هوش تجاری (Business Intelligence)
به اشتراک بگذاریم برای یادگیری، یاد بگیریم برای به اشتراک گذاریهوش تجاری (Business Intelligence)
به اشتراک بگذاریم برای یادگیری، یاد بگیریم برای به اشتراک گذاریCAP Theorem
سیستمهای توزیع شده و تئوری CAP
اطلاعات و منابع زیادی در خصوص مزایای استفاده از سیستمهای توزیع شده وجود دارد اما کمتر به معایب آن پرداخته شده است.
به طور خلاصه، استفاده از دو یا چند سرور جهت استفاده همزمان از یک برنامه به طوری که کاربر نهایی متوجه تغییرات و نحوه ذخیره سازی اطلاعات نشود، سیستم توزیع شده گفته میشود. برنامه ها در سیستمهای توزیع شده از منابع مختلف غیر اشتراکی استفاده میکنند و هر سیستم (سرور) منابع خود را کنترل میکند.
تئوری CAP :
در علوم کامپیوتر و به طور خاص در سیستمهای توزیع شده، تئوری وجود دارد به نام تئوری CAP (که با نام تئوری Brewer هم شناخته می شود) که بر اساس آن برای یک سیستم توزیع شده برآوردن هر سه مورد زیر به طور همزمان غیر ممکن خواهد بود:
Consistency: تمامی گرهها در یک زمان خاص دادههای مشابه دریافت کنند
Availability: دسترس پذیری درخواستها برای همه گرهها
Partition tolerance: از دسترس خارج شدن سامانه در هنگام شکست شبکه
قضیه CAP بیانگر این موضوع است که در سیستمهای توزیع شده شما فقط امکان فراهم کردن دو گزینه از سه گزینه Consistency و Availability و Partition tolerance را خواهید داشت و گزینه باقیمانده، فدای گزینه های دیگر خواهد شد.
هنگامی که Availability و Partition tolerance را انتخاب میکنیم، به معنی آن است که هر درخواستی، پاسخی دریافت خواهد کرد. این پاسخ تا جای ممکن شامل جدیدترین اطلاعات خواهد بود ولی این امکان وجود دارد که قدیمی باشد. از طرف دیگر درج اطلاعات ممکن است که در لحظه امکان نداشته باشد، ولی سیستم به کار خود ادامه میدهد و در نهایت به ثبات خواهد رسید. این انتخاب برای کارهایی که در دسترس بودن سیستم و سرعت آن، نسبت به ثبات و دوام اطلاعات، اولویت بالاتری دارد مناسب میباشد.
موقعی که Consistency و Partition tolerance را انتخاب می کنیم، به معنی آن است که هر درخواستی حتما باید آخرین نسخه از اطلاعات را به عنوان پاسخ دریافت نماید. همچنین اگر دو درخواست یکسان از دو مکان مختلف به سیستم ارسال شود، سیستم باید به هر دو درخواست کننده جواب یکسانی بدهد. در این حالت، با افزایش Consistency زمان تاخیر افزایش، و سرعت پاسخ دهی کاهش می یابد.
پایگاه دادههای رابطهای به دلیل ماهیت و پشتیبانی کردن از ACID (مجموعه خصوصیات دیتابیسهای تراکنشی)، گزینش CA را انجام میدهند.


الگوی طراحی جداول ابعاد- slowly changing dimension
بیشتر اوغات مقادیر موجود در جداول ابعاد (Dimensions) ثابت هستند و تغییری در آنها رخ نمیدهد. به عنوان مثال تغییر در نام ماههای سال تقریبا غیر ممکن است. اما برخی از اطلاعات قابل تغییر هستند، مانند نام یا نام خانوادگی و آدرس افراد.
جهت شرح چنین شرایطی از اصطلاح SCD یا slowly changing dimension استفاده میشود. SCD الگویی جهت طراحی جداول ابعاد است.
در برخی از گزارشات، زمانی که چنین تغییری در داده رخ دهد، میبایست تغییرات را به صورتی اعمال کرد که ردپای (تاریخچه تغییرات) آن مشخص باشد. به طور مثال در نظر بگیرید که در گزارشی میزان فروش شخصی ثبت شده باشد، این شخص پس از مدتی نام خود را تغییر میدهد، اگر نام شخص را بروزرسانی کنیم تمامی اطلاعات قدیمی با نام جدید نمایش داده میشود که در این صورت امکان رسیدن به نام قدیم از بین میرود.
SCD یک مفهموم جدید نیست بلکه نوع دیگری از طراحی میباشد که برای کمک به حل چنین مشکلاتی مفید واقع میشود.
سه نوع طراحی برای SCD وجود دارد.
نوع اول: در این نوع از طراحیSCD نیازی به رهگیری تغییرات نمیباشد. استفاده از حالت نرمال بروزرسانی جداول ابعاد بدون اضافه کردن سطر یا ستون خاصی به جدول جهت رهگیری وضعیت تغییرات در دادهها. گزارش با نام جدید نمایش داده میشود و نام قدیمی نادرست در نظر گرفته خواهد شد. همچنین در نوع اول تاریخچه تغییرات ثبت و رهگیری نمیشود.
نوع دوم: SCD نوع دوم کاملا متفاوت و برعکس نوع اول است. در این نوع تمامی تغییرات بدون اعمال تغییر روی دادهها ثبت و رهگیری میشود. برای انجام این کار سطر و ستونهایی به جدول مورد نظر اضافه میکنیم.
تاریخ شروع و تاریخ پایان به همراه یک کلید اصلی جدید جهت ثبت تاریخچه تغییرات به جدول اضافه میکنیم.
به تصویر زیر دقت کنید، به منظور ثبت تغییرات، جدول سمت چپ به جدول سمت راست تغییر میکند و توسط فرآیند ETL دادهها به شکل نمایش داده شده در جدول پایین درج و بروزرسانی میشوند.


نوع سوم: در این حالت پردازش جهت رهگیری تغییرات تا حدودی ساده شده به طوری که فقط نام فعلی و نام قدیمی به همراه تاریخ تغییر را در جدول ذخیره میکنیم. نام جدید با نام قدیمی جایگزین میشود و نام قدیمی در فیلد دیگری به همراه تاریخ تغییرات ثبت میشود. در نوع سوم SCD سطری اضافه نمیشود و فقط ستونهایی برای درج تاریخ تغییرات و مقدار قبلی افزوده میشود. در صورتی که نیاز به ثبت تاریخچه تمامی تغییرات باشیم، باید ستون های دیگری به جدول اضافه کنیم. از این نوع زمانی استفاده میشود که فقط نیاز به اطلاع از داده قبلی باشد.
حذف سطرهای تکراری یک جدول، بوسیله SSIS Sort Transformation
در SQL Server برای حذف رکوردهای تکراری یک جدول، راه های متعددی وجود دارد که در این پست با استفاده از سرویس SSIS این کار را به راحتی انجام خواهیم داد.
در SSIS وقتی نیاز به مرتب سازی جدول پیدا می کنیم، میتوانیم از کامپوننتی به اسم Sort استفاده کنیم که مانند دستور Order By عمل میکند و میتواند به صورت صعودی و نزولی سطرها را مرتب کند.
ابتدا یک پروژه SSIS ساخته ، سپس در قسمت Solution Explorer روی Connection Managers کلیک راست کرده و گزینه New Connection Manager را انتخاب می کنیم.
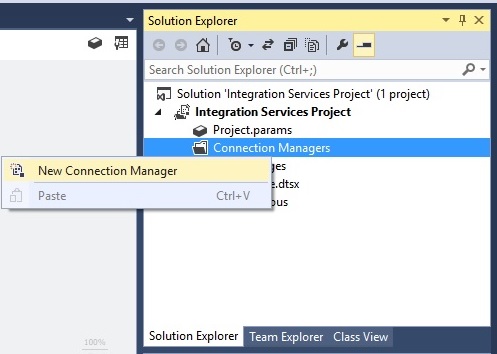
پنجره ای باز میشود به اسم Add SSIS Connection Manager، که در این مثال نوع OLEDB را انتخاب و سپس دکمه Add را میزنیم.
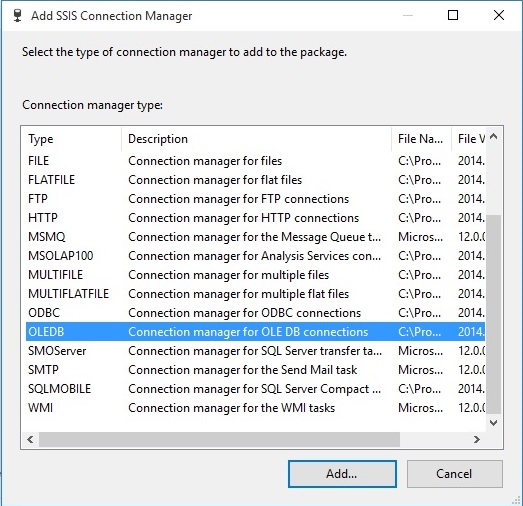
پنجره ای به نام Configure OLEDB Connection Manager ظاهر خواهد شد که با کلیک دکمه New پنجره ای به نام Connection Manager ظاهر خواهد شد. گزینه Server Name و دیتابیس مورد نظر را انتخاب می کنیم.
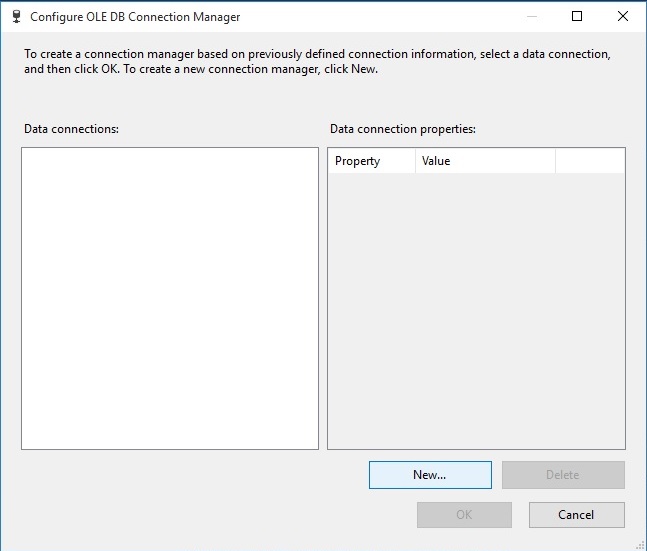
بعد از اطمینان از درستی برقراری کانکشن با کلیک دکمه Test Connection، دکمه OK را کلیک کرده تا به مرحله بعد برویم.
Data Flow Task را از جعبه ابزار به صفحه طراحی منتقل می کنیم.
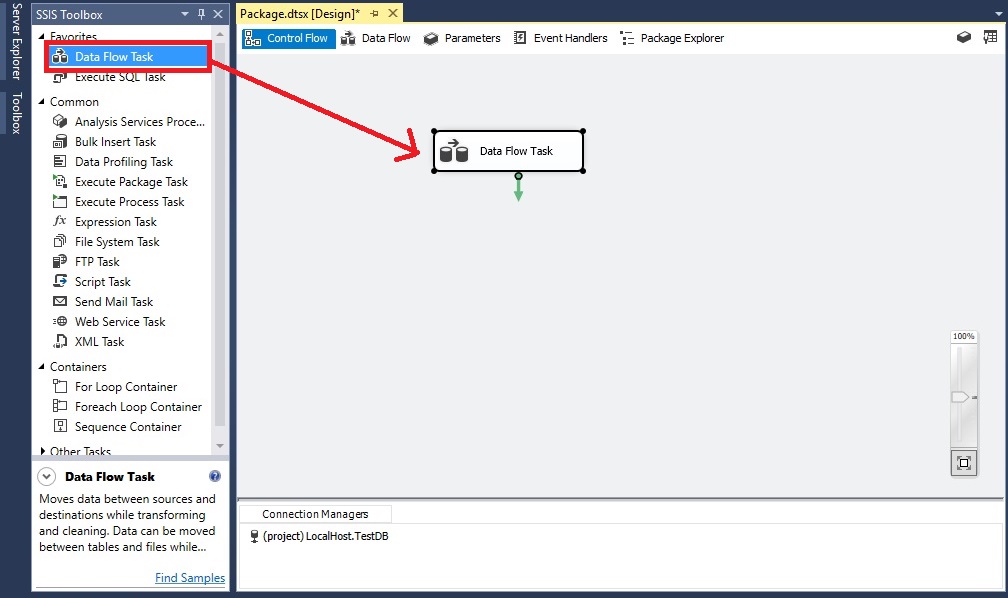
روی Data Flow Task کلیک راست کرده و گزینه Edit را انتخاب می کنیم تا وارد Data Flow Task شویم. سپس OLEDB Source را از جعبه ابزاربه محیط طراحی منتقل می کنیم.
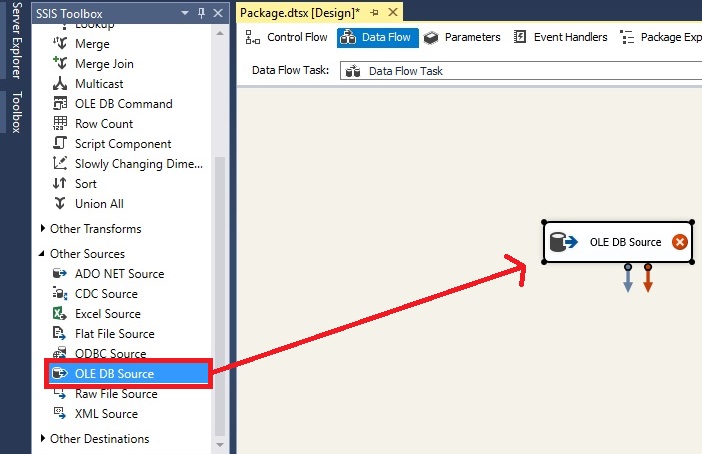
روی OLEDB Source راست کلیک کرده و گزینه Edit را انتخاب می کنیم. پنجره ای با نام OLEDB Source Editor ظاهر خواهد شد. دیتابیس و سپس جدول مورد نظر خود را انتخاب میکنیم.
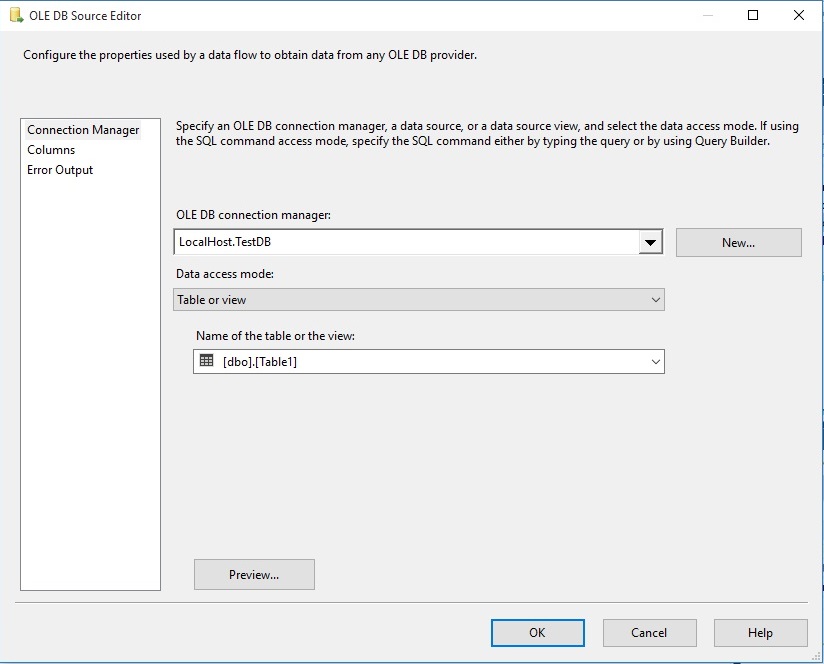
روی دکمه Preview کلیک کرده تا یک پیش نمایش از جدول ببینیم.
در تصویر جدول زیر، رکوردهای تکراری را علامت گذاری کرده ایم.

روی دکمه Close و سپس OK کلیک کرده تا به محیط طراحی برویم.
Sort را از جعبه ابزار به محیط طراحی منتقل کرده و سپس OLEDB Source را به Sort متصل می کنیم.
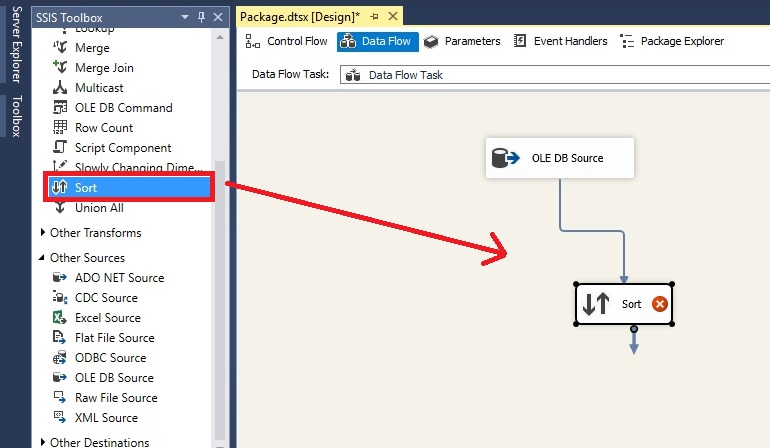
روی کامپوننت Sort کلیک راست کرده و گزینه Edit را انتخاب می کنیم.صفحه یی به نام Sort Transformation Editor باز خواهد شد که با انتخاب هر فیلد، عمل مرتب سازی، بر اساس فیلد انتخاب شده انجام می شود.
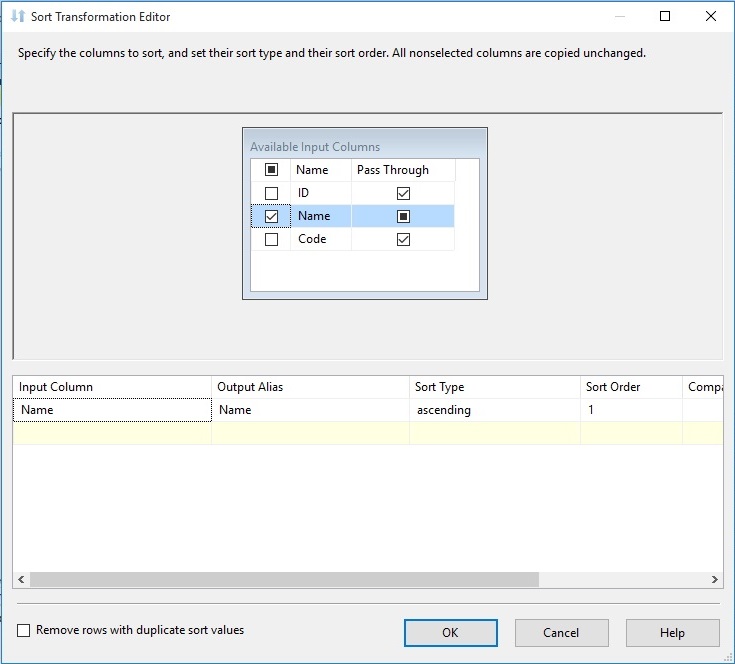
روی دکمه OK کلیک کرده و Derived Column را از جعبه ابزار به محیط طراحی منتقل می کنیم. سپس کامپپوننت Sort را به Derived Column متصل می کنیم.
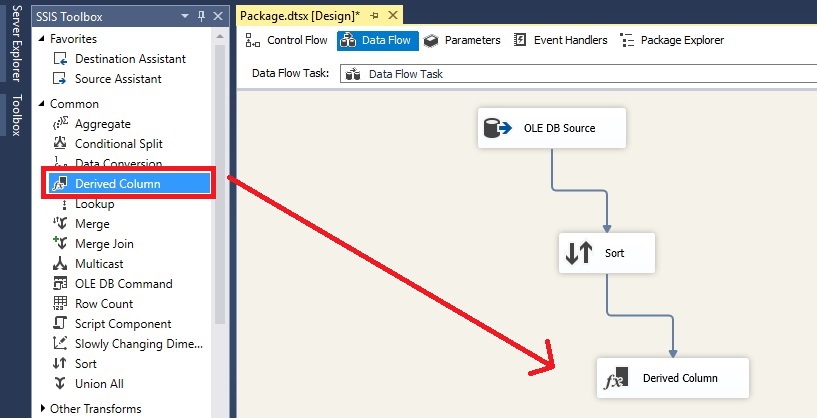
روی متصل کننده ی کامپوننت Sort به کامپوننت Derived Column کلیک راست کرده و گزینه Enable Data Viewer را انتخاب می کنیم تا تعداد رکوردهای منتقل شده راببینیم.
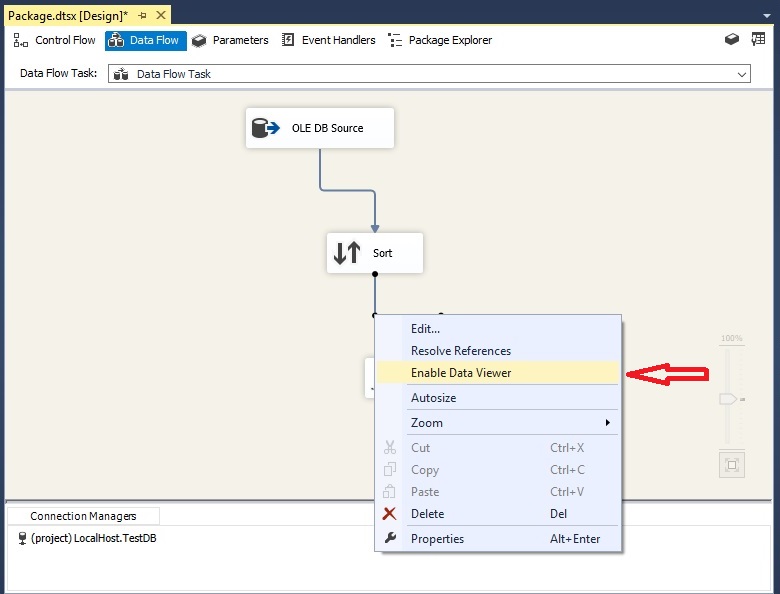
روی دکمه Start که در نوار ابزار است، کلیک کرده تا رکوردهای مرتب شده را ببینیم.

همانطور که می بینید، رکوردهای زیر بر اساس ستون Name مرتب شده اند.
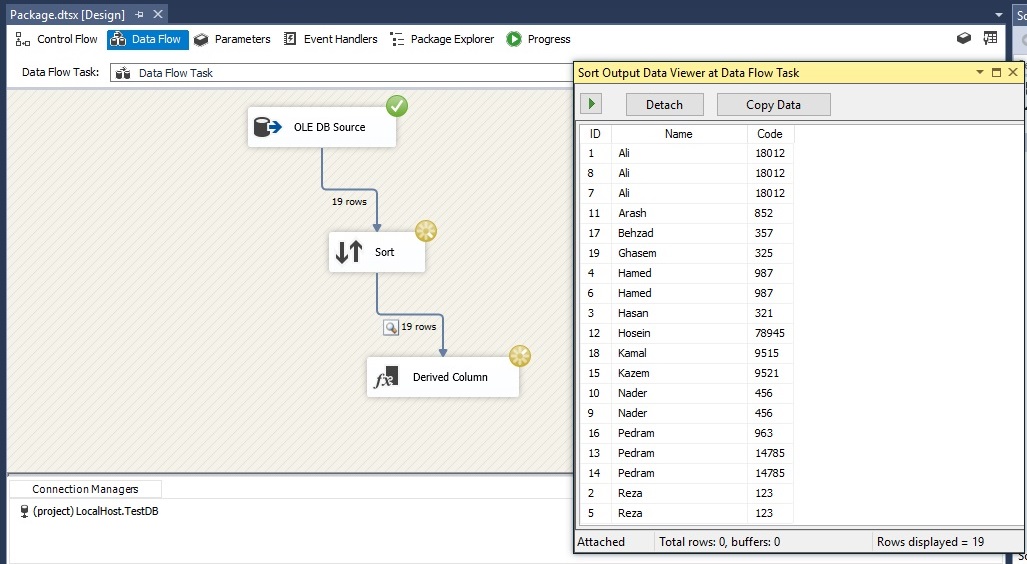
روی دکمه Stop که در نوار ابزار است کلیک کرده و روی کامپوننت Sort کلیک راست کنید و گزینه Edit را زده تا پنجره Sort Transformation Editor مجدد ظاهر شود. سپس Remove Rows With Duplicate Sort Values را انتخاب کرده و روی دکمه OK کلیک می کنیم.
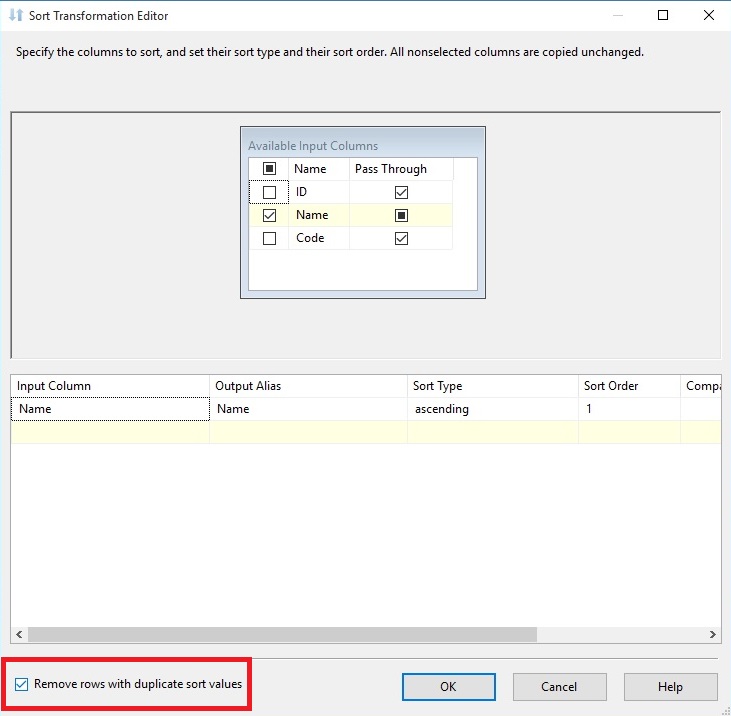
روی دکمه Start کلیک کرده تا نتیجه را ببینیم. همانطور که در تصویر زیر مشخص است، 19 سطر به کامپوننت Sort منتقل، در آنجا مرتب سازی و سپس سطرهای تکراری حذف شده و 12 سطر به مرحله بعد منتقل می شود.
آیا دوران پادشاهی اوراکل در حوزهی مدیریت پایگاههای داده عملیاتی به پایان رسیده است؟
از سال 1970 تا به حال سیستمهای مدیریت پایگاه داده عملیاتی – ODBMS - مختلفی ایجاد شدهاند. بعضی از آنها به مرور زمان از بین رفتهاند و برخی قدرتمندتر شدهاند. در دهههای اخیر بین سیستمهای مدیریت پایگاه داده عملیاتی، محصولات شرکتهای اوراکل، مایکروسافت، IBM و SAP از بقیه موفقتر بودهاند. اما مسلما در این بین بهترین سیستم مدیریت پایگاه داده، محصول شرکت اوراکل بوده است و سخن گزافی نیست که بگوییم محصول شرکت اوراکل در دهههای اخیر در بین محصولات دیگر شرکتها پادشاهی میکرده است .تا حدود 4 سال پیش بین کیفیت oracle db و sql server اختلاف فاحشی وجود داشت. چه از نظر سرعت و چه از نظر دیگر امکانات، اوراکل کاملا برتر از رقیب خود بود. در نسخهی sql server 2012، امکانات قابل توجهی به محصول شرکت مایکروسافت افزوده شد. از مهمترین این امکانات میتوان به ویژگی AlwaysOn و ColumnStore Indexها اشاره کرد. امکانات این نسخه باعث شد که اختلاف بین oracle db و sql server تا حدی کاهش یابد. مایکروسافت سرانجام در نسخهی sql server 2014 خود تغییرات اساسی بوجود آورد. مهمترین این تغییرات ایجاد موتور درونی In-Memory OLTP میباشد که برای تراکنشهای درون حافظه بهینه شده است. با استفاده از امکانات این نسخه میتوان بدون نیاز به دوباره نویسی محصولات، سرعت اجرای کوئریهای آنها را به طور متوسط ده برابر کرد. در شکل ذیل ساختار جدید sql server مشاهده میشود.
عوامل حیاتی در موفقیت سیستمهای هوش تجاری (Critical Success Factors)
اجرای سیستم هوش تجاری یک تعهد پیچیده است که به منابع قابل توجهی نیاز دارد
مقدمه
اخیرا سیستمهای هوش تجاری با اولویت بالایی در فهرست بسیاری از مدیران فناوری اطلاعات قرار گرفته است. [12,11]
طبق نظر رین اشمیت و فرانسیس [22]، سیستم هوش تجاری مجموعه یکپارچه ای از ابزارها، فن آوریها و محصولات برنامه ریزی شده ایست که برای جمع آوری، هماهنگی، تحلیل و در دسترس قرار دادن داده ها استفاده می شوند. بطور ساده می توان گفت وظایف اصلی سیستم هوش تجاری شامل اکتشاف هوشمند، یکپارچه سازی، تجمیع و تحلیل چند بعدی داده های نشات گرفته از منابع مختلف اطلاعاتی است [21]بطور ضمنی در این تعریف دادهها، منابع بسیار با ارزش سازمان در نظر گرفته شده است بطوریکه از کمیت به کیفیت تبدیل می شوند[27] . در نتیجه امکان یکپارچه سازی دادههای حجیم سازمان از منابع دادهای مختلف فراهم میشود و دیدی 360 درجه از کسب و کار ارائه میدهد. [5, 27] بنابراین برای تسهیل بهبود تصمیم گیری، اطلاعات با معنی میتوانند در زمان و مکان مناسب، و به شکل مناسب برای کمک به افراد، بخشها، گروهها و یا حتی واحدهای بزرگتر ارائه شوند.
بر اساس تحقیقهای بسیاری که در مورد CSFها انجام شده، پیاده سازی سیستمهای هوش تجاری پیرو سنت و رسوم پروژههای کاربردی ماننده سیستمهای تراکنشی نیست [10]. اما این نوع پروژهها ویژگیهای مشابهی هم با سیستمهای زیر بنایی همچون ERP ها دارند. پیاده سازی سیستمهای هوش تجاری فعالیتهای سادهای همچون خرید ترکیبی از نرم افزارها و سخت افزارها نمیباشد بلکه یک تعهد پیچیده است که نیاز به زیرساختها و منابع مناسب در طول یک دوره دارد. [10,19,18]
گام اول در CSFها بحث و جستجو
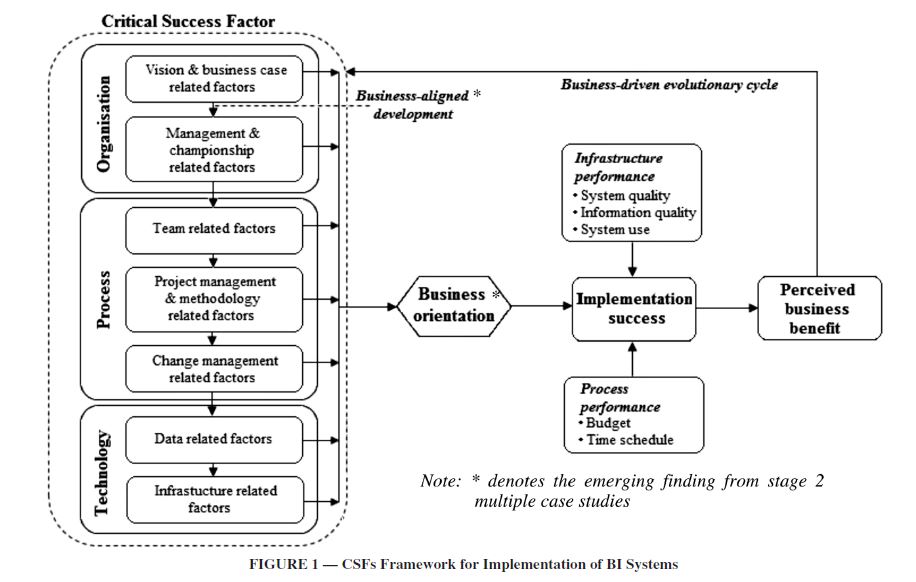
چارچوب CSFها در شکل زیر نشان داده شده و بطور خلاصه تشریح میکند که چطور مجموعهای از عوامل مهم منجر به اجرای موفقیت آمیز سیستم هوش تجاری میشوند. آریاچاندرا و واتسون [2]معیار موفقیت اجرای این تحقیق را در دو بعد کلیدی میبینند: عملکرد فرایند (مانند اینکه فرایند پیاده سازی سیستم هوش تجاری چطور پیش رفت) و عملکرد زیرساخت(بطور مثال کیفیت سیستم و استاندارد خروجی).
عملکرد زیرساخت به سه متغیر عمده موفقیت IS شباهت دارد که توسط دلون و مک لین توصیف شده [7, 8]، یعنی کیفیت سیستم، کیفیت اطلاعات و کاربرد سیستم، در حالیکه عملکرد فرایند میتواند از نظر برنامه زمانی و بودجه ارزیابی شوند. بطور خاص، کیفیت سیستم مرتبط با ویژگی کارایی سیستم پردازش اطلاعات است. یعنی سیستم باید انعطاف پذیر و قابل سنجش باشد و توانایی یکپارچه کردن داده ها را داشته باشد [2, 7, 8]. کیفیت اطلاعات به دقت، کامل بودن، بهنگام بودن، تناسب، انسجام و سودمندی اطلاعات تولید شده توسط سیستم اشاره میکند[2, 7, 8]. کاربرد سیستم به عنوان "میزان استفاده از خروجی یک سیستم اطلاعاتی" تعریف می شود[7, 8]. متعاقبا،کاربران و سازمانها مزایای اجرای سیستم هوش تجاری را ارزیابی می کنند[13].. این برداشت از مزایا قسمتی از زنجیره تکاملی تعاملی کسب و کار در نظر گرفته میشود که برای حمایت بیشتر از نیازهای در حال تحول کسب و کار منجر به بهبود سیستم های هوش تجاری می شود[3,4].
" سیستم تنها زمانی موفق خواهد شد که کاربران کسب و کار به شناسایی و مدل سازی دانش همچنین نظارت و اصلاح داده را بطور مداوم ادامه دهند. [25]"
بطور خلاصه این قائده یکی از عوامل حیاتی موفقیت در اجرای سیستمهای هوش تجاری است و فقدان آنها منجر به شکست سیستم می شود.
بعد سازمانی
حمایت و پشتیبانی مدیریت
حمایت و پشتیبانی مدیریت متعهد بطور گستردهای به عنوان مهمترین عامل پیاده سازی سیستم هوش تجاری بیان شده است. پشتیبانی و حمایت مستمر مدیران کسب و کار، کسب منابع عملیاتی لازم مانند بودجه، مهارتهای انسانی و ملزومات دیگر را آسانتر میسازد.
" حفظ تعهد و پشتیبانی حامی پروژهها در سراسر پروژه-زیرا شرایط میتوانند در طول عمر پروژه تغییر کنند."
اگر بانی یا مدیر پروژه از جانب کسب و کار سازمانی باشد سودمندتر از وقتی است که از واحد IT باشد. بطور مشابه مطالعات واتسون و همکاران[30] هم این مسئله را تائید می کند در واقع بانی باید نیاز جدی به قابلیتهای هوش تجاری را برای هدفی خاص حس کرده باشد.
پیاده سازی سیستم هوش تجاری، عملی ابتکاری برای بهبود تطابق پذیری اطلاعات جهت پشتیبانی تصمیم است [3, 4]. به عنوان مثال مدل بودجه بندی نمونه مبتنی بر تقاضا که برای پیاده سازی سیستمهای تراکنشی است برای سیستم های هوش تجاری که ماهیت تکاملی دارند کاربرد ندارد. سیستم هوش تجاری از طریق فرایند توسعه تکرارشونده، مطابق با الزامات کسب و کار پویا تکامل می یابد[19]. بنابراین شروع هوش تجاری بخصوص برای سازمانهایی در مقیاس بزرگ نیازمند اختصاص منابع و بودجه مناسب از سوی مدیریت ارشد برای غلبه بر مسائل معمول سازمان است. برخلاف سیستمهای مرسوم پردازش تراکنش برخط (OLTP)، چالشهای سازمانی در طول دوره استقرار و در عمل بوجود میآیند، این چالشها در مسائل زیادی مانند پردازش کسب و کار، مالکیت داده، کیفیت داده، نظارت و ساختار سازمانی آشکار میشود. بسیاری از واحدها تمایل به تمرکز بر دستاوردهای تاکتیکی خود دارند و اثرات ناهموار تحمیل شده بر واحدهای کسب و کار دیگر را نادیده می گیرند.
"هوش تجاری تلاش میکند تا موانع موجود در حوزههایی که کار کردن با آنها مشکل است را کاهش دهد. از این رو به موانع غیر فنی زیادی بر خورد میکند. به عنوان مثال مالک یک سیستم تراکنشی مایل است تا تراکنشها به صورت روزانه انجام شوند تا زمانیکه همه آنها تمام شود. این چیزی است که باید مراقبش باشیم."
بنابراین تعهد و درگیر بودن مدیریت ارشد مخصوصا در شکستن موانع تغییر و "ذهنیت" در سازمان ضروری است.
استراتژی مناسب و چشم انداز روشن
از آنجایی که شروع هوش تجاری توسط کسب و کار هدایت میشود چشم انداز استراتژیک کسب و کار باید پیاده سازی را هدایت کند. برای استقرار کسب و کاری یکپارچه در درجه اول چشم اندازی بلند مدت لازم است. کسب و کار باید با چشم انداز استراتژیک هم راستا باشد تا بدین وسیله به اهداف خود دست یابد و نیازهایش را برآورده کند. اگر چشم انداز کسب و کار بطور کامل مشخص نشده باشد در نهایت پذیرش و نتیجه سیستم هوش تجاری را تحت تاثیر قرار می دهد.
اقدامات هوش تجاری باید با استراتژی کلی ترکیب شوند تا پیگیری جدی و حمایت مدیران ارشد سازمان را با خود داشته باشد در غیر این صورت آنها حمایت مدیران ارشد را که برای موفقیت لازم است دریافت نمیکنند. چشم انداز ابزاری است که مدیر ارشد به وسیله آن می تواند به سرعت استراتژی سازمان را شناسایی و درک کند.
دلیل مهم شکست بعضی از پروژه های هوش تجاری، چالشهای فنی نیست بلکه متداولترین دلیل آن همراستا نبودن اقدامات هوش تجاری با چشم انداز کسب و کار است که در نتیجه نه نیازهای کسب و کار و نه رضایت مشتریان را برآورده می کند. داشتن کسب و کاری که به خوبی نهادینه شده برای حفظ تعهد سازمانی به سیستم جدید هوش تجاری، مهم است. اکثر مصاحبه شوندگان این تصور را رد کردند که اگر یک سیستم عالی نهادینه شود مردم از آن استفاده خواهند کرد.
" سیستم هوش تجاریی که توسط کسب و کار هدایت نشده باشد سیستمی شکست خورده است. هوش تجاری مفهومی کسب و کار محور است و مشایعت فناوری اطلاعات برای حل مشکل به ندرت نتیجه خوبی دارد.(منظور مشکل کسب و کار است)"
کسب و کاری یکپارچه که از تحلیل دقیق نیازها منتج می شود احتمال بدست آوردن حمایت مدیریت ارشد را افزایش میدهد.
" به منظور حمایت مدیران ارشد؛ آنها باید درک کنند؛ زمانی که درک کردند به راحتی میتوانند حمایت کنند."
بنابراین کسب و کار اصولی منافع استراتژیک پیشنهادی، منابع، هزینهها و زمان بندی را شناسایی می کند. درک اینکه پیاده سازی هوش تجاری یک پروژه نیست بلکه فرایند است بسیار مهم است .[4] سیستمهای هوش تجاری بطور پویا تکامل مییابند و لزوما محدود و قابل پیش بینی نیستند. به عنوان مثال حجم پایگاه داده تحلیلی در سال اول بهره برداری دو برابر می شود و همچنین تعداد کاربران بطور قابل توجهی افزایش می یابد [22].
بعد فرایندی
پشتیبانی کسب و کار محور و ترکیب متعادل تیم
اکثر مصاحبه شوندهها معتقد بودند که داشتن رهبری مناسب از سوی کسب و کار سازمان برای موفقیت پیاده سازی حیاتی است. اینکه رهبر، شخصی تیزهوش باشد همیشه مهم است چون میتواند چالشهای سازمانی و مسیر تغییر را پیش بینی کند. از همه مهمتر، رهبر مبتنی بر کسب و کار باید سیستم هوش تجاری را از دیدگاههای سازمانی و استراتژیک نگاه کند و نباید در مسائل فنی زیاد متمرکز شود.
"تیم به رهبر نیاز دارد. رهبر کسی است که ابزارها را می شناسد کسب و کار و تکنولوژی را درک می کند و میتواند الزامات کسب و کار را به معماری هوش تجاری(سطح بالا) برای سیستم ترجمه کند."
در واقع، هوش تجاری اغلب چندین واحد عملیاتی را احاطه میکند و دادهها و منابع گستردهای را از این واحدها مطالبه میکند. در این رابطه، وجود رهبر برای اطمینان از مدیریت دقیق چالشهای سازمانی که در طول دوره پروژه بوجود میآیند ضروری است. برخلاف پروژههای سیستم عملیاتی، چنین چالشهایی شامل به رسمیت شناختن ارزش استراتژیک دادههایشان و انعکاس اینکه چطور دادههای آنها با دادههای سیستمهای تراکنشی دیگر تعامل میکنند بسیار مهم است.
بنابراین رهبر باید از همکاری میان واحدهای سازمان و تیم پروژه هوش تجاری اطمینان حاصل کند.
اگرچه پروژههای هوش تجاری اساسا متفاوت از پروژههای OLTP است [22,10] سازمان ها در اکثر پروژههای پیاده سازی سیستمهای اطلاعاتی تمایل دارند به کارکنان حوزه فناوری اطلاعاتشان به عنوان مسئول تکیه کنند. تیم پروژه باید قوی و پایدار باشد که بتوانند با نیازهای در حال ظهور و در حال تغییر سازگار شود و برای این کار به تیمی با اعضای شایسته نیاز است.
مصاحبه شوندگان بر این عقیده بودند که ترکیب تیم هوش تجاری باید از بهترین متخصصین حوزه کسب و کار و فنی تشکیل شود. نوآوری هوش تجاری اساسا پروژهای مبتنی بر کسب و کار است و برای تصمیم گیری های استراتژیک ضروری است.
ازدیدگاه فنی، پروژه هوش تجاری قابل مقایسه با پروژه یکپارچه سازی سیستمها است و نیاز به مشارکت فعال متخصصان فنی سازمان دارد[19]. بطور نمونه تیم پروژه با سیستم عاملهای متنوع، پایگاه دادههای متفاوت، رابطهای چندگانه، اتصال به سیستم های قدیمی، مجموعه ای از ابزار، و غیره سر و کار دارد همه این کارها به افرادی با مهارتهای مختلف نیاز دارد. بنابراین کلید موفقیت، ترکیب مناسبی از متخصصان فنی و کسب و کار است.
بیشتر متخصصان توصیه میکنند برای فعالیتهایی مانند استاندارد سازی داده، تحلیل پیش نیازها، تحلیل کیفیت و صحت اطلاعات، تیم هوش تجاری شامل متخصصان حوزه کسب و کار باشند. این موضوع باعث میشود طراحی سیستم توسط کسب و کار هدایت شود و تضمین میکند که نیازهای هوش تجاری، به خوبی هدایت کننده معماری منطقی دادهها باشد.
رویکرد توسعه تکرارشونده و مبتنی بر کسب و کار
برنامه ریزی و هدف گذاری پروژه مبتنی بر کسب و کار اجازه می دهد که تیم هوش تجاری به بهترین فرصتها برای بهبود تمرکز کنند. هدف گذاری به انتخاب پارامترهای روشن کمک می کند و درک مشترکی از اینکه چه چیزی در محدوده است و چه چیزی باید حذف شود را در میان همه ذینفعان کسب و کار ایجاد میکند. [1]
"موفقیت نود درصد پروژه ماقبل از روز اول تعیین می شود. این موفقیت بر پایه داشتن محدودهای روشن و مشخص، داشتن انتظارات و جدول زمانی واقع گرایانه و بودجه مناسب از پیش مشخص شده، است"
هدف گذاری و برنامه ریزی، انعطاف پذیری و سازگاری با شرایط متغیر در چارچوب زمانی را تسهیل میکند. علاوه بر آن، هدف گذاری مناسب، تیم پروژه را قادر می سازد که برنقاط عطف ضروری و مسائل مربوط تمرکز کنند و همزمان محافظی برای جلوگیری از قرار گرفتن در وقایع غیرضروری است.
"محدوده باید کنترل شود زیرا "جهش محدوده" می تواند باعث نرسیدن به هدف شود. این بدان معنی نیست که شما نمی توانید عمل یا فرایند کنترل تغییر در مکان داشته باشید بلکه شکلی از کنترل است. پروژه های زیادی بخاطر جهش محدوده، توزیعشان به خطا رفته و هزینه داشتهاند."
متخصصان زیادی توصیه میکنند که با تغییرات و تحولات کوچک شروع کنید و سپس توزیع افزایشی (تدریجی) که رویکردی بنام "تعاملی" ست را اتخاذ کنیم. تلاشهایی که برای تغییرات در مقیاس بزرگ انجام میشود همیشه مملو از ریسکهای بزرگتری با توجه به متغیرهای اساسی که بطور همزمان اداره می شوند، است. [1] علاوه بر آن کسب و کارهای مدرن خیلی سریع تغییر میکنند و همیشه بدنبال شناسایی تاثیرات فوری تغییرات هستند. بنابراین رویکرد توزیع افزایشی احتیاط آمیزتر است و ابزارهایی برای تحویل در زمان کوتاه و گامهای قابل اندازه گیری را فراهم می کند. علاوه بر آن رویکرد توزیع افزایشی اجازه ساخت راه حلی بلند مدت در تضاد با اصطلاح کوتاه مدت را می دهد [1, 4].
" رویکرد توزیع افزایشی ریسک را مدیریت میکند، نتایج ملموس قابل مشاهده برای مشتری را فراهم می کند توانایی بدست آوردن مالکیت مشتری را بهبود می بخشد، انتقال دانش را تسهیل میکند و راه حلی بلند مدت منظور میکند."
بنابراین محدوده ابتکار هوش تجاری باید در چنان مسیری انتخاب شود که در زمانی معقول سیستمی کامل برای بخش خاصی از کسب و کار بتواند تحویل داده شود به جای راه حل "بزرگ و عظیم و کامل" در زمان دیرتر. هنگامیکه کاربران کار با راه حل هوش تجاری را آغاز کردند بطور کامل متوجه پتانسیل گزارش دهی و امکانات تجزیه و تحلیل می شوند بعد از آن سیستم هوش تجاری اولیه با رویکرد تکاملی و تکرارشونده افزایش و توسعه می یابد.
امکان پیاده سازی یکدفعه تمام سیستم هوش تجاری امکانپذیر نیست در حالی که کاربران میخواهند بخشهای کلیدی را مشاهده کنند. به منظور راضی نگه داشتن ذینفعان و نمایش تعداد کمی از گزارشات کلیدی باید انبار داده را برای چند حوزه کلیدی بر پا نمود. سپس وقتی اولین نسخه انجام شد و تعدادی بازخورد بدست آمد، میتوانید روی انبار داده حوزه های دیگر کار کنید و به مرور زمان، سایر حوزهها را توسعه دهید.
بنابراین، رویکرد توزیع افزایشی (تدریجی) به سازمان اجازه می دهد که روی مسائل حیاتی تمرکز کند و تیمها را برای اثبات عملی و سازنده بودن پیاده سازی سیستم برای سازمان تایید کند.
مدیریت تغییر کاربر گرا
درک بهتر کاربر می تواند منجر به انتقال بهتر نیازهایشان شود که به نوبه خود به اطمینان از معرفی موفقیت آمیز سیستم کمک میکند و می تواند در پاسخگویی به مطالبات و انتظارات مختلف کاربران نهایی کمک کند. بی شک، کاربران نیازهایشان را بهتر از یک معمار یا توسعه دهندهای که فاقد تجربه مستقیم است، میشناسند.
" کاربران باید شریک مهمی در ساخت و تحویل سیستم باشند. بدون ورودی مداومشان، نمی توانیم سیستم درستی ارائه دهیم.
بنابراین نمیتوان برای دستیابی به نیازهای کاربران، تیم پروژه ای را طراحی و سیستم هوش تجاری را پیاده سازی کرد اما آنها را مشارکت نداد."
آشکار است که کاربران کلیدی باید در سراسر چرخه پیاده سازی درگیر باشند چون آنها می توانند ورودیهای ارزشمندی را ارائه دهند که در غیر اینصورت تیم هوش تجاری ممکن است نادیده بگیرد. ابعاد دادهها، قوانین کسب و کار، متا دیتا و چارچوب داده که لازم است توسط کاربران کسب و کار در سیستم ثبت شوند و در مقابل اقلام قابل تحویل، تائید شوند. [29] در نتیجه، پشتیبانی کاربر بطور مداوم در پاسخ به نیازمندیهای کسب و کار مکمل کاربردهای هوش تجاری و سبب تکامل است. [10]
بعد تکنیکی
چارچوب فنی انعطاف پذیر و مقیاس پذیر، مبتنی بر کسب و کار
چارچوب فنی سیستم هوش تجاری باید قادر به تطبیق مقیاس پذیری و انعطاف پذیری ملزومات در راستای نیازهای پویای کسب و کار باشد. طراحی زیرساخت انعطاف پذیر و مقیاس پذیر اجازه توسعه آسان سیستم برای هم راستایی با نیازهای اطلاعاتی در حال تحول را می دهد[21]. بنابراین دید استراتژیک مستتر در طراحی چارچوب سیستم مقیاس پذیر می تواند شامل منابع داده اضافی، ویژگیها و ابعاد برای تحلیلهای مبتنی بر واقعیت شود و میتواند دادههای اضافی تامین کنندگان، پیمانکاران، نهادهای نظارتی و معیارهای صنعتی را ترکیب کند. در نتیجه اجازه ساخت راه حل بلند مدت برای پاسخگویی به نیازهای فزاینده کسب و کار را میدهد.
"مقیاس پذیری همیشه برای من نگران گننده است. به نظر میرسد بیشترین برنامه ها و سیستم های هوش تجاری همیشه بیشتر از حد مورد انتظار بزرگ میشوند یا توانشان بیشتر از حد پیش بینی شده است. اگر طراحی قابل تنظیم یا انعطاف پذیر نباشد ایجاد تغییر برای سازگاری با افزایش مقیاس مشکل است."
در واقع زیر سازی در هوش تجاری برای همه کارها اساسی است و تا لایه فنی برای تمام محیط هوش تجاری شامل استقرار سخت افزار و نرم افزار جدید، قابلیت همکاری میان سیستمهای قدیمی و محیط هوش تجاری جدید در یک شبکه، پایگاه داده، زیرسیستم مدیریت و غیره می شود. [19] ایجاد زیرساخت فنی برای راه حل هوش تجاری اولیه همیشه زمان بر است. [29]اما با انتخاب درست اجزای نرم افزار و سخت افزار انعطاف پذیر و قابل تنظیم، تلاش برای چرخه بعدی می تواند به حداقل برسد. در نتیجه سیستم میتواند خود را با ملزومات در حال ظهور و همیشه در حال تغییر کسب و کار تطبیق دهد.
یکپارچگی و کیفیت دادههای پایدار
کیفیت داده نقشی حیاتی در استقرار موفق سیستم هوش تجاری ایفا میکند. هدف اولیه سیستم هوش تجاری یکپارچه کردن سیلوهای داده برای تجزیه و تحلیل پیشرفته است تا بهبود فرآیند تصمیم گیری. اغلب دادههای مرتبط زیادی در پشت سیستم جمع میشوند اما تا زمان استفاده در سیستم هوش تجاری کشف نمی شوند. [31] بنابراین کیفیت داده در منبع، بر روی کیفیت گزارشات مدیریت اثر میگذارد که آن هم به نوبه خود نتایج تصمیمات را تحت تاثیر قرار می دهد [9]. اطلاعات شرکت تنها زمانی میتوانند بطور کامل و کارا در عرصه تجاری گسترده مورد استفاده قرار بگیرند که یکپارچگی و کیفیت آنها تائید شود.
و باید توجه داشت که بدون داده های با کیفیت، هوش تجاری هوشمند نیست
پی نوشت: این مقاله ترجمهای از تحقیقی است که توسط WILLIAM YEOH و ANDY KORONIOS در دانشگاه استرالیا انجام گرفته.
با تشکر فراوان از خانم باقرزاده
[1] Ang, J. & Teo, T. S. H. “Management Issues in Data
Warehousing: Insights from the Housing and Development
Board,” Journal of Decision Support Systems, 29(1), 2000,
11-20.
[2] Ariyachandra, T. & Watson, H. “Which Data Warehouse
Architecture Is Most Successful?” Business Intelligence
Journal, 11(1), 2006.
[3] Arnott, D. “Decision Support Systems Evolution:
Framework, Case Study and Research Agenda,” European
Journal of Information Systems, 13(4), 2004, 247-259.
[4] Arnott, D. & Pervan, G. “A Critical Analysis of Decision
Support Systems Research,” Journal of Information Technology,
20(2), 2005, 67-87.
[5] Bose, R. “Advanced Analytics: Opportunities and
Challenges,” Industrial Management & Data Systems,
109(2), 2009, 155-172.
[7] Delone, W., & McLean, E. “Information Systems Success:
The Quest for the Dependent Variable,” Journal of
Information System Research, 3(1), 1992, 60-95.
[8] Delone, W., & McLean, E. “The DeLone and McLean Model
of Information Systems Success: A Ten-Year Update,”
Journal of Management Information Systems, 19(4), 2003,
9-30.
[10] Fuchs, G. “The Vital BI Maintenance Process”, in Business
Intelligence Implementation: Issues and Perspectives,” In
B. Sujatha (Ed), ICFAI University Press, Hyderabad, 2006,
116-123.
[11] Gartner Research, “Gartner EXP Worldwide Survey of
1,500 CIOs Shows 85 Percent of CIOs Expect ‘Significant
Change’ Over Next Three Years,” 2008. Retrieved 21 Feb
2009, from http://www.gartner.com/it/page.jsp?id=587309
[12] Gartner Research, “Gartner EXP Worldwide Survey of
More than 1,500 CIOs Shows IT Spending to Be Flat in
2009”, 2009. Retrieved 21 Feb 2009, from http://www.
gartner.com/it/page.jsp?id=855612
[13] Hwang, M. & Xu, H. “A Structural Model of Data
Warehousing Success,” Journal of Computer Information
Systems, Fall 2008, 48-56
[19] Moss, L. & Atre, S. Business Intelligence Roadmap: The
Complete Lifecycle for Decision-Support Applications.
Addison-Wesley, Boston, MA. 2003.
[21] Olszak, C & Ziemba, E. “Approach to Building and
Implementing Business Intelligence Systems,” Interdisciplinary
Journal of Information, Knowledge, and Management,
2, 2007, 135-148.
[22] Reinschmidt, J. & Francoise, A. Business Intelligence
Certification Guide, IBM International Technical Support
Organization, San Jose, CA, 2000.
[25] Turban, E., Sharda, R., Aronson, J. & King, D. Business
Intelligence, Prentice Hall, New Jersey, 2007.
[27] Wang, H. & Wang S. “A Knowledge Management Approach
to Data Mining Process for Business Intelligence,” Industrial
Management & Data Systems, 108(5), 2008, 622-634.
[28] Watson, H., Abraham, D., Chen, D. “Data Warehousing
ROI: Justifying and Assessing a Data Warehouse,” Business
Intelligence Journal, 2004, 6-17.
[30] Watson, H., Annino, D. A., Wixom, B. H. “Current Practices
in Data Warehousing,” Journal of Information Systems
Management, 18(1), 2001, 1-9.