Sequence analysis algorithms)
این نوع الگوریتمها نتیجهی رویدادهای خاص را دنبال میکنند. مانند دنبال کردن رخدادهای آدرس یک سایت اینترنتی.
لازم به ذکر است که تعاریف و دستهبندیهای بالا دلیلی برای محدود کردن استفاده از یک الگوریتم نیست. معمولا در یک تحلیل خوب از یک الگوریتم برای تعیین ورودیهای موثر و از الگوریتمهای دیگر برای بدست آوردن پیش بینیهای مناسب در خروجی استفاده میشود. برای مثال، در یک مدل دادهکاوی میتوانید از الگوریتمهای خوشهبندی، درخت تصمیم و بیز جهت بررسی دادهها از جهات مختلف و کشف دانش استفاده کرد.